







MySQL发展路线图:
MySQL体系结构
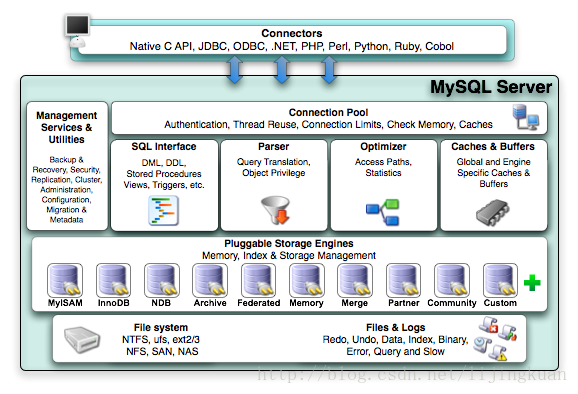
InnoDB体系架构图
总体架构图:
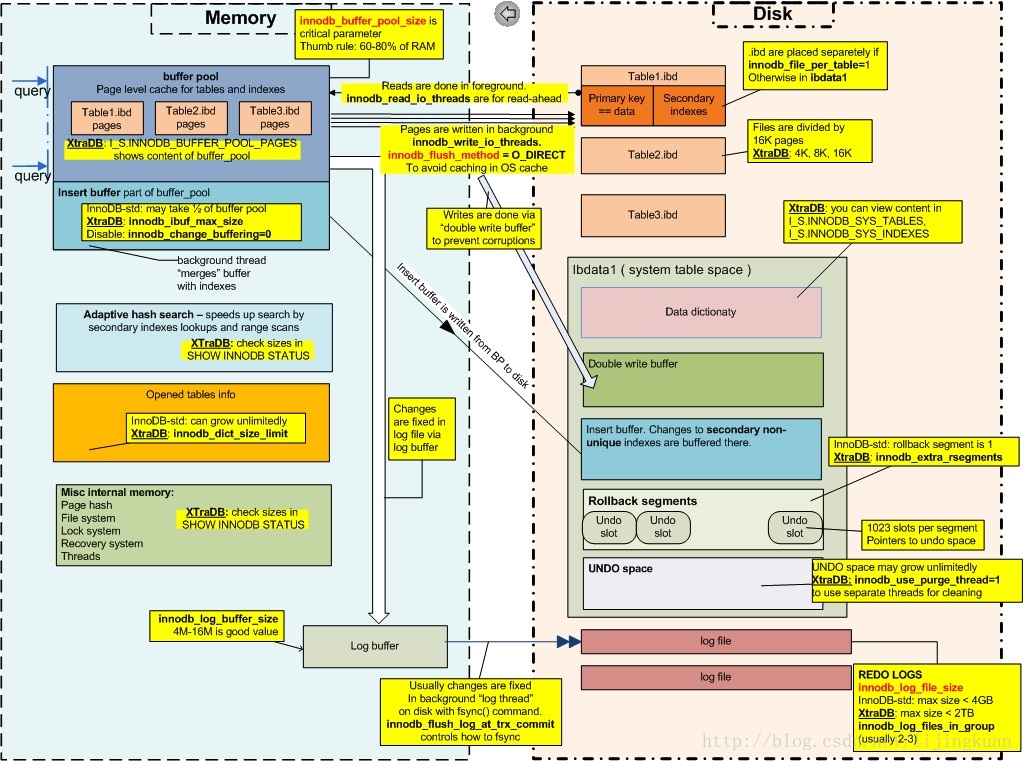
存储结构:
表空间
- 所有的数据都需要存储在表空间中
- 表空间分类
- 系统表空间(ibdata1)
- 独立表空间(innodb_file_per_table)
- undo tablespace,MySQL5.6+
- temporary tablespace,MySQL5.7+
- general tablespace,MySQL5.7+(类似于oracle的)
问:数据库创建后,还能创建undo 表空间不?
答:目前不能,undo表空间是在数据库初始化的时候创建的。
问:undo有默认的过期时间吗?
答:undo没有默认的过期时间。等这个事务提交完以后,没有更多的事务需要这份undo log的时候,它就可以被清除。也就是MVCC里面没有事务再需要这份旧的undo log的时候,就可以purge掉;
系统表空间
- 总是必须的
- 文件名ibdata1
- innodb_data_file_path定义路径、初始化大小、自动扩展策略
- 主要存储对象
- data dictionary
- double write buffer
- insert buffer/change buffer
- rollback segments
- undo space(新版本可以独立出去)
- foreign key constraint system tables
- user data,if innodb_file_per_table=0
建议大小:
innodb_data_file_path = ibdata1:1G:autoextend
除去占用空间最大的undo space之后,剩下的就很小了,不需要太大空间。
独立表空间
- 设置innodb_file_per_tables = 1
- 每个table都有各自的xx.ibd文件
- rollback segments,double write buffer等仍然存放在共享表空间文件里
- 主要存储聚集索引B+树以及其他普通索引数据
日志文件
- undo log
- redo log
Innodb是聚集索引组织表
- 基于B+树
- 数据以聚集索引逻辑顺序存储
- 聚集索引有限选择显示定义的主键
- 其次选择第一个非null的唯一索引
- 再次使用隐藏的rowid
- 聚集索引叶子节点存储整行数据
- 普通索引同时存储主键索引键值
- 所有的索引都由两个segment组成
- leaf page segment
- non-leaf page segment
表空间
- 独立表空间优势
- 表空间可更方便回收
- 透明表空间文件迁移
- 共享表空间优势
- 删除大表或删除大量数据时开销更小,drop table/truncate table
- 可以使用裸设备,据称性能可能有提升。
表空间管理
- 消除碎片
- alter table xx engine=innodb;
- 或者optimize table xx;
- 尽量用pt-osc来操作
- 回收表空间
- 独立表空间:alter table xx engine = innodb;
- 共享表空间:重新导入导出
- 尽量用pt-osc来操作
- 表空间文件迁移
- 目标服务器上:alter table xx discard tablespace;
- 源服务器上:flush table xx for export,备份过去,修改权限
- 目标服务器上:alter table xx import tablespace;
- 表结构务必一致
- innodb_page_size也要一致
问:如何看innodb表的碎片?
答:show table status like ‘tab_name’,看data_length+index_length 然后看idb文件,对比大小。
问:有表 查是400M 物理文件9G,原因是什么?
答:各种大字段 varchar(4000)啊 text什么的。。。
表空间文件迁移步骤:(5.6以后)
1.在目标实例上创建一张和源实例表结构相同的表(表名可以不同)。
2.在目标实例上将表空间discard。 删除旧表空间文件。
alter table xx discard tablespace(执行完这个命令之后,ibd文件就没有了,只剩frm文件了)
3.在源实例上执行FLUSH TABLE xx FOR EXPORT。(执行完这个命令之后,表可以读取,但无法修改,metadata lock。目录下多了个.cfg文件)
将文件cp到目标实例上。并且修改文件权限。
4.在目标实例上执行import tablespace。源实例上unlock tables。
alter table xx import tablespace。
问:表空间迁移到目标实例后,有数据,但是数据行数、大小统计不到了。。。
答:anaylze table
通用表空间(general tablespace)(现在用的不多)
- 5.7+
- 类似oracle的做法
- 多个table放在同一个表空间中
- 可以定义多个通用表空间,并且分别放在不同的磁盘上
- 可以减少metadata的存储开销
- 和系统表空间类似,已分配占有的表空间无法收缩归还给操作系统(全部需重建)
临时表空间,temporary tablespace
- 5.7+
- 独立表空间文件ibtmp1,默认12MB
- 实例关闭后,文件也会删除
- 实例启动后,文件新创建
- 无需参与crash recovery,因此也不记录redo log
- 不支持压缩
- 由innodb_temp_data_file_path定义
问:排序会用到临时表空间吗?
答:不会,只有create temporary table xxx;这种才会用到。
通用临时表会用到。内部临时表不会用到。
select * from x order by y; 由于没有索引,产生的排序临时表,称为内部临时表,如果session内存排序空间不足,会放到internal_tmp_disk_storage_engine指定的问题,磁盘临时文件。
create temporary table xxx; 通用临时表
undo表空间,undo tablespace
- 5.6+独立的undo表空间
- 存储事务中的旧数据
- innodb_undo_logs设置undo表空间个数
- 系统表空间总是需要1个undo表空间
- 临时表空间总是需要32个undo表空间(5.7+)
- 因此,undo表空间总是必须大于33个,并且循环轮流使用
- 可以被在线truncate(5.7+)
- 当所有的undo加起来超过innodb_max_undo_log_size时,会触发truncate工作
- purge 执行innodb_purge_rseg_truncate_frequency次后,也会触发truncate工作(默认128次)
- 建议使用独立undo表空间
innodb是聚集索引组织表
- 基于B+树
- 数据以聚集索引逻辑顺序存储
- 聚集索引优先选择显示定义的主键
- 其次选择第一个非null的唯一索引
- 再次使用隐藏的rowid
- 聚集索引叶子节点存储整行数据
- 普通索引同时存储主键索引键值
- 所有的索引都由2个segment组成
- leaf page segment
- non-leaf page segment
存储结构
tablespace -> segment -> extent(64个page,1M) -> page
- page,页
- 最小IO单位,16kB,5.6版本起可以自定义page size
- 每个page最少存储两行记录(因为是B+tree结构,是双向链表。因此必须存储至少两行记录,才能前后互相连接起来。)
- extent,区
- 空间管理单位
- 每个extent总是1MB,由64个page组成
- 如果page size是8kB的话,则由128个page组成
- segment,段
- 对象单位,例如rollback seg,undo seg,data seg,index seg等
- 每个segment由N个extent以及32个零散page组成
- segment最小以extent为单位扩展
- tablespace,表空间
- 表存储对象
- 每个tablespace都至少包含2个segment(叶子/非叶子 page file segment)
问:每个page至少两行记录,那如果是空表,怎么办?
答:每个page都至少有两个虚拟记录,这两个虚拟记录指向的是虚拟最小记录和虚拟最大记录,确保了每个page至少存储两行记录。infimum, supermum
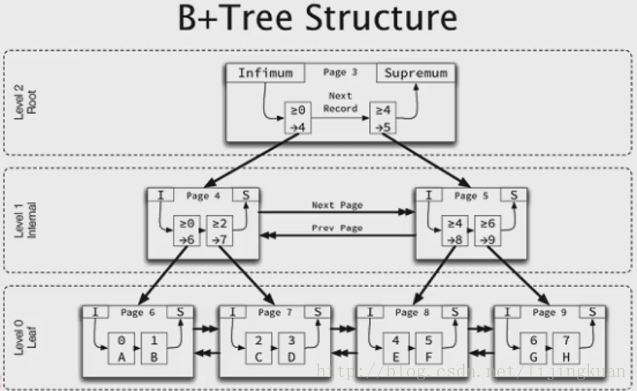
innodb主键
- 最好是自增属性,INT/BIGINT最佳
- 数据类型长度小,性能更佳
- 数据顺序写入也是顺序的,不会离散
- 也更有利于将更多普通索引放到buffer page中
- 主键尽量不要更新,否则更新主键时,辅助索引也要跟着更新。(想想为啥?辅助索引记录主键值)
row,行记录
- row-format
- redundant,最早的行格式
- compat,5.0.3以后的默认行格式
- dynamic,将长字段完全off-page存储
- compressed,将data,index pages进行压缩,但buffer pool中的page则不压缩。压缩比约1/2,但tps能下降到原来的1/10,不建议使用。
- 查看行格式:select * from I_S.innodb_sys_tables where name like ‘%tab_name%’;
- 行溢出,overflow
- 行记录长度大约超过page一半时,一次将最长的列拆分到多个page存储,知道不在超过page的一般为止。
- 溢出的列放在一个page中不够的话,还会继续放在新的page中
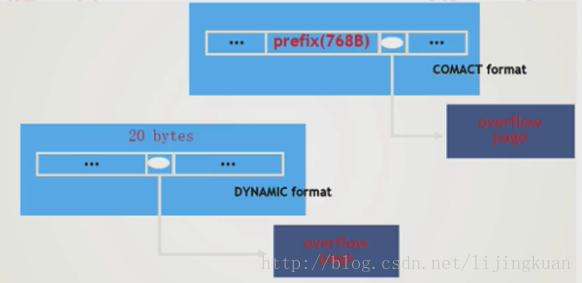
- compat格式下,溢出的列只存储前768个字节
- dynamic格式下,溢出的列只存储前20个字节(指针)
- select * 会同时读取这些溢出的列,因此代价很高
- 出现filesort或temporary table时,一般都无法放在内存中,需要变成disk tmp table,IO代价更高。
- 每row中至少存储几个基本信息
- DB_ROW_ID,6byte,指向对应行记录,每次写新数据该ID自增,如果已有显示声明的主键,则不需要存储DB_ROW_ID
- DB_TRX_ID,6byte,每个事务的唯一标识符
- DB_ROLL_PTR,7bytes,指向undo的回滚指针
- 用于实现MVCC
注意:现在默认的数据文件类型已经是Barracuda了,不是Antelope了,两种最大区别是对于超长列的存储。Antelope前768个字节存储在行里,Barracuda只存储20个字节的指针。(只针对单行长度超过page大小一半的时候,才会overflow page,并不是只要出现blob或者text就一定会overflow的,单行长度不超过page大小一半,即使行中有blob列,也不overflow page)
内存管理
- innodb buffer pool一般设置物理内存的50%-70%(5.7可以在线调整)
- 设置太大可能导致SWAP
- 使用多个buffer pool instance降低并发内存争用(一般建议每个instance管理8-16G内存)
- page采用hash算法分配到多个instance中读写
- 每个缓冲区池管理自己的数据
- innodb_buffer_pool_instances
- 每个instance管理自己的free list,flush list,LRU list及其他,并由各自的buffer pool mutex负责并发控制
可以在线修改buffer pool size
在启动时预装入buffer pool
- innodb_buffer_pool_load_at_startup
- innodb_buffer_pool_dump_at_shutdown
- 设置buffer pool刷新机制
- innodb_flush_method = O_DIRECT(绕过操作系统缓存,直接写阵列卡)
- buffer pool管理
- LRU机制
- 两个列表,young ,old
- 优先放在young队列
- 超过innodb_old_blocks_time后移入old队列
- old队列默认占比innodb_old_blocks_pct = 37
提问:在主从复制中,一张表若是除了一个非唯一的二级索引外并无其他索引,为什么根据二级索引的索引列来更新,也需要校验整行记录的值,并且所有的值一致才能正常在slave上重放? 不是根据二级索引,得到一个内部的隐藏rowid就可以进行更新了吗?
答:因为同一行的rowid在主从上不一定一致。
为什么ROW格式日志一定要用主键定位记录,如果用二级索引行不行?虽然没有主键那么精准,但至少可以避免全表扫描。
根据主键做的更新,不会校验行数据。















 2571
2571

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









