









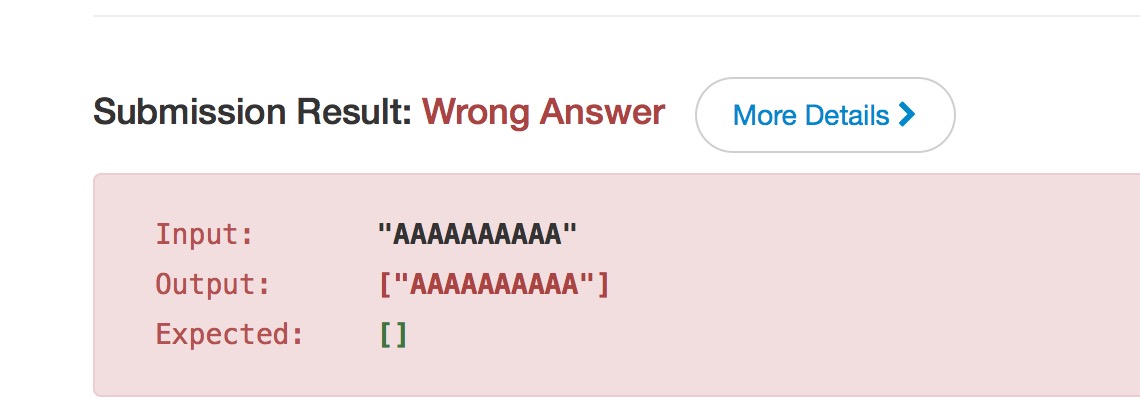
Total Accepted: 2932 Total Submissions: 16668
All DNA is composed of a series of nucleotides abbreviated as A, C, G, and T, for example: “ACGAATTCCG”. When studying DNA, it is sometimes useful to identify repeated sequences within the DNA.
Write a function to find all the 10-letter-long sequences (substrings) that occur more than once in a DNA molecule.
For example,
Given s = “AAAAACCCCCAAAAACCCCCCAAAAAGGGTTT”,Return:[“AAAAACCCCC”, “CCCCCAAAAA”].
第一次答案
public static List<String> findRepeatedDnaSequences(String s) {
int len = s.length();
int temp = 0;
String Str_result = "";
List<String> result = new ArrayList<String>();
for (int i = 0; i < len; i++) {
for (int j = i + 10; j < len; j++) {
while (s.charAt(i) == s.charAt(j) && temp < 10) {
Str_result += s.charAt(i);
i++;
j++;
temp++;
}
if (temp == 10) {
result.add(Str_result);
System.out.println(Str_result);
}
Str_result = "";
i -= temp;
j -= temp;
temp = 0;
}
}
return result;
}就知道这个+10是个隐患。
我有一个疑惑,就是重复的序列可不可以相互包含。也就是DNA序列是不是得大于20至少。加个判断试一下。
if (len < 20) {
return result;
}应该是不可以包含的。那么报下标溢出。应该是while这里没有检测的问题
int len = s.length();
int temp = 0;
String Str_result = "";
List<String> result = new ArrayList<String>();
if (len < 20) {
return result;
}
for (int i = 0; i < len; i++) {
for (int j = i + 10; j < len; j++) {
while ( i < len&& j<len&&s.charAt(i) == s.charAt(j) && temp < 10) {
Str_result += s.charAt(i);
i++;
j++;
temp++;
}
if (temp == 10) {
result.add(Str_result);
System.out.println(Str_result);
}
Str_result = "";
i -= temp;
j -= temp;
temp = 0;
}
}
return result;加上之后,是时间超时,也就是算法复杂度过高。再想一下
到此确定 第二个循环里j=i+1;
刚才试了一个几百个字母的序列。。一分钟 还没算完==。
DNA的序列只有4个字母。上面这个算法是可以算所有字母的。我想可以根据这个关键点来简化算法。
查找的话是不是hash快一点。比如每十个数算一个HashCode。可是这样还是要算n方次。
试试。
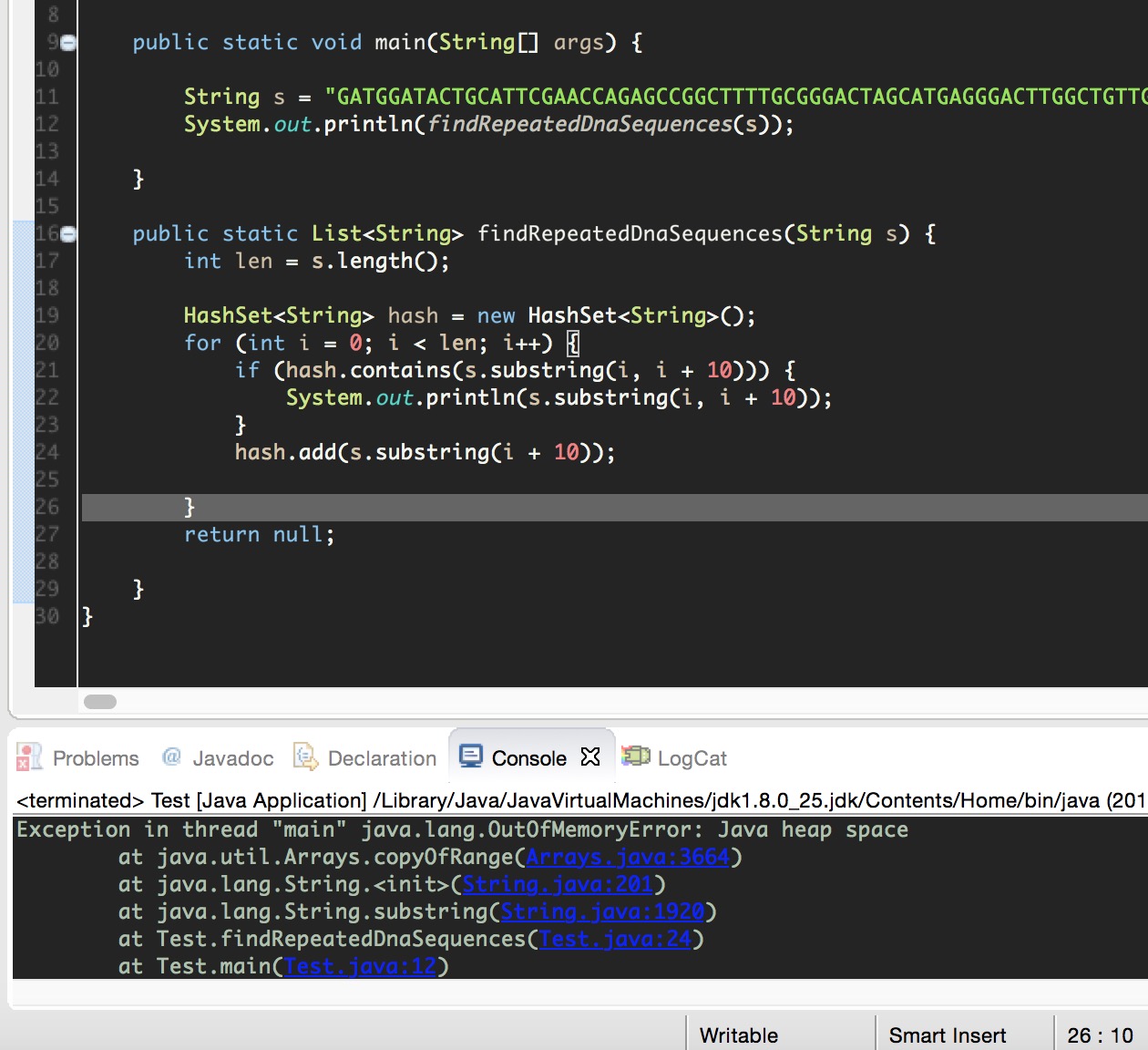
直播溢出了。。
空间换时间换的太狠了。。
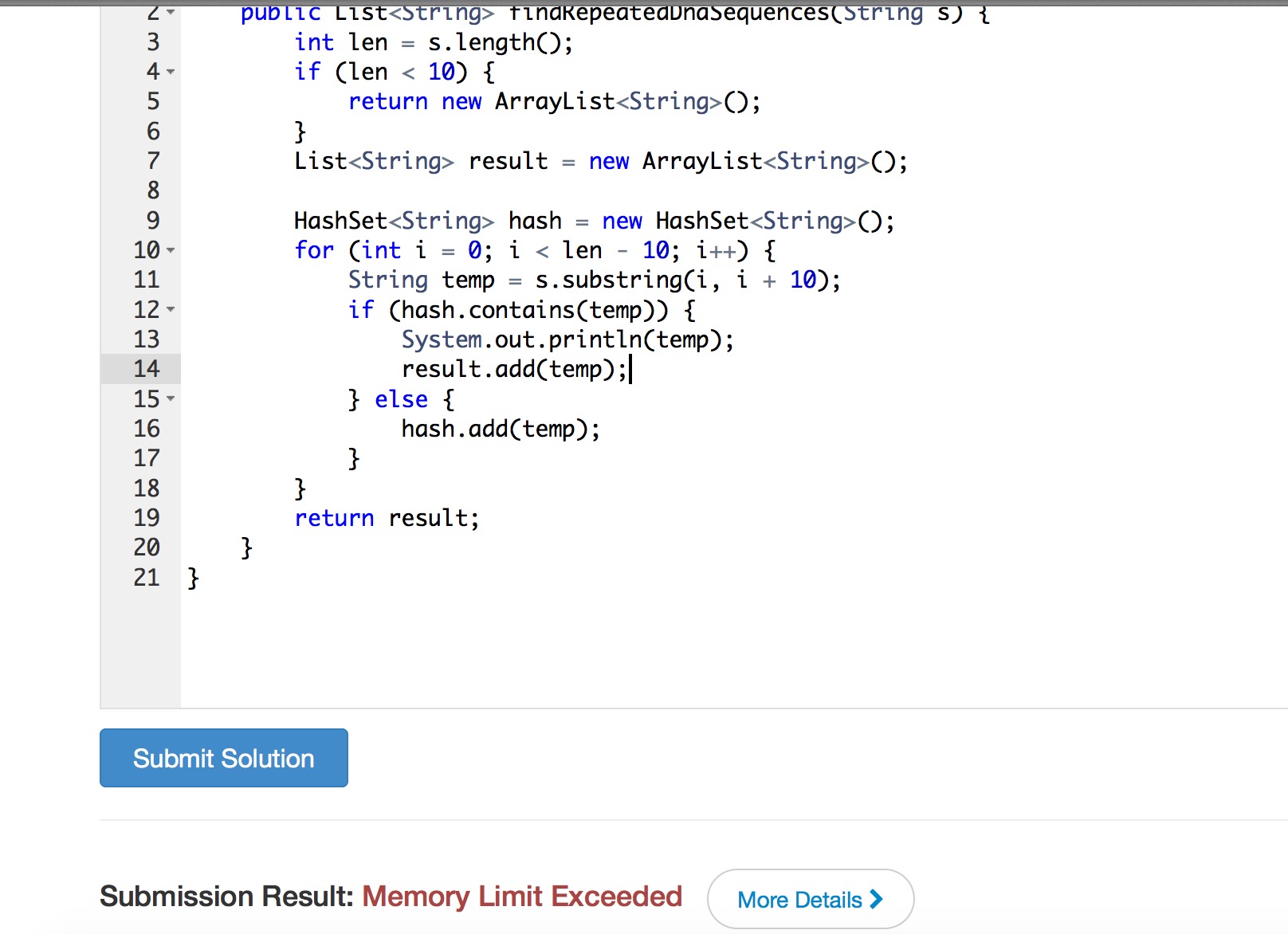
改进版
public static List<String> findRepeatedDnaSequences(String s) {
int len = s.length();
if (len < 10) {
return new ArrayList<String>();
}
List<String> result = new ArrayList<String>();
HashSet<String> hash = new HashSet<String>();
for (int i = 0; i < len - 10; i++) {
String temp = s.substring(i, i + 10);
if (hash.contains(temp)) {
System.out.println(temp);
result.add(temp);
} else {
hash.add(temp);
}
}
return result;
}我的eclipse上是没事。。可是
如果用位图法需要Int 4的len次方长的数组。
可是又不会全部出现 。那么要按顺序存储的话。查找是个问题。
关键在于。如何制作一个足够小的位图。可以快速查找。
因为是最大为3,所以假设采用3进制 。可出现的最大数是3333333333,比起2147483647要大。
那么现在的问题关键又压缩到了一个。如何创建一个唯一的hashcode。
public class Solution {
public List<String> findRepeatedDnaSequences(String s) {
int len = s.length();
if (len < 10) {
return new ArrayList<String>();
}
HashSet<Integer> hash = new HashSet<Integer>();
List<String> cache = new ArrayList<String>();
List<String> result = new ArrayList<String>();
for (int i = 0; i < len - 9; i++) {
String temp = s.substring(i, i + 10);
if (!cache.contains(temp) && hash.contains(getCode(temp))) {
result.add(temp);
cache.add(temp);
} else {
hash.add(getCode(temp));
}
}
return result;
}
static int getCode(String s) {
int result = 0;
for (int i = 0; i < s.length(); i++) {
char c = s.charAt(i);
if (c == 'A') {
result += 1;
} else if (c == 'C') {
result += 2;
} else if (c == 'G') {
result += 3;
} else {
result += 4;
}
result = result << 2;
}
return result;
}
}至于最后
为什么是左移两位。是因为一共有4种。2进制下是11。反正3位也是可以的。但是不能是1位。1位的时候计算的时间特别长。第二
为什么用hashset。因为hashset省内存啊。。用hashmap就会oof。
为什么要转化成整数 。因为整数的hashcode就是自身的值。所以就不用计算了。















 73
73

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









