






监控体系
zabbix
监控对象:
1. 监控对象的理解:CPU是怎么工作的,原理
2. 监控对象的指标:CPU使用率 CPU负载 CPU个数 上下文切换
3. 确定性能基准线:怎么样才算故障?CPU负载多上才算高
监控范围:
1.硬件监控服务器的硬件故障
2.操作系统监控 CPU、内存、硬盘、IO、进程
3.应用服务监控 nginx、MySQL、等服务
4.业务监控
硬件监控:
1.使用IPMI
2.机房巡检
远程控制卡:
DELL服务器:iDRAC
HP服务器:ILO ————-Linux就可以使用IPMI(依赖于BMC控制器)
IBM服务器:IMM |
Linux是管理IPMI工具
ipmitool(监控和控制)
1.硬件要支持
2.操作系统 Linux IPMI
ipmitool安装:
[root@localhost ~]# yum install OpenIPMI ipmitool -y[root@localhost ~]# rpm -qa OpenIPMI ipmitoolipmitool-1.8.13-8.el7_1.x86_64OpenIPMI-2.0.19-11.el7.x86_64
使用IPMI有两种方式
1、本地进行调用
2、远程调用 (IP地址 用户名和密码)
[root@localhost ~]# systemctl start ipmi #启动本次以Centos7进行演示
IPMI相关命令
[root@localhost ~]# ipmitool --helpipmitool: invalid option -- '-'ipmitool version 1.8.13usage: ipmitool [options...] <command>-h This help-V Show version information-v Verbose (can use multiple times)-c Display output in comma separated format-d N Specify a /dev/ipmiN device to use (default=0)-I intf Interface to use-H hostname Remote host name for LAN interface-p port Remote RMCP port [default=623]-U username Remote session username-f file Read remote session password from file-z size Change Size of Communication Channel (OEM)-S sdr Use local file for remote SDR cache-D tty:b[:s] Specify the serial device, baud rate to useand, optionally, specify that interface is the system one-a Prompt for remote password-Y Prompt for the Kg key for IPMIv2 authentication-e char Set SOL escape character-C ciphersuite Cipher suite to be used by lanplus interface-k key Use Kg key for IPMIv2 authentication-y hex_key Use hexadecimal-encoded Kg key for IPMIv2 authentication-L level Remote session privilege level [default=ADMINISTRATOR]Append a '+' to use name/privilege lookup in RAKP1-A authtype Force use of auth type NONE, PASSWORD, MD2, MD5 or OEM-P password Remote session password-E Read password from IPMI_PASSWORD environment variable-K Read kgkey from IPMI_KGKEY environment variable-m address Set local IPMB address-b channel Set destination channel for bridged request-t address Bridge request to remote target address-B channel Set transit channel for bridged request (dual bridge)-T address Set transit address for bridge request (dual bridge)-l lun Set destination lun for raw commands-o oemtype Setup for OEM (use 'list' to see available OEM types)-O seloem Use file for OEM SEL event descriptions-N seconds Specify timeout for lan [default=2] / lanplus [default=1] interface-R retry Set the number of retries for lan/lanplus interface [default=4]Interfaces:open Linux OpenIPMI Interface [default]imb Intel IMB Interfacelan IPMI v1.5 LAN Interfacelanplus IPMI v2.0 RMCP+ LAN Interfaceserial-terminal Serial Interface, Terminal Modeserial-basic Serial Interface, Basic ModeCommands:raw Send a RAW IPMI request and print responsei2c Send an I2C Master Write-Read command and print responsespd Print SPD info from remote I2C devicelan Configure LAN Channelschassis Get chassis status and set power statepower Shortcut to chassis power commandsevent Send pre-defined events to MCmc Management Controller status and global enablessdr Print Sensor Data Repository entries and readingssensor Print detailed sensor informationfru Print built-in FRU and scan SDR for FRU locatorsgendev Read/Write Device associated with Generic Device locators sdrsel Print System Event Log (SEL)pef Configure Platform Event Filtering (PEF)sol Configure and connect IPMIv2.0 Serial-over-LANtsol Configure and connect with Tyan IPMIv1.5 Serial-over-LANisol Configure IPMIv1.5 Serial-over-LANuser Configure Management Controller userschannel Configure Management Controller channelssession Print session informationdcmi Data Center Management Interfacesunoem OEM Commands for Sun serverskontronoem OEM Commands for Kontron devicespicmg Run a PICMG/ATCA extended cmdfwum Update IPMC using Kontron OEM Firmware Update Managerfirewall Configure Firmware Firewalldelloem OEM Commands for Dell systemsshell Launch interactive IPMI shellexec Run list of commands from fileset Set runtime variable for shell and exechpm Update HPM components using PICMG HPM.1 fileekanalyzer run FRU-Ekeying analyzer using FRU filesime Update Intel Manageability Engine Firmware
IPMI配置网络,有两种方式:
ipmi over lan(大体意思是通过网卡来进行连接)
独立 (给服务器单独插一个网线) DELL服务器可以在小面板中设置ipmi 云主机我们不需要考虑IPMI
对于路由器和交换机:SNMP(简单网络管理协议) 监控
配置SNMP:(监控我们可以参考监控宝来讲进行监控)
[root@localhost ~]# yum -y install net-snmp net-snmp-utils[root@localhost ~]# rpm -qa net-snmp net-snmp-utilsnet-snmp-5.7.2-24.el7_2.1.x86_64net-snmp-utils-5.7.2-24.el7_2.1.x86_64#如果不知道要安装什么软件包,可以使用yum list|grep snmp
SNMP配置文件路径
[root@localhost ~]# ll /etc/snmp/total 24-rw------- 1 root root 18861 May 12 09:14 snmpd.conf-rw------- 1 root root 220 May 12 09:14 snmptrapd.conf
为了安全性,我们将配置文件移动并修改
[root@localhost snmp]# mv snmpd.conf snmpd.conf.org[root@localhost snmp]# vim snmpd.confrocommunity abcdocker 192.168.56.11#第二个为团体名,IP是要监控的服务端
我们被采集的服务器要开启snmp
#提示 被采集服务器要允许snmp访问
iptables设置如下:iptables -I INPUT -p udp -s 192.168.56.11 --dport 161 -j ACCEPTiptables -I INPUT -p udp -s [要采集的IP地址] --dport 161 -j ACCEPT
开启服务
[root@localhost snmp]# systemctl start snmpd[root@localhost snmp]# netstat -lntup #snmp默认监听的是udp161端口Active Internet connections (only servers)Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program nametcp 0 0 0.0.0.0:22 0.0.0.0:* LISTEN 1062/sshdtcp 0 0 127.0.0.1:25 0.0.0.0:* LISTEN 2208/mastertcp 0 0 127.0.0.1:199 0.0.0.0:* LISTEN 2692/snmpdtcp6 0 0 :::22 :::* LISTEN 1062/sshdtcp6 0 0 ::1:25 :::* LISTEN 2208/masterudp 0 0 0.0.0.0:69 0.0.0.0:* 1130/xinetdudp 0 0 0.0.0.0:161 0.0.0.0:* 2692/snmpd
SNMP相关知识
snmp原理图
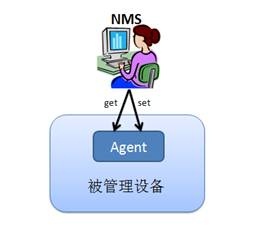
什么是 MIB?
MIB 是描述被管理设备上的参数的数据结构。如前所述,管理一个设备,就是利用 SNMP 协议,通过网络对被管理设备上的参数进行 get 和 set 操作。
那么如何组织被管理设备上的参数呢?多数情况下,可以 get 和 set 的参数实在多得惊人,假如仅仅简单地线性罗列它们,操作会十分不便。想象一下把 1000 个参数列成一张表,需要使用的时候查询这样一张表会有多么困难啊?比如您打算在地球上找一个城市,”Ithaca”,如果没有归类和分级,则需要查找一张 巨大的表格。但如果告诉您城市” Ithaca”是:南美洲国家圭亚那的北部城市”Ithaca”,那么就容易些了吧?
被管理的设备相当复 杂,拥有很多可以被管理的参数,需要对它们进行归类,分级。管理信息库 (MIB) 是一个具有分层特性的信息的集合,我们可以通过 SNMP 去存取它。MIB 的成员是一些被管理的对象 (Managed Object),以对象标示符 (Object Identifiers) 来区分它们。被管理的对象由一个或多个对象实例 (Object Instances) 组成,本质上,这些对象实例就是变量。
在 MIB 的层次结构中,一个对象标示符唯一标识了被管理对象。MIB 的层次结构可以被描述成无根名的树,树的级别被不同的组织所划分。如下图所示:
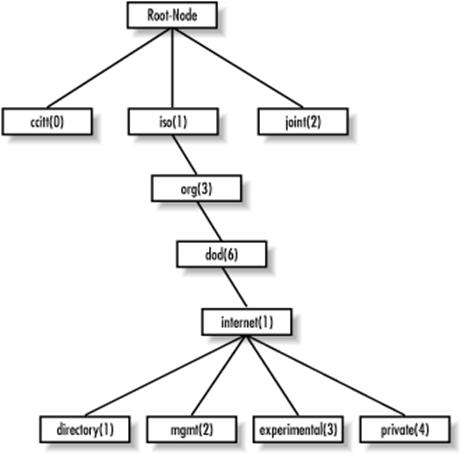
相应的数字表示(对象标识符OID,唯一标识一个MIB对象)
很多能够被 SNMP 管理的对象都是由标准组织定义好的。比如系统磁盘的信息,用 OID ”1.3.6.1.4.1.2021.9” 表示。这串数字是国际标准化组织协商定义好的,大家都要去遵循它。当然,国际组织不可能预知未来,如果您要开发的设备有一些管理需求没有任何 RFC 定义过,那么您也可以编写自己的 MIB 文件来定义私有的 MIB 对象。
NET-SNMP 是一种开放源代码的 SNMP 协议实现。它支持 SNMP v1, SNMP v2c 与 SNMP v3,并可以使用 IPV4 及 IPV6 。也包含 SNMP Trap 的所有相关实现。Net-snmp 包含了 snmp 实用程序集和完整的 snmp 开发库。
用户使用 net-snmp 提供的工具,可以完成很多关于 SNMP 的操作,具体说来,包括以下一些命令行应用程序:
一些应用程序可以用来从支持 SNMP 的设备获得数据。其中 snmpget, snmpgetnext 可以支持独立请求,比如:

NET-SNMP 简介
在 Linux 系统中,我们可以选择 net-snmp 来处理绝大多数和 SNMP 相关的工作。
NET-SNMP 是一种开放源代码的 SNMP 协议实现。它支持 SNMP v1, SNMP v2c 与 SNMP v3,并可以使用 IPV4 及 IPV6 。也包含 SNMP Trap 的所有相关实现。Net-snmp 包含了 snmp 实用程序集和完整的 snmp 开发库。
用户使用 net-snmp 提供的工具,可以完成很多关于 SNMP 的操作,具体说来,包括以下一些命令行应用程序:
一些应用程序可以用来从支持 SNMP 的设备获得数据。其中 snmpget, snmpgetnext 可以支持独立请求,比如:
% snmpget -v 1 -c demopublic test.net-snmp.org system.sysUpTime.0system.sysUpTime.0 = Timeticks: (586731977) 67 days, 21:48:39.77
该命令获得单个独立的 MIB 对象 system.sysUpTime.0 的值。
而 snmpwalk, snmptable, snmpdelta 则用来支持重复请求。
% snmpwalk -v 2c -c demopublic test.net-snmp.org systemSNMPv2-MIB::sysDescr.0 = HP-UX net-snmp B.10.20 A 9000/715SNMPv2-MIB::sysObjectID.0 = OID: enterprises.ucdavis.ucdSnmpAgent.hpux10SNMPv2-MIB::sysUpTime.0 = Timeticks: (586998396) 67 days, 22:33:03.96SNMPv2-MIB::sysContact.0 = Wes Hardaker wjhardaker@ucdavis.eduSNMPv2-MIB::sysName.0 = net-snmp
上面的命令返回所有 system 节点以下的 MIB 对象的值。
命令 snmpset 对支持 SNMP 的设备配置属性。如下例所示:
$ snmpget -v 1 -c demopublic test.net-snmp.org ucdDemoPublicString.0UCD-DEMO-MIB::ucdDemoPublicString.0 = "hi there!"$ snmpset -v 1 -c demopublic test.net-snmp.org ucdDemoPublicString.0 s "Hello, world!"UCD-DEMO-MIB::ucdDemoPublicString.0 = "Hello, world!"$ snmpget -v 1 -c demopublic test.net-snmp.org ucdDemoPublicString.0UCD-DEMO-MIB::ucdDemoPublicString.0 = "Hello, world!"
命令 snmpdf, snmpnetstat, snmpstatus 可以从支持 SNMP 的设备获取特定的信息。比如下面的命令从目标系统上获得类似 netstat 的信息:
% snmpnetstat -v 2c -c public -a testhostActive Internet (tcp) Connections (including servers)Proto Local Address Foreign Address (state)tcp *.echo *.* LISTENtcp *.discard *.* LISTENtcp *.daytime *.* LISTENtcp *.chargen *.* LISTENtcp *.ftp *.* LISTENtcp *.telnet *.* LISTENtcp *.smtp *.* LISTENActive Internet (udp) ConnectionsProto Local Addressudp *.echoudp *.discardudp *.daytimeudp *.chargenudp *.time
snmptranslate 命令将 MIB OIDs 的两种表现形式 ( 数字及文字 ) 相互转换。并显示 MIB 的内容与结构,如下所示:
% snmptranslate .1.3.6.1.2.1.1.3.0SNMPv2-MIB::sysUpTime.0% snmptranslate -On SNMPv2-MIB::sysUpTime.0.1.3.6.1.2.1.1.3.0
Net-snmp还提供了一个基于 Tk/perl 的,图形化的 MIB 浏览器 tkmib。
首先调用函数 snmp_pdu_create 创建一个 SNMPv2 的 Trap PDU。然后调用 snmp_add_var 向该 PDU 中添加图三所示的三个部分。 sysUpTime 在 SNMPv2-MIB 中定义,其 OID 为”1.3.6.1.2.1.1.3.0”。我们只需要通过 get_uptime() 函数获得该值,然后调用 snmp_add_var 将该变量加入刚才创建的 PDU中。
snmp例子:查看系统第一分钟的负载
[root@localhost snmp]# snmpget -v2c -c abcdocker 192.168.56.11 1.3.6.1.4.1.2021.10.1.3.1#-c是团体名,在配置文件中定义的,还有ip地址UCD-SNMP-MIB::laLoad.1 = STRING: 0.00[root@localhost snmp]# cat /etc/snmp/snmpd.confrocommunity abcdocker 192.168.56.11
提示:我们cpu所有指标都有一个oid 后面我们定义的数字就是oid
例如cacti就是通过snmp来获取性能指标,在使用RRDTool来进行画图
SNMP 2种常用模式
1、GerRequest PDU
2、GetNextRequest PDU
[root@localhost snmp]# snmpwalk -v2c -c abcdocker 192.168.56.11 1.3.6.1.4.1.2021.10.1.3UCD-SNMP-MIB::laLoad.1 = STRING: 0.00UCD-SNMP-MIB::laLoad.2 = STRING: 0.01UCD-SNMP-MIB::laLoad.3 = STRING: 0.05[root@localhost snmp]# uptime13:16:08 up 6:35, 2 users, load average: 0.00, 0.01, 0.05
linux下常用Oid
http://linux.chinaunix.net/techdoc/net/2008/08/21/1026818.shtml
http://www.2cto.com/os/201211/170730.html
提示:只需要在IP地址后面输入相对应的oid即可
系统监控:
- CPU
- 内存
- IO Input/Ouput(网络、磁盘)
企业面试题:如果系统负载达到200了,SSH连接不上。如何让SSH连接上
解: 可以改变SSH的优先级
CPU三个重要的概念:
1.上下文切换:CPU调度器实施的进程的切换过程,上下文切换
2.运行队列(负载):运行队列,排队 可以参考我是一个进程文章
3.使用率
监控CPU需要确定服务类型:
(1) IO密集型 (数据库)
(2) CPU密集型(Web/mail)
确定性能的基准线
运行队列:1-3个线程 1CPU 4核 负载不超过12
CPU使用:65%-70%用户态利用率
30%-35%内核态利用率
0%-5% 空闲
上下文切换: 越少越好
所有的监控都要根据业务来考虑
常见的系统监控工具
Top、sysstat、mpstat
工具的使用方法
TOP参数解释
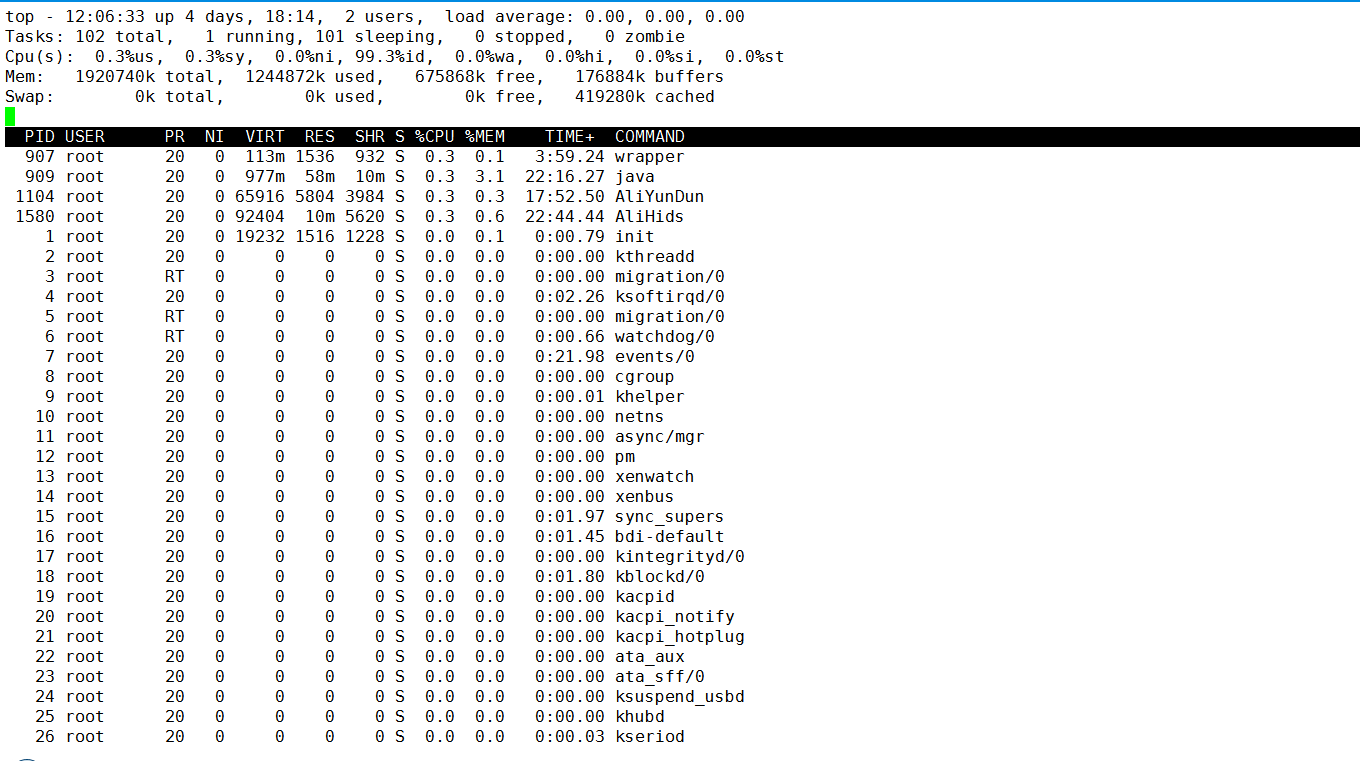
第一行 分别显示:系统当前时间 系统运行时间 当前用户登陆数 系统负载。
系统负载(load average),这里有三个数值,分别是系统最近1分钟,5分钟,15分钟的平均负载。一般对于单个处理器来说,负载在0 — 1.00 之间是正常的,超过1.00就要引起注意了。在多核处理器中,你的系统均值不应该高于处理器核心的总数。
第二行 分别显示:total进程总数、 running正在运行的进程数、 sleeping睡眠的进程数、stopped停止的进程数、 zombie僵尸进程数。
第三行
分别显示:
%us用户空间占用CPU百分比、
%sy内核空间占用CPU百分比、
%ni用户进程空间内改变过优先级的进程占用CPU百分比、
%id空闲CPU百分比、
%wa等待输入输出(I/O)的CPU时间百分比 、
%hi指的是cpu处理硬件中断的时间、%si指的是cpu处理软中断的时间 、
%st用于有虚拟cpu的情况,用来指示被虚拟机偷掉的cpu时间。
通常id%值可以反映一个系统cpu的闲忙程度。
第四行 MEM :total 物理内存总量、 used 使用的物理内存总量、free 空闲内存总量、buffers 用作内核缓存的内存量。
第五行 SWAP:total 交换区总量、 used使用的交换区总量、free 空闲交换区总量、 cached缓冲的交换区总量。
buffers和cached的区别需要说明一下,buffers指的是块设备的读写缓冲区,cached指的是文件系统本身的页面缓存。它们都是linux操作系统底层的机制,目的就是为了加速对磁盘的访问。
第六行 PID(进程号)、 USER(运行用户)、PR(优先级)、NI(任务nice值)、VIRT(虚拟内存用量)VIRT=SWAP+RES 、RES(物理内存用量)、SHR(共享内存用量)、S(进程状态)、%CPU(CPU占用比)、%MEM(物理内存占用比)、TIME+(累计CPU占 用时间)、 COMMAND 命令名/命令行。
下面简单介绍top命令的使用方法:
top [-] [d] [p] [q] [c] [C] [S] [s] [n]
运维必会!
参数说明
d指定每两次屏幕信息刷新之间的时间间隔。当然用户可以使用s交互命令来改变之。
p通过指定监控进程ID来仅仅监控某个进程的状态。
q该选项将使top没有任何延迟的进行刷新。如果调用程序有超级用户权限,那么top将以尽可能高的优先级运行。
S指定累计模式。
s使top命令在安全模式中运行。这将去除交互命令所带来的潜在危险。
i使top不显示任何闲置或者僵死进程。
c显示整个命令行而不只是显示命令名。
下面介绍在top命令执行过程中可以使用的一些交互命令
从使用角度来看,熟练的掌握这些命令比掌握选项还重要一些。
这些命令都是单字母的,如果在命令行选项中使用了s选项,则可能其中一些命令会被屏蔽掉。
Ctrl+L 擦除并且重写屏幕。
h或者? 显示帮助画面,给出一些简短的命令总结说明。
k 终止一个进程。系统将提示用户输入需要终止的进程PID,以及需要发送给该进程什么样的信号。一般的终止进程可以使用15信号;如果不能正常结束那就使用信号9强制结束该进程。默认值是信号15。在安全模式中此命令被屏蔽。
i 忽略闲置和僵死进程。这是一个开关式命令。
q 退出程序。
r 重新安排一个进程的优先级别。系统提示用户输入需要改变的进程PID以及需要设置的进程优先级值。输入一个正值将使优先级降低,反之则可以使该进程拥有更高的优先权。默认值是10。
s 改变两次刷新之间的延迟时间。系统将提示用户输入新的时间,单位为s。如果有小数,就换算成m s。输入0值则系统将不断刷新,默认值是5 s。需要注意的是如果设置太小的时间,很可能会引起不断刷新,从而根本来不及看清显示的情况,而且系统负载也会大大增加。
f或者F 从当前显示中添加或者删除项目。
o或者O 改变显示项目的顺序。
l 切换显示平均负载和启动时间信息。
m 切换显示内存信息。
t 切换显示进程和CPU状态信息。
c 切换显示命令名称和完整命令行。
M 根据驻留内存大小进行排序。
P 根据CPU使用百分比大小进行排序。
T 根据时间/累计时间进行排序。
W 将当前设置写入~/.toprc文件中。这是写top配置文件的推荐方法。
Shift+M 可按内存占用情况进行排序。
sysstat 说明
[root@www ~]# yum install sysstat -y[root@www ~]# vmstat --helpusage: vmstat [-V] [-n] [delay [count]]-V prints version.-n causes the headers not to be reprinted regularly.-a print inactive/active page stats.-d prints disk statistics-D prints disk table-p prints disk partition statistics-s prints vm table-m prints slabinfo-t add timestamp to output-S unit sizedelay is the delay between updates in seconds.unit size k:1000 K:1024 m:1000000 M:1048576 (default is K)count is the number of updates.
例子:每隔1秒获取1次,次数不限
[root@www ~]# vmstat 1procs -----------memory---------- ---swap-- -----io---- --system-- -----cpu-----r b swpd free buff cache si so bi bo in cs us sy id wa st0 0 0 547332 177544 535336 0 0 1 6 5 41 1 0 98 0 00 0 0 547324 177544 535336 0 0 0 0 210 445 1 0 99 0 00 0 0 547324 177544 535336 0 0 0 0 195 435 0 0 100 0 00 0 0 547324 177544 535336 0 0 0 0 208 440 1 0 99 0 00 0 0 547332 177544 535336 0 0 0 0 209 446 0 0 100 0 00 0 0 547332 177544 535336 0 0 0 0 207 442 1 1 98 0 00 0 0 547332 177544 535336 0 0 0 0 201 438 0 0 100 0 0^C
#r表示CPU排队的情况,b代表 进程堵塞,等待io
每隔1秒获取1次,次数10次
[root@www ~]# vmstat 1 10procs -----------memory---------- ---swap-- -----io---- --system-- -----cpu-----r b swpd free buff cache si so bi bo in cs us sy id wa st1 0 0 547340 177544 535344 0 0 1 6 5 41 1 0 98 0 00 0 0 547332 177544 535344 0 0 0 28 210 453 1 1 97 1 00 0 0 547332 177544 535344 0 0 0 0 200 433 0 0 100 0 00 0 0 547332 177544 535344 0 0 0 0 211 445 1 0 99 0 00 0 0 547332 177544 535344 0 0 0 0 201 439 0 1 99 0 00 0 0 547332 177544 535344 0 0 0 0 197 436 0 0 100 0 00 0 0 547332 177544 535344 0 0 0 0 201 442 1 0 99 0 00 0 0 547324 177544 535348 0 0 0 0 240 484 2 1 97 0 00 0 0 547324 177544 535348 0 0 0 0 203 438 0 0 100 0 00 0 0 547324 177544 535348 0 0 0 0 197 430 1 0 99 0 0
mpstat
查看所有CPU的平均值
[root@www ~]# mpstat 1Linux 2.6.32-431.23.3.el6.x86_64 (www) 08/30/2016 _x86_64_ (1 CPU)05:13:22 PM CPU %usr %nice %sys %iowait %irq %soft %steal %guest %idle05:13:23 PM all 1.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 99.00105:13:24 PM all 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 100.0005:13:25 PM all 2.00 0.00 1.00 0.00 0.00 0.00 0.00 0.00 97.0005:13:26 PM all 1.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 99.00^C
不解释——————————
[root@www ~]# mpstat 1 10Linux 2.6.32-431.23.3.el6.x86_64 (www) 08/30/2016 _x86_64_ (1 CPU)05:13:38 PM CPU %usr %nice %sys %iowait %irq %soft %steal %guest %idle05:13:39 PM all 2.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 98.0005:13:40 PM all 0.00 0.00 1.00 0.00 0.00 0.00 0.00 0.00 99.0005:13:41 PM all 1.01 0.00 0.00 0.00 0.00 0.00 0.00 0.00 98.99.................
上述是CPU监控,CPU监控主要靠经验。因为业务不同指标不同,指标越低越好是不变的道理
内存硬盘监控:
硬盘格式化后分成块(blog)
内存默认是页(大小4kb)读取按照页来进行读取
内存:free vmstat
[root@www ~]# free -mtotal used free shared buffers cachedMem: 1875 1338 537 0 173 523-/+ buffers/cache: 640 1234Swap: 0 0 0提示:云主机是没有Swap分区的
total 总内存
used 已使用内存
free 空闲内存
shared 共享内存(进程间相互通信使用共享内存)
buffers 缓冲
cached 缓存
Centos7 会有一个available,活动内存
#云服务器一般不分配swap分区,物理机能不使用交换分区就不使用交换分区
vmstat命令
[root@www ~]# vmstat 1procs -----------memory---------- ---swap-- -----io---- --system-- -----cpu-----r b swpd free buff cache si so bi bo in cs us sy id wa st0 0 0 550628 177684 536324 0 0 1 6 7 46 1 0 98 0 00 0 0 550620 177684 536324 0 0 0 40 187 429 0 0 100 0 00 0 0 550620 177684 536324 0 0 0 0 183 427 1 0 99 0 00 0 0 550620 177684 536324 0 0 0 0 197 436 0 1 99 0 0
swpd交换分区的大小
free可用的物理内存大小
buff 缓冲区的大小
cache 缓存区的大小
si 数据从交换分区读取到内存的大小
so 数据从内存到交换分区
bi 从交换分区读到内存(block)
bo 内存写到硬盘的
内存达到多少报警呢? 80%
正常是一个进程启动后会一直往上升,最后到达一个平稳期
硬盘:IOPS IO’s Per Second iotop df -h iostat
顺序IO(快)
随机IO(慢)
查看磁盘剩余空间
[root@www ~]# df -hFilesystem Size Used Avail Use% Mounted on/dev/xvda1 40G 4.1G 34G 11% /tmpfs 938M 0 938M 0% /dev/shm
监控磁盘IO iotop
[root@www ~]# yum install iotop -y
iotop
可以使用dd命令生成一个文件夹进行测试
生成命令如下:
[root@www ~]# dd if=/dev/zero of=/tmp/1.txt bs=1M count=10001000+0 records in1000+0 records out1048576000 bytes (1.0 GB) copied, 20.509 s, 51.1 MB/s[root@www ~]# ls -lh /tmp/1.txt-rw-r--r-- 1 root root 1000M Aug 30 19:48 /tmp/1.txt
此时IO写入如下图
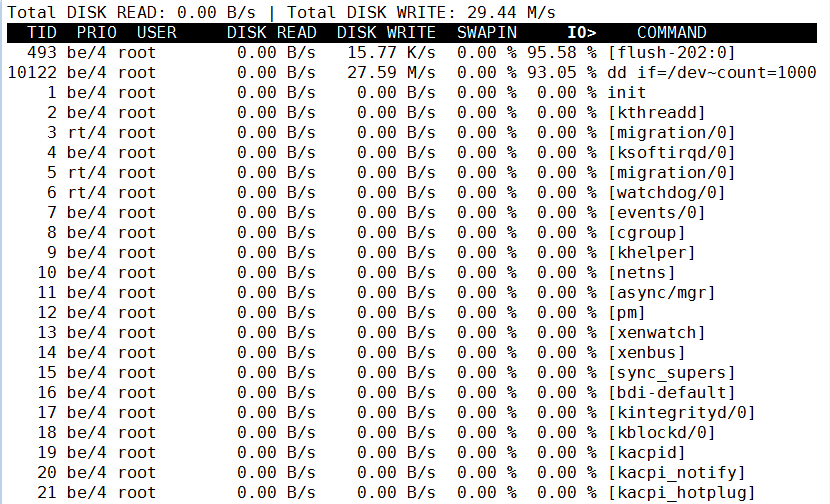
iostat命令,可以看到那块磁盘,比iotop更加细致
[root@www ~]# iostat 1 2Linux 2.6.32-431.23.3.el6.x86_64 (www) 08/30/2016 _x86_64_ (1 CPU)avg-cpu: %user %nice %system %iowait %steal %idle1.10 0.00 0.27 0.16 0.00 98.46Device: tps Blk_read/s Blk_wrtn/s Blk_read Blk_wrtnxvda 1.51 2.26 17.09 986748 7467560avg-cpu: %user %nice %system %iowait %steal %idle1.02 0.00 0.00 0.00 0.00 98.98Device: tps Blk_read/s Blk_wrtn/s Blk_read Blk_wrtnxvda 0.00 0.00 0.00 0 0
tps 设备每秒的传输次数(每秒多少的io请求)
Blk_read/s 每秒从设备读取的数据量
Blk_wrtn/s 每秒像设备写入的数据量
Blk_read 写入数据的总数
Blk_wrtn 读取数据的总数
网络监控:iftop
[root@www ~]# yum install iftop -y[root@www ~]# iftop -n #-n不做域名解析
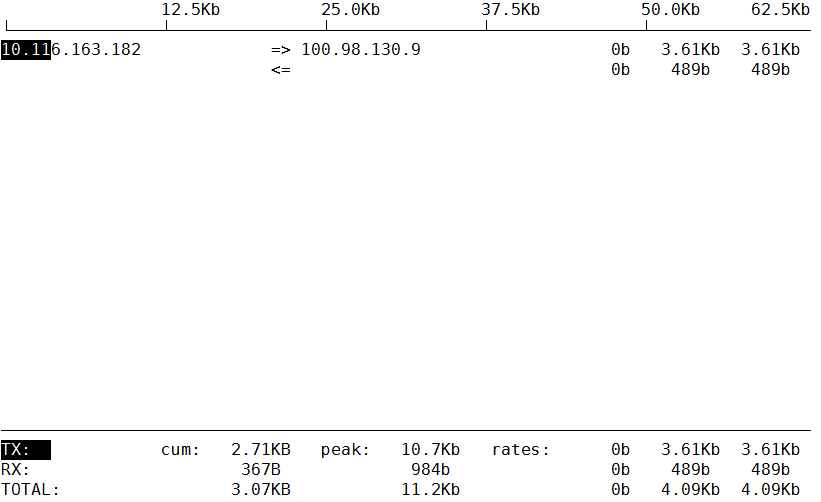
正常监控只需要监控网卡带宽即可
其中网络监控是最复杂的,ping监控网络延迟网络丢包等。但是此类的网络监控只是监控自己到客户端是否丢包,并不能保证客户端到服务器这边不丢包
其中就产生了如:阿里测、奇云测、站长工具等一系列多节点的监控工具
性能测试常用工具:IBM nmon (nmon analyser---生成AIX性能报告的免费工具)
http://nmon.sourceforge.net/pmwiki.php #下载地址(需要翻墙工具)
所以我们提供了百度云下载
链接:http://pan.baidu.com/s/1boXV6R9 密码:sblf
只需要下载对应的版本,给执行权限。执行即可
[root@localhost tmp]# chmod +x nmon16e_x86_rhel72[root@localhost tmp]# ./nmon16e_x86_rhel72

我们可以直接输入一个c 一个m一个d。这个是实时的一个状态
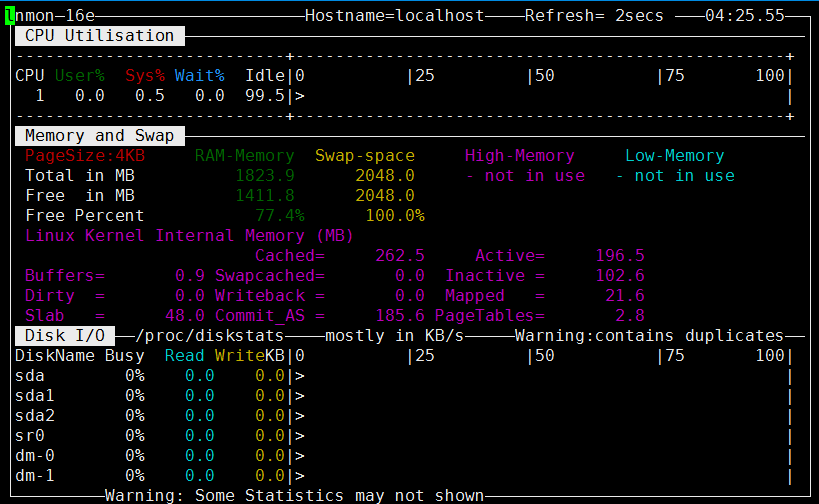
我们可以查看帮助
[root@localhost tmp]# ./nmon16e_x86_rhel72 --help./nmon16e_x86_rhel72: invalid option -- '-'Hint for nmon16e_x86_rhel72 version 16eFull Help Info : nmon16e_x86_rhel72 -hOn-screen Stats: nmon16e_x86_rhel72Data Collection: nmon16e_x86_rhel72 -f [-s <seconds>] [-c <count>] [-t|-T]Capacity Plan : nmon16e_x86_rhel72 -xInteractive-Mode:Read the Welcome screen & at any time type: "h" for more helpType "q" to exit nmonFor Data-Collect-Mode-f Must be the first option on the line (switches off interactive mode)Saves data to a CSV Spreadsheet format .nmon file in then local directoryNote: -f sets a defaults -s300 -c288 which you can then modifyFurther Data Collection Options:-s <seconds> time between data snapshots-c <count> of snapshots before exiting-t Includes Top Processes stats (-T also collects command arguments)-x Capacity Planning=15 min snapshots for 1 day. (nmon -ft -s 900 -c 96)---- End of Hints-c 采集的次数-s 采集的间隔时间-f 生成一个文件-m 指定生成文件位置
采集10次 间隔10秒
[root@localhost tmp]# ./nmon16e_x86_rhel72 -c 10 -s 10 -f -m /tmp/[root@localhost tmp]# lslocalhost_160831_0435.nmon nmon16e_x86_rhel72
前面为主机名后面是日期(年月日时分)
因为测试可能需要,我们要制作成表格,所以现在将文件上传到桌面上
[root@localhost tmp]# sz localhost_160831_0435.nmon
我们打开下载的工具
解压文件夹,打开nmon analyser v34a.xls
点击Analyse nmon data找到我们刚刚复制出来的文件,就可以看到了。
应用服务监控:
举例:Nginx
安装nginx
[root@localhost ~]# yum install -y gcc glibc gcc-c++ prce-devel openssl-devel
提示:nginx可以使用稳定版的最新版,因为安全性会不断的提高。如果是特别老的版本会有一些漏洞和功能
要想监控nginx需要在编译时添加如下参数
--with-http_stub_status_module
下载Nginx
[root@localhost src]# wget http://nginx.org/download/nginx-1.10.1.tar.gz
解压,后面步骤太简单不说了
安装
[root@localhost nginx-1.10.1]# useradd -s /sbin/nologin www[root@localhost nginx-1.10.1]# ./configure --prefix=/usr/local/nginx-1.10.1 --user=www --group=www --with-http_ssl_module --with-http_stub_status_module
#configure 是一个shell脚本,执行它的作用是生成MAKEFILE(编译make需要)
[root@localhost nginx-1.10.1]# make && make install[root@localhost nginx-1.10.1]# lltotal 676drwxr-xr-x 6 1001 1001 4096 Aug 31 06:02 auto-rw-r--r-- 1 1001 1001 262898 May 31 09:47 CHANGES-rw-r--r-- 1 1001 1001 400701 May 31 09:47 CHANGES.rudrwxr-xr-x 2 1001 1001 4096 Aug 31 06:02 conf-rwxr-xr-x 1 1001 1001 2481 May 31 09:47 configuredrwxr-xr-x 4 1001 1001 68 Aug 31 06:02 contribdrwxr-xr-x 2 1001 1001 38 Aug 31 06:02 html-rw-r--r-- 1 1001 1001 1397 May 31 09:47 LICENSE-rw-r--r-- 1 root root 404 Aug 31 07:46 Makefiledrwxr-xr-x 2 1001 1001 20 Aug 31 06:02 mandrwxr-xr-x 3 root root 119 Aug 31 07:46 objs-rw-r--r-- 1 1001 1001 49 May 31 09:47 READMEdrwxr-xr-x 9 1001 1001 84 Aug 31 06:02 src
#make是生成文件,make install是将生成的文件拷贝到不同的地方
make install 完成之后可以直接将当前目录拷贝到其他服务器上,安装相同的依赖就可以进行使用。
[root@localhost nginx-1.10.1]# ln -s /usr/local/nginx-1.10.1/ /usr/local/nginx[root@localhost nginx-1.10.1]# netstat -lntp|grep nginxtcp 0 0 0.0.0.0:80 0.0.0.0:* LISTEN 7058/nginx: master
修改nginx.conf配置文件
location /status {stub_status on;access_log off;allow 192.168.56.0/24;deny all;}
设置只允许56网段访问,并开启日志和状态模块
#这个比较基础,如果不知道怎么添加。可以参考www.nginx.org 状态模块
浏览器访问:http://192.168.56.11/status
Active connections: 1server accepts handled requests3 3 163Reading: 0 Writing: 1 Waiting: 0
Active connections: 当前活跃的连接数
3—-> 一共处理了多少个链接(请求)
3—-> 成功创建多少次握手
163–> 总共创建了多少个请求
Reading:当前读取客户端heardr的数量
Writing:当前返回给客户端heardr的数量 #如果这个指标飙升,说明是后面的节点挂掉了,例如数据库等。
Waiting:大体意思是已经处理完,等待下次请求的数量
提示:我们只需要关注活动链接即可
监控最基础的功能
采集 存储 展示 告警
几款监控软件说明:
Nagios+Cacti Nagios报警功能比较强,但是画图比较弱(有插件) Cacti 画图比较强,报警比较弱(有插件)
Zabbix 可以直接监控IPMI、SNMP、JVM 这些监控项目别的软件本身干不了,插件除外
Zabbix 分为Server---->Agent 有主动和被动模式
Gangla 根本没听说过!














 944
944











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









