







经过多次尝试,终于在windows上成功编译wireshark源代码,但用的不是下面的这个步骤,不过大同小异,我的是vs2005,所以用的:http://blog.csdn.net/alexander_vc/article/details/6198836 的方法。
- 1.2.7版的wireshark的capture_if_details_dlg_win32.c对vs2005有bug,需要下载更新的wireshark版本,并更换该文件。详见wireshark的
几点注意:1.python要用2.4——2.6版本
2.Cygwin安装要把文中介绍的库一并安装
3.如果执行命令,总是nmake报各种错,请反复检查你的Wireshark目录里面config.nmake文件配置的是否正确。
用vs2005,vs2010都编译成功了。不得不说这得靠人品,多试试,办法总是有的。
原文地址:http://blog.sina.com.cn/xianjiaotonguniversity
在windows上编译wireshark源代码
在编译过程中需要以下软件:VisualStudio,Python,Cygwin以及Wireshark源代码。
1. Visual Studio
我使用的是Visual Studio 2008版本。
2. Python
下载安装Python,从2.4 –2.6应该都是可以的,我使用2.6版本。主要是在编译过程中会使用到Python。
3. Cygwin
去Cygwin上下载最新版本安装,然后开始安装,整个安装过程是在线安装,特别注意的是,以下库必须安装,否则不能顺利完成编译:
Archive / unzip Devel / bison Devel / flex Interpreters / perl Utils / patch Web / wget
4. 下载Wireshark源代码 &编辑config.nmake
输入这个网址,http://www.wireshark.org/download/src/all-versions/,从上面下载Wireshark源代码,这里,值得一提的是,最好下载页面中给出的svn中的源代码,能保证该代码绝对是最新的。
下载完成之后,在Wireshark目录里面打开config.nmake,需要进行一些设置之后才可以开始编译。
(1)WIRESHARK_LIBS, 设置编译wireshark所需的库所在的目录,默认即可。
(2)PROGRAM_FILES,设置本机程序安装目录,默认即可。
(3)MSVC_VARIANT,因为我使用VS2008编译,所以这里不要修改。如果使用的是其他版本的VS,则要将相应行前面的#去掉,并把其余行的#加上。例如如果你使用的是VS2005,则将值为MSVC2005的那一行前的#去掉,其余MSVC_VARIANT项行首全部加上#注释掉。
(4)CYGWIN_PATH,将其设置为cygwin的bin目录,例如D:\cygwin\bin。
(5)MSVCR_DLL,如果VS安装在D盘,请在这里相应的地方用绝对路径表示,而不要去修改前面的PROGRAM_FILES,否则会出现意想不到的错误。
5. 编译Wireshark
用VS2008安装的VS2008命令提示进入或者通过CMD进入之后,再去运行VC下面的vcvars32.bat,或者是把vcvars32.bat拖到命令窗口,再回车就行。然后进去Wireshark目录,首先通过下面的命令检验一下:
nmake -f Makefile.nmake verify_tools 得到的信息如下:我忘了截图,这是copy别人的图,不过我的跟他的基本一样,出了上面的版权信息是中文,以及版权信息下面有个Error,说是C:\wireshark-win32-libs\current_tag.txt中的内容应该是2011-06-27外,其他都是一样的。不过这个错误不用管,不会影响编译。
6.执行nmake –f Makefile.nmake setup 得到很多信息,最后如下:7.先执行下nmake –f Makefile.nmake distclean 8.执行nmake –f Makefile.nmake all
这个过程要花上10几分钟,到这里,编译就完成了。
wireshark源代码分析报告之一
因为手头的项目需要识别应用层协议,于是想到了wireshark,打算在项目中集成wireshark协议分析代码。在官网上下了最新版的wireshark源代码,我的天啊,200多M,这么多代码文件怎么看?在网上了找了很久,希望能找到别人的分析报告,可惜的是,找了很久也没有找到,比较多的还是怎么开发wireshark协议识别和分析插件,很少有人分析它的源代码。于是,我找了个查看源代码比较方便的工具——sourceinsight,打算先瞧一瞧这些代码文件,说不定运气好,看着看着就知道它是怎么工作的。

wireshark源代码分析报告之二
一、源代码结构
在wireshark源代码根目录下,可以看到以下子目录:
1)物理结构

2)逻辑结构
二、Tshark协议解析模块
主要处理流程如下所示:
第一步:
struct wtap {
FILE_T fh;
FILE_T random_fh; /* Secondary FILE_T for random access */
int file_type;
guint snapshot_length;
struct Buffer *frame_buffer;
struct wtap_pkthdr phdr;
union wtap_pseudo_header pseudo_header;
gint64 data_offset;
void *priv;
subtype_read_func subtype_read;
subtype_seek_read_func subtype_seek_read;
void (*subtype_sequential_close)(struct wtap*);
void (*subtype_close)(struct wtap*);
int file_encap; /* per-file, for those file formats that have per-file encapsulation types */
int tsprecision; /* timestamp precision of the lower 32bits * e.g. WTAP_FILE_TSPREC_USEC */
wtap_new_ipv4_callback_t add_new_ipv4;
wtap_new_ipv6_callback_t add_new_ipv6;
GPtrArray *fast_seek;
};
a)
- 调用int
libpcap_open(wtap *wth, int *err, gchar **err_info)函数读取给定pcap文件的文件头信息,总共28个字节,如下所示:
libpcap_open()
libpcap_try()函数首先调用libpcap_read_header()函数读取第一个数据包的数据包头,该数据包头的结构如下所示:
struct
{
struct
}
struct
{
DWORD
DWORD
}
该数据包头总共16个字节。然后再调用file_seek()(该函数主要功能就是实现文件定位)函数定位到第一个数据包之后,即24字节的文件头+16字节的数据包头+caplen字节的第一个数据包的数据部分长度。如果file_seek()操作正确,即不返回-1,则libpcap_try()函数再次调用libpcap_read_header()函数,读取第二个数据包的包头信息。如果读取正确,则libpcap_try()函数返回THIS_FORMAT,表示pcap文件格式正确。
这时libpcap_open()调用file_seek()定位到给定pcap文件的文件头之后,也就是24字节处,并返回1,表示操作成功。
b)wtap_open_offline()函数为wtap的frame_buffer结构体的buffer部分分配最大空间1500字节,然后返回给定pcap文件的wtap信息。
c)当wtap_open_offline()函数正确返回wtap信息后,cf_open()函数调用cleanup_dissection()函数清空接下来在协议解析工作中需要用到的数据结构。
- cleanup_dissection()的清空工作包括:
- cleanup_dissection()返回后,cf_open()函数调用init_dissection()函数初始化后续解析工作中要用到的所有数据。init_dissection()的初始化工作基本上与cleanup_dissection()清空的内容一致。
- 这些工作完成后,设置capture_file信息并返回到main()函数。
2.
3.
load_cap_file()函数完成的具体工作如下:
a)
b)
c)
d)
e)
f)
g)
h)
i)
j)
i.
ii.
iii.
iv.
v.
vi.
a)
b)
1)如果column_info不为空,则调用col_init(column_info
2)设置edt->pi的值。如下所示:
edt->pi.current_proto
3)调用tvbuff_t*
4)调用void
5)调用int
vii.
viii.
ix.
x.
a)
b)
xi.
a)
b)
c)
xii.
a)
b)
k)process_packet()函数返回到load_cap_file()函数后,如果wtap_dumper*
l)刚才读取的数据包已经解析并打印完成,这时跳转到步骤b),读取下一个数据包数据,直到到达给定pcap文件的文件尾。
——————————————————————————————————下面是另一个作者分析的。
原文百度文库:
http://wenku.baidu.com/view/5adbe902b52acfc789ebc91a.html
1. wireshark流程分析
1) 初始化
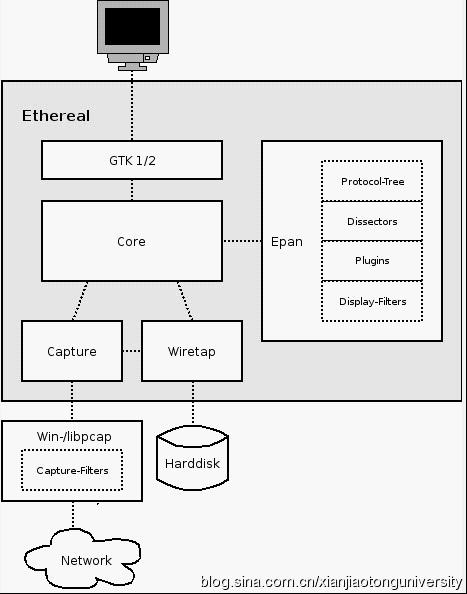
Wireshark的初始化包括一些全局变量的初始化、协议分析引擎的初始化和Gtk相关初始化,显示Ethereal主窗口,等待用户进一步操作。重点就是Epan模块的初始化。
Epan初始化:
n tvbuff初始化:全局变量tvbuff_mem_chunk指向用memchunk分配的固定大小的空闲内存块,每个内存块是tvbuff_t结构,从空闲内存块中取出后,用来保存原始数据包。
n 协议初始化:
u 全局变量:
l proto_names
l proto_short_names
l proto_filter_names
以上三个全局变量主要用来判断新注册的协议名是否重复,如果重复,给出提示信息,在协议解析过程中并没有使用。
u 协议注册:
l 注册协议:将三个参数分别注册给proto_names、proto_short_names、proto_filter_names三个全局变量中,
l 注册字段,需要在wireshark协议树显示的报文内容字段。
l 协议解析表
u Handoff注册
l 将协议与父协议节点关联起来
n Packet(包)初始化
u 全局变量:
l frame_handle:协议解析从frame开始,层层解析,直到所有的协议都解析完为止。frame_handle保存了frame协议的handle。
l data_handle:有的协议无法从frame开始,那么就从data开始。原理同frame。
n 读配置文件preference
n 读capture filter和display filter文件,分别保存在全局变量capture_filter和display_filter中。
n 读disabled protocols文件,保存全局变量global_disabled_protos和disabled_protos中
n 初始化全局变量cfile
u Cfile是个重要的变量,数据类型为capture file,它保存了数据包的所有信息,
2) 处理流程
Wireshark初始化完成以后进入实际处理阶段,主程序创建抓包进程,捕包进程和主程序是通过PIPE进行传递数据的,主程序把抓取的数据写入临时文件,通过函数add_packet_to_packet_list将数据包加入包列表。处理时,主程序从列表中选取一个数据包,提取该数据包中的数据填写在数据结构中,最后调用协议解析函数epan_dissect_run进行处理,从epan_dissect_run开始,是实际的协议解析过程,
下面以HTTP协议报文为例,流程如下:
a) 解析frame层
调用函数dissect_frame对frame层进行解析,并在协议树上填充相应字段信息。函数最后会判断是否有上层协议封装,如果有则调用函数dissector_try_port在协议树上查找对应的解析函数,这里函数dissector_try_port根据pinfo->fd->lnk_t查找对应的上层协议处理函数,pinfo->fd->lnk_t值为1,上层封装协议为以太网协议,全局结构体指针变量dissector_handle当前的协议解析引擎句柄置为dissect_eth_maybefcs,至此,frame层解析结束。
a) 解析以太网层
函数call_dissector_work根据dissector_handle调用frame上层协议解析函数dissect_eth_maybefcs对以太网层进行解析,并在协议树上填充相应字段,包括目的MAC地址和以太网上层协议类型等信息。函数最后会判断是否有上层协议封装,如果有则调用函数dissector_try_port在协议树上查找对应的解析函数,这里函数dissector_try_port根据etype查找对应的上层协议处理函数,以太网字段etype为0800的报文是ip报文,上层封装协议为IP协议,全局结构体指针变量dissector_handle当前的协议解析引擎句柄置为dissect_ip,至此,以太网层解析结束。
b) 解析IP层
函数call_dissector_work根据dissector_handle调用以太网上层协议解析函数dissect_ip对以太网层进行解析,并在协议树上填充相应字段,包括版本号,源地址,目的地址等信息。函数最后会判断是否有上层协议封装,如果有则调用函数dissector_try_port在协议树上查找对应的解析函数,这里函数dissector_try_port根据nxt (nxt = iph->ip_p)查找对应的上层协议处理函数,以太网字段nxt为06的报文是TCP报文,上层封装协议为TCP协议,全局结构体指针变量dissector_handle当前的协议解析引擎句柄置为dissect_tcp,至此,IP层解析结束。
c) 解析TCP层
函数call_dissector_work根据dissector_handle调用以太网上层协议解析函数dissect_tcp对TCP层进行解析,包括对TCP头的解析和选项字段的解析,并在协议树上填充相应字段,包括源端口,目的端口,标志位等信息。函数最后会判断是否有上层协议封装,如果有则调用函数dissector_try_port在协议树上查找对应的解析函数,这里函数dissector_try_port根据port查找对应的上层协议处理函数,将源端口和目的端口分别赋值给low_port和high_port,根据low_port和high_port分别匹配上层协议解析函数,port为80的报文是HTTP报文,上层封装协议为HTTP协议,全局结构体指针变量dissector_handle当前的协议解析引擎句柄置为dissect_http,至此,TCP层解析结束。
d) 解析HTTP层
至此wireshark进入应用层协议检测阶段,wireshark解析dissect_http函数中注册的字段,并提取相应的字段值添加到协议树中,应用层的具体解析流程将在下面介绍。HTTP协议具体函数调用过程参见:
重要的数据结构
struct _epan_dissect_t {
tvbuff_t *tvb;//用来保存原始数据包
proto_tree *tree;//协议树结构
packet_info pi;// 包括各种关于数据包和协议显示的相关信息
};
/** Each proto_tree, proto_item is one of these. */
typedef struct _proto_node {
struct _proto_node *first_child;//协议树节点的第一个子节点指针
struct _proto_node *last_child; //协议树节点的最后一个子节点指针
struct _proto_node *next; //协议树节点的下一个节点指针
struct _proto_node *parent;//父节点指针
field_info *finfo;//保存当前协议要显示的地段
tree_data_t *tree_data;//协议树信息
} proto_node;
typedef struct _packet_info {
const char *current_proto; //当前正在解析的协议名称
column_info *cinfo; //wireshark显示的信息
frame_data *fd;//现在分析的原始数据指针
union wtap_pseudo_header *pseudo_header;//frame类型信息
GSList *data_src; /*frame层信息 */
address dl_src; /* 源MAC */
address dl_dst; /*目的MAC */
address net_src; /* 源IP */
address net_dst; /*目的IP */
address src; /*源IP */
address dst; /*目的IP */
guint32 ethertype; /*以太网类型字段*/
guint32 ipproto; /* IP协议类型*/
guint32 ipxptype; /* IPX 包类型 */
guint32 mpls_label; /* MPLS包标签*/
circuit_type ctype;
guint32 circuit_id; /*环路ID */
const char *noreassembly_reason; /* 重组失败原因*/
gboolean fragmented; /*为真表示未分片*/
gboolean in_error_pkt; /*错误包标志*/
port_type ptype; /*端口类型 */
guint32 srcport; /*源端口*/
guint32 destport; /*目的端口*/
guint32 match_port; /*进行解析函数匹配时的匹配端口*/
const char *match_string; /*调用子解析引擎时匹配的协议字段指针*/
guint16 can_desegment; /* 能否分段标志*/
guint16 saved_can_desegment;
int desegment_offset; /*分段大小*/
#define DESEGMENT_ONE_MORE_SEGMENT 0x0fffffff
#define DESEGMENT_UNTIL_FIN 0x0ffffffe
guint32 desegment_len;
guint16 want_pdu_tracking;
guint32 bytes_until_next_pdu;
int iplen; /*IP包总长*/
int iphdrlen; /*IP头长度*/
int p2p_dir;
guint16 oxid; /* next 2 fields reqd to identify fibre */
guint16 rxid; /* channel conversations */
guint8 r_ctl; /* R_CTL field in Fibre Channel Protocol */
guint8 sof_eof;
guint16 src_idx; /* Source port index (Cisco MDS-specific) */
guint16 dst_idx; /* Dest port index (Cisco MDS-specific) */
guint16 vsan; /* Fibre channel/Cisco MDS-specific */
/* Extra data for DCERPC handling and tracking of context ids */
guint16 dcectxid; /* Context ID (DCERPC-specific) */
int dcetransporttype;
guint16 dcetransportsalt; /* fid: if transporttype==DCE_CN_TRANSPORT_SMBPIPE */
#define DECRYPT_GSSAPI_NORMAL 1
#define DECRYPT_GSSAPI_DCE 2
guint16 decrypt_gssapi_tvb;
tvbuff_t *gssapi_wrap_tvb;
tvbuff_t *gssapi_encrypted_tvb;
tvbuff_t *gssapi_decrypted_tvb;
gboolean gssapi_data_encrypted;
guint32 ppid; /* SCTP PPI of current DATA chunk */
guint32 ppids[MAX_NUMBER_OF_PPIDS]; /* The first NUMBER_OF_PPIDS PPIDS which are present * in the SCTP packet*/
void *private_data; /* pointer to data passed from one dissector to another */
/* TODO: Use emem_strbuf_t instead */
GString *layer_names; /* layers of each protocol */
guint16 link_number;
guint8 annex_a_used;
guint16 profinet_type; /* the type of PROFINET packet (0: not a PROFINET packet) */
void *profinet_conv; /* the PROFINET conversation data (NULL: not a PROFINET packet) */
void *usb_conv_info;
void *tcp_tree; /* proto_tree for the tcp layer */
const char *dcerpc_procedure_name; /* Used by PIDL to store the name of the current dcerpc procedure */
struct _sccp_msg_info_t* sccp_info;
guint16 clnp_srcref; /* clnp/cotp source reference (can't use srcport, this would confuse tpkt) */
guint16 clnp_dstref; /* clnp/cotp destination reference (can't use dstport, this would confuse tpkt) */
guint16 zbee_cluster_id; /* ZigBee cluster ID, an application-specific message identifier that
* happens to be included in the transport (APS) layer header.
*/
guint8 zbee_stack_vers; int link_dir; /* 3GPP messages are sometime different UP link(UL) or Downlink(DL)*/
} packet_info;















 8032
8032

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









