







写在最前面:
此书包含,但是不限于下面的内容。以上只是写了一部份内容,还有,日志,试图,备份还原等内容没有写出。
markdown格式 没有出来,看得很乱,都是很基础的东西,大家将就看吧。 ----写在最后《MySQL 5.6从零开始学(视频教学版)》以MySQL5.6为线索,全面讲解MysQL5.6的安装与配置、数据库的创建、数据表的创建、数据类型和运算符、MysQL函数、查询数据、数据表的操作、索引、存储过程和函数、视图、触发器、用户管理、数据备份与还原、日志、性能优化、MySQLReplication、MySQLWorkbench、MySQLCluster集群技术等内容。
----摘自百度百科最近在看数据库,之前京东搞图书大促的时候没买到《高性能MySQL》,就买了这本书,感觉自己的底子还是比较薄弱的,想在打打基础。整本书对MYSQL的一些使用讲的还是比较不错,每个都有例子,真的很基础,就像名字说的那样,从零开始,对于MySQl的入门感觉还是不错的。花了几天最近看完了,下面总结一下整本书的大体内容和感。
- 内容
(1)数据库的安装与配置。(pass)
(2)数据库的基本操作
创建:create database dbname 删除:drop database dbname
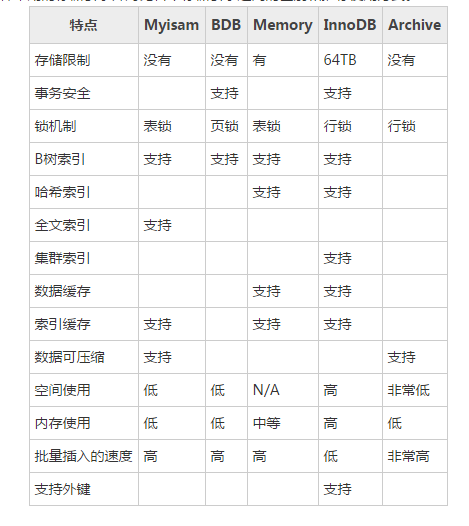
四种引擎:InnoDB/MyISAM/Memory/Archive
特点 Myisam BDB Memory InnoDB Archive
(3)表的基本操作
1. 创建:
create table tablename(
colname1 type(length) col_constraints,//列级别约束
colname1 type(length) col_constraints,
colname1 type(length) col_constraints,
.......
table_constraints//表级别约束
)列级约束:主键(primary key),唯一(unique),不空(not null),默认值(default),自增(auto_increment),外键(foreign key (colname) references table1(colname))
表级约束:主键(primary key),唯一(unique),外键(foreign key (colname) references table1(colname))
补充: 文中没有提到check,记得学习的时候学到过,然后去看了一下文档,找到了下面一句话。
“所有的存储引擎均对CHECK子句进行分析,但是忽略CHECK子句。”
The CHECK clause is parsed but ignored by all storage engines. 2.修改:
- 修改表名:alter table tablename rename newtablename
- 修改列名:alter table tablename change oldcolname newcolname
newcoltype - 修改列类型:alter table tablename modify oldcolname newcoltype
- 修改列位置:alter table tablename modify oldcolname oldcoltype after
col2name|first - 添加列:alter table tablename add newcolname newcoltype
(constraints)(after col2name|first) - 删除列:alter table tablename drop colname
删除约束:alter table tablename drop constrainttype constraintname
3.删除:drop table tablename
PS:a.外键约束不能够挂引擎使用。b.自增从最新插入记录的基础上自增+1
(4)数据类型
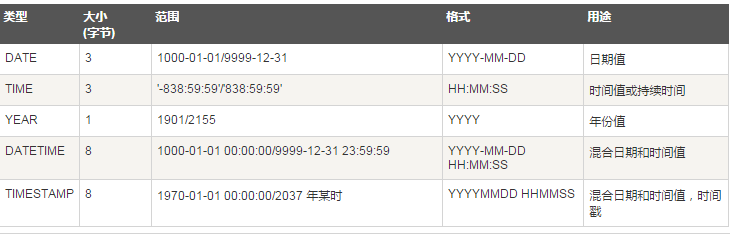
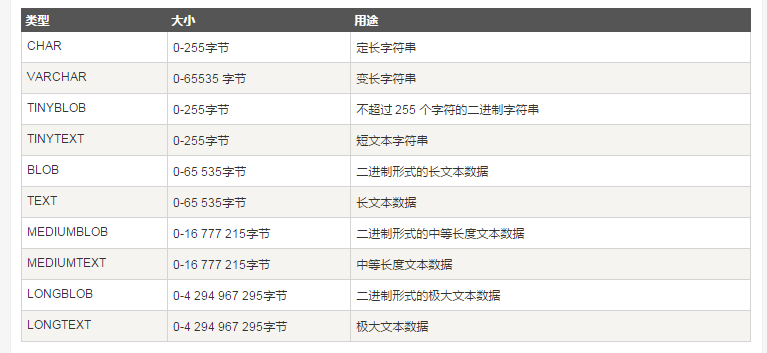
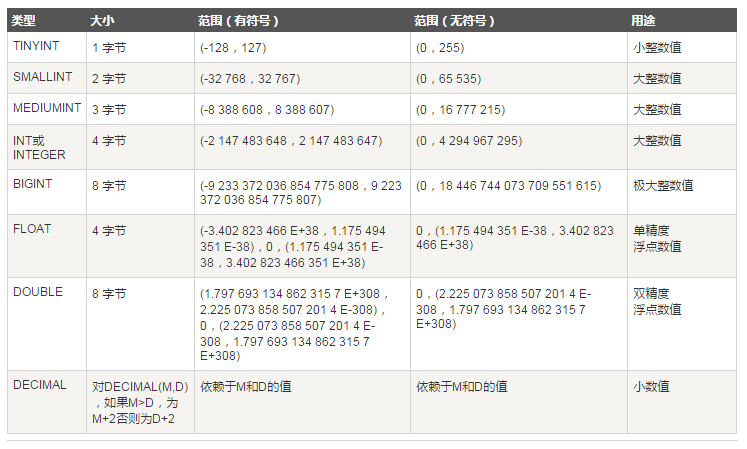
PS:数值类型后的长度只是显示长度,不影响精度。而字符串后面的长度,限制了字符串的最大字符书。例如:int(4) insert 19999,select 仍是19999
(5)函数
- 四舍五入:(round(x,y))进位 truncate(x,y)直接舍去小数点后y位 不进位
- 计算字符长度:char_length(str) 字符串自负的个数length(str)字符串字节个个数(不同编码下,不同)
- 删除空格:ltrim(str) rtrim(str)删除左右空格trim(str)删除开头结尾空格
- 合并字符串:concat(s1,s2…..)字符串直接相连concat(x,s1,s2…..)字符串间用x相连
- 格式化函数:format(x,n)四舍五入format(N,frombase,tobase)不同进制之间的转换
- 获取日期:月month(date)周几dayname(date)一年的第几周week(date)一周内的第几天dayofweek() 一年内的第几周weekofyear()
- 条件判断:if(expr,v1,v2) ifnull(v1,v2)v1是null则v2否则v1
- 获取最后一个自动生成id值的函数:last_insert_id 返回最后一个insert或update为auto_increment设置的第一个发生的值,一次性插入多个值时,返回第一个
(6)查询(数据库最重要的部分)
基本格式:
select col1.col2....
from table1,table2.....
where condation1 and condation2......
group by col1,col2.....//和oracle不同,出现在select列表中的字段,如果没有在组函数中,那么必须出现在group by 子句中,mysql不要求
having condation21 and condation22...
order by col1,col2..... [desc|asc]
limit n- in/not in: in/not in(1,2,3)满足集合中的任何一个元素均可
- like: %匹配任意长度的字符,包括0;_匹配任意一个字符
- is null/is not null:是否为空
- distinct:限制结果集不重复,所有列的组合不重复,作用于记录
having:where用来过滤查询记录,having用来过滤查询分组
内链接:只查询出符合表连接条件的记录。
- 外连接:不符合表连接条件的记录也会被查出。左右连接 left join和right join
- 子查询:select .. from ….where col in (select…….)/select .. from
(select…….)where condation - any:select .. from ….where col>any (select…….)只要大于子查询的任何一条记录均可以
- all:select .. from ….where col>any (select…….)只要大于子查询的所有记录才可以
- exists:select .. from ….where col exists
(select…….)只要在子查询的所有记录才可以 - union /union:select ……. union select…… 两个查询结果和并去重/union
all 不去重 regexp:正则表达式,^匹配文本的开始字符,在最前(^ab);$匹配文本的结尾字符在最后(ab\$);.
匹配任何一个单个字符;*匹配任何个字符;+匹配前一个字符一次或多次;[字符串集合]匹配集合内的任意一个元素; [^]
匹配不在集合内的任意一个元素;字符串{n,m}匹配字符串最少n次,最多m次
PS:limit和order by 顺序问题,limit应在order之后,否则报错。
(7)增删改
插入:insert into table (cols)values(values)(values)/insert into
table(values)values必须包含所有列/insert into table
select………将查询的结果集插入到表中更新:update tablename set
col1name=value1,col2name=value2,col3name=value3 where condation删除: delete from where condation
(8)索引
- 创建索引:在create表时添加,在所有列之后 index indexname(colname(length))/**alter
table** tablename add index indexname(colname(length))**/create
index** indexname on tablename(colname(length)) - 普通索引:只有索引加快数据的查询
- 唯一索引:unique index,索引列值必须唯一,可空,组合唯一索引,所有列的组合唯一
- 单列索引:在某一列上简历索引
- 组合索引:index
indexname(colname(length),colname2….)在多个列上建立索引,索引的使用遵循最左原则,不能使用局部(A,B,C)可用A,(A,B),(A,B,C),其他均不可用 - 全文索引:fulltext,只有MyISAM引擎支持,且char,varchar和text类型的字段,适合用于大字段
(9)存储过程
基本格式:
create procedure proc_name(in|out parm1 type,in|out parm1 type)
begin
.......//表达式或者sql语句
end为了能够知道存储过程的结束,和sql语句的分号区别,定义存储过程前,先使用delimiter // 定义//为结束字符串,定义完后一定要忘记delimiter ;改回结束标记;
- 声明变量:declare var1 int; set var1 = 表达式。
- if语句:
if 表达式 then 表达式:
else if 表达式;
.................
else 表达式;
end if;- case语句:
case 表达式或变量
when value then 表达式;
when value then 表达式;
when value then 表达式;
.................
else 表达式;
end case;- loop语句:
loop_lable:loop
表达式....
end loop loop_lable //loop_lable可以表示结束的哪一个loop,循环嵌套问题- leave语句:
loop_lable:loop
if n=0 then leave; //跳出循环,类似break
end loop loop_lable - iterate语句:
loop_lable:loop
if n<0 then iterate loop_lable; //iterate lable 用来跳转到lable表示的位置 类似continue
end loop loop_lable
- repreat语句:
repeat_lable:repeat
表达式。。。;
until 表达式
end repeat repeat_lable- while语句:
while_lable:while 表达式 do
表达式.....
end while while_lablePS:调用存储过程:call proc_name(param);
(10)触发器
create trigger trigger_name before|after insert|update|delete on table_name for each row begin 表达式….. end
在什么时候什么事件触发触发器,执行表达式。
(11)性能优化
分析查询语句 explain +select语句,查看索引等使用情况
优化查询:
- like:模糊查询会导致索引失效,但是前缀确定可以使用
- 多列索引:只用不正确会导致索引不被使用。最左前缀
- or:表达式1 or 表达式2 同时有索引时才起作用
- 子查询:子查询会临时生成临时表,外层循环从临时表里取数据,查询完后,临时表销毁。由此,开销会增大。尽量使用join。
优化结构:
- 将多字段表拆分成多个表,不经常使用的字段放在一个表中,减少数据量,优化速度。
- 增加中间表,将经常需要多表查询的且数据量不是很大的数据,可以放在一个表里,优化查询速度
- 增加冗余字段,减少多表的join
(12)主从数据库复制
补充
(13)事务
(不知道为什么,没有事务的相关的知识,个人找了一些,看了一些。大体总结一下)
(1)在执行sql语句之前,我们要开启事务 start transaction;
(2)正常执行我们的sql语句
(3)当sql语句执行完毕,存在两种情况:
1,全都成功,我们要将sql语句对数据库造成的影响提交到数据库中,committ
2,某些sql语句失败,我们执行rollback(回滚),将对数据库操作赶紧撤销
mysql> start transaction; //开启事务
Query OK, 0 rows affected (0.00 sec)
mysql> update bank set money=money+500 where name='shaotuo';
Query OK, 1 row affected (0.00 sec)
Rows matched: 1 Changed: 1 Warnings: 0
mysql> update bank set moey=money-500 where name='laohu';
ERROR 1054 (42S22): Unknown column 'moey' in 'field list'
mysql> rollback; //只要有一个不成功,执行rollback操作
Query OK, 0 rows affected (0.01 sec)
一个事务是一个连续的一组数据库操作,就好像它是一个单一的工作单元进行。换言之,永远不会是完整的事务,除非该组内的每个单独的操作是成功的。如果在事务的任何操作失败,则整个事务将失败。
2.个人的感
这本书的确很基础,花的时间不多就看完了,打基础用很好,但是很多知识不是很深入,比如索引,索引在数据库中的实现,比如sql,sql语句的一个执行顺序,比如sql的优化,个人觉得这块有很多可以说的,接下来准备找本比较深入的书肯一下。总之,基础,不错。















 3647
3647

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









