







 本文详细介绍了B-树、B+树和红黑树的数据结构,重点阐述了它们的定义、查找算法、插入与删除操作。B-树适用于大规模文件的查找,B+树则改进了B-树,所有叶子节点形成有序链表,而红黑树是一种自平衡二叉查找树,确保了查找、插入和删除的效率。
本文详细介绍了B-树、B+树和红黑树的数据结构,重点阐述了它们的定义、查找算法、插入与删除操作。B-树适用于大规模文件的查找,B+树则改进了B-树,所有叶子节点形成有序链表,而红黑树是一种自平衡二叉查找树,确保了查找、插入和删除的效率。
B-树
前面介绍的查找算法都在内存中进行的,它们适合用于较小的文件,而对于较大的、存放在外存的文件就不合适,对于此类较大规模的文件,即使是采用了平衡二叉树,在查找效率上仍然较低。例如若将存放在外存的10亿条记录组织为平衡二叉树,则每次访问记录需要进行约30次外存访问;而若采用256阶的B-树数据结构,则每次访问记录需要进行的外存访问次数为4到5次。
B-树的定义
B-树是一种平衡的多路查找树,在文件系统中,B-树已经成为索引文件的有效结构,并得到了广泛的应用研究。
一颗m阶的(m≥3)的B-树,或为空树,或满足以下特性:
树中的每个结点至多有m棵子树
若根结点不是叶子结点,则至少有两棵子树
所有非终端结点中包含下列信息:(n, P0, K1, P1, K2……Kn, Pn)
其中,Ki(1≤i≤n)为关键字,且K i < K i+1;Pj所指子树中所有结点的关键字值均小于K j+1,大于K j。n([m/2] - 1 ≤ n ≤ m-1)为关键字个数,n+1为子树个数除根结点外的所有非终端结点至少有[m/2]棵子树,也即至少应有[m/2]-1个关键字
所有的叶子结点出现在同一层次上,并且不带信息(可以看作是外部结点或查找失败的结点,实际上这些结点不存在,指向这些结点指针为空)
如下图为8个非终端结点、14个叶子结点和13个关键字组成的4阶的B-树示意图:
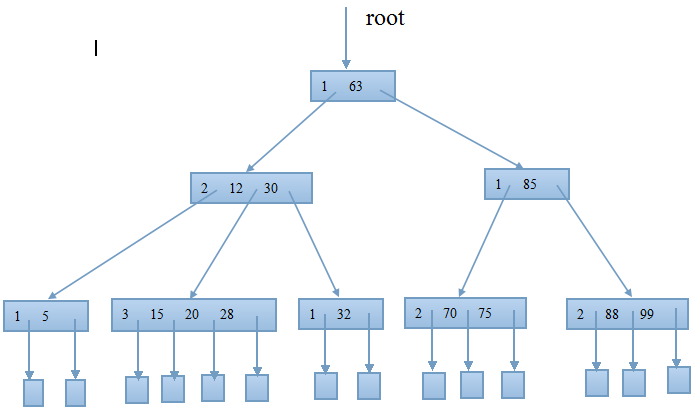
在一棵4阶的B-树中,每个结点关键字个数最少为[m/2] - 1”=1,最多为m-1=3;每个结点的子树数目最少为[m/2]=2,最多为m=4
基于B-树的查找算法
B-树又称为多路查找树,在B-树中查找一个关键字值=给定值key的具体过程是
首先在根结点的关键字序列(key1,key2,key3……keyn)中查找,由于这个关键字序列是有序的,因此既可采用顺查找,也可采用二分查找;若无匹配,(假设key i < key < key i+1),此时应沿着pi指针所指的结点继续在相应的子树中查找。
需要说明的是,B-树经常用于外部文件的查找,某些子树未常驻内存,因为查找过程需要从外存中读入内存,读盘次数与待查找的结点在树中的层次有关,但最多不会超过树的深度,而在内存查找所需的时间与结点中关键字的个数密切相关。
因为在外存上读取结点比在内存中进行关键字查找耗时多,所以在外存上读取结点的次数,即B-树的层次树是决定B-树查找效率的首要因素。
㏒m (n+1) ≤ h ≤ ㏒[m/2] (n+1)/2 + 1,若当n=10000,m=10时,B-树的深度在5-6之间。
[BTree_1
package Search;
class Node<T> {
private int keyNum; // 关键字个数域
private boolean isLeaf;  最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









