







目录
知识点:
1.numpy数组的创建:简单创建、随机创建、遍历、运算
2.numpy数组的索引:一维、二维、三维
3.SHAP值的深入理解
NumPy数组操作与SHAP值解析学习笔记
一、NumPy数组创建与操作
1.1 数组创建方法
简单创建
import numpy as np
# 从列表创建
arr1 = np.array([1, 2, 3, 4])
# 特殊数组
zeros = np.zeros(5) # [0., 0., 0., 0., 0.]
ones = np.ones((2,3)) # 2行3列全1数组
empty = np.empty((3,2)) # 未初始化的数组(内容随机)
identity = np.eye(3) # 3x3单位矩阵
range_arr = np.arange(10) # [0,1,2,...,9]随机创建
# 均匀分布
rand_uniform = np.random.rand(2,4) # 2x4数组,[0,1)均匀分布
# 正态分布
rand_normal = np.random.randn(3,3) # 3x3标准正态分布
# 随机整数
rand_int = np.random.randint(1, 10, size=(3,2)) # [1,10)的3x2随机整数
# 固定随机种子
np.random.seed(42) # 保证结果可复现1.2 数组遍历与运算
遍历方式
arr = np.array([[1, 2], [3, 4]])
# 普通遍历
for row in arr:
for element in row:
print(element)
# nditer高效遍历
for x in np.nditer(arr):
print(x)
# 枚举索引
for idx, val in np.ndenumerate(arr):
print(f"索引{idx}的值是{val}")数学运算
a = np.array([1, 2, 3])
b = np.array([4, 5, 6])
# 基本运算(按元素)
print(a + b) # [5 7 9]
print(a * b) # [4 10 18]
print(a ** 2) # [1 4 9]
# 矩阵乘法
mat1 = np.array([[1,2],[3,4]])
mat2 = np.array([[5,6],[7,8]])
print(mat1 @ mat2) # 矩阵乘法二、NumPy数组索引
2.1 一维数组索引
arr = np.array([10, 20, 30, 40, 50])
# 基础索引
print(arr[0]) # 10
print(arr[-1]) # 50 (最后一个元素)
# 切片
print(arr[1:4]) # [20, 30, 40]
print(arr[::2]) # [10, 30, 50] (步长2)2.2 二维数组索引
arr = np.array([[1,2,3], [4,5,6], [7,8,9]])
# 单元素
print(arr[0, 1]) # 2 (第0行第1列)
# 整行/整列
print(arr[1]) # [4,5,6] (第1行)
print(arr[:, 2]) # [3,6,9] (第2列)
# 高级索引
print(arr[[0,2], [1,0]]) # [2,7] (取(0,1)和(2,0)位置元素)2.3 三维数组索引
arr = np.array([[[1,2], [3,4]], [[5,6], [7,8]]])
# 索引结构:depth/row/column
print(arr[0, 1, 0]) # 3 (第0个二维数组的第1行第0列)
# 切片
print(arr[:, 0, :]) # [[1,2], [5,6]] (所有二维数组的第0行)三、SHAP值深入解析
3.1 SHAP核心概念
Shapley值特性
-
可加性:所有特征的SHAP值之和等于预测与平均预测的差
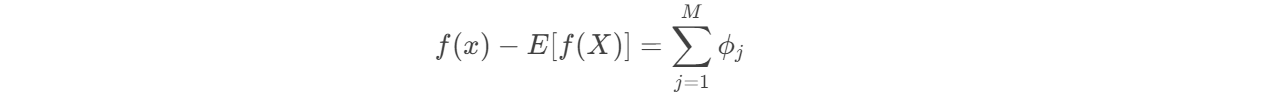
-
对称性:贡献相同的特征应获得相同的SHAP值
-
零贡献:不影响预测的特征SHAP值为0
计算原理
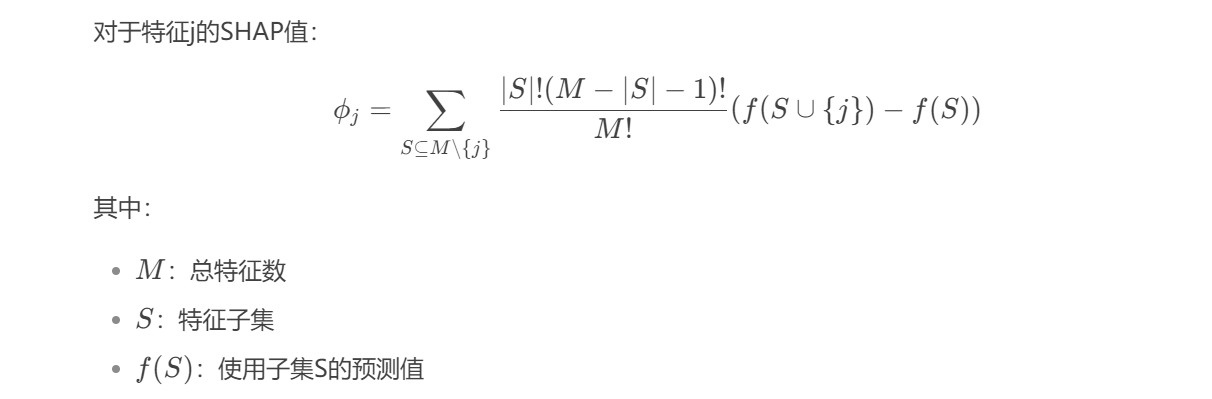
3.2 SHAP可视化实践
特征重要性分析
import shap
# 创建解释器
explainer = shap.TreeExplainer(model) # 树模型专用
shap_values = explainer.shap_values(X_test)
# 摘要图
shap.summary_plot(shap_values, X_test)单个预测解释
# 选取特定样本
sample_idx = 10
# 决策力图
shap.force_plot(
explainer.expected_value,
shap_values[sample_idx],
X_test.iloc[sample_idx]
)
# 瀑布图
shap.plots._waterfall.waterfall_legacy(
explainer.expected_value,
shap_values[sample_idx],
feature_names=X_test.columns
)3.3 SHAP高级应用
交互作用分析
# 计算交互值
shap_interaction = explainer.shap_interaction_values(X_test[:100])
# 可视化两个特征的交互
shap.dependence_plot(
("age", "income"),
shap_interaction,
X_test[:100]
)模型诊断
# 检查特征线性关系
shap.dependence_plot("age", shap_values, X_test)
# 识别异常预测
shap.plots.scatter(shap_values[:,-1]) # 查看最后一个特征的SHAP分布四、关键对比总结
NumPy索引方式对比
| 索引类型 | 语法示例 | 适用场景 |
|---|---|---|
| 基础索引 | arr[0] | 获取单个元素 |
| 切片索引 | arr[1:4] | 获取连续子集 |
| 布尔索引 | arr[arr > 0] | 条件筛选 |
| 花式索引 | arr[[0,2]] | 非连续选择 |
| 多维索引 | arr[0,1] | 矩阵/张量数据 |
SHAP解释方法对比
| 方法 | 可视化类型 | 最佳用途 |
|---|---|---|
| summary_plot | 蜂群图 | 全局特征重要性 |
| force_plot | 力图 | 单个预测解释 |
| dependence_plot | 散点图 | 特征效应分析 |
| waterfall_plot | 瀑布图 | 预测值分解 |
| interaction_plot | 热力图 | 特征交互作用 |
五、实用技巧与注意事项
NumPy性能优化
-
避免循环:优先使用向量化操作
# 差: for循环逐个元素计算 # 优: 向量化运算 result = np.sqrt(arr**2 + 1) -
预分配内存:
output = np.empty_like(input) # 预先分配空间 np.multiply(input, 2, out=output) # 指定输出位置 -
使用视图而非拷贝:
view = arr[1:3] # 视图(不复制数据) copy = arr[1:3].copy() # 显式拷贝
SHAP解释注意事项
-
计算成本:
-
树模型使用
TreeExplainer(快速) -
其他模型使用
KernelExplainer(较慢)
-
-
特征相关性:
-
高相关特征可能导致SHAP值不稳定
-
考虑使用
shap.TreeExplainer(feature_perturbation="interventional")
-
-
业务解释:
-
SHAP绝对值大小反映特征重要性
-
符号表示影响方向(正向/负向)
-
需结合领域知识验证合理性
-
六、学习资源推荐
-
NumPy官方文档:
-
交互式教程:
np.info()函数查看详细文档
-
SHAP学习资源:
-
原始论文:《A Unified Approach to Interpreting Model Predictions》
-
GitHub仓库:https://github.com/slundberg/shap
-
可视化示例库:
shap.plots模块文档
-
-
实战练习建议:
-
使用
sklearn.datasets加载标准数据集练习 -
对比不同模型的SHAP解释差异
-
尝试在真实项目中应用SHAP解释业务预测
-


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









