







原文地址:http://geek.csdn.net/news/detail/74130
声明:本文为《程序员》原创文章,未经允许不得转载,更多精彩文章请订阅2016年《程序员》http://dingyue.programmer.com.cn
作者:陈康贤(专访),阿里巴巴技术专家,花名龙隆,著有《大型分布式网站架构设计与实践》一书,擅长Java Web程序设计,长期在淘宝分布式环境下耳濡目染,目前关注于Java高性能程序设计及性能优化,博客地址http://chenkangxian.iteye.com。
责编:钱曙光,关注架构和算法领域,寻求报道或者投稿请发邮件qianshg@csdn.net,另有「CSDN 高级架构师群」,内有诸多知名互联网公司的大牛架构师,欢迎架构师加微信qshuguang2008申请入群,备注姓名+公司+职位。
相对于传统商业模式来说,电子商务带来的变革使人们足不出户便能享受到购物的乐趣,十几二十年前,很难想象几亿中国人能够在双十一一天产生几百亿的消费。同时,大流量带来了高并发的问题,其中针对技术人员尤为突出的是高并发系统的设计,它与普通系统设计的区别在于既要保障系统的可用性、可扩展性,又要兼顾数据一致性,还要处理多线程同步的问题。任何细微问题,都有可能在高并发环境下被无限的放大,直至系统宕机。
操作原子性
原子操作是指不可分割的操作,它要么执行成功,要么执行失败,不会产生中间状态,在多线程程序中,原子操作是一个非常重要的概念,它常常用来实现一些数据同步机制,具体的例子如Java的原子变量、数据库的事务等。同时,原子操作也是常见多线程程序Bug的源头,并发相关的问题对于测试来说,并不是每次都能够重现,因此处理起来十分棘手。比如,大部分站点都有数据count统计的需求,一种实现方式如下:
public class Count {
public int count = 0;
static class Job implements Runnable{
private CountDownLatch countDown;
private Count count;
public Job(Count count,CountDownLatch countDown){
this.count = count;
this.countDown = countDown;
}
@Override
public void run() {
count.count++;
countDown.countDown();
}
}
public static void main(String[] args) throws InterruptedException {
CountDownLatch countDown = new CountDownLatch(1500);
Count count = new Count();
ExecutorService ex = Executors.newFixedThreadPool(5);
for(int i = 0; i < 1500; i ++){
ex.execute(new Job(count,countDown));
}
countDown.await();
System.out.println(count.count);
ex.shutdown();
}
}Count对象中有一个count的int类型属性,Job负责每次给Count对象的count属性做++操作,创建一个有包含5个线程的线程池,新建一个count共享对象,将对象的引用传递给每一个线程,线程负责给对象的count属性++。乍看程序的逻辑没啥问题,但运行的结果却总是不正确,是由于问题出在count.count++上,这里边涉及到多线程同步的问题,此外,其中很重要的一点是count.count++并不是原子操作,当Java代码最终被编译成字节码时,run()方法会被编译成这几条指令[1]:
public void run();
Code:
0: aload_0
1: getfield #17;
4: dup
5: getfield #26; //获取count.
//count的值,并将其压入栈顶
8: iconst_1 //将int型1压入栈顶
9: iadd //将栈顶两int型数值相加,并将结果压入栈顶
10: putfield #26; //将栈顶的结果 //赋值给count.count
13: aload_0
14: getfield #19;
17: invokevirtual #31;
20: return
}要完成count.count++操作,首先需要将count.count与1入栈,然后再相加,最后再将结果覆盖count.count变量。而在多线程情况下,有可能执行完getfield指令之后,其他线程此时执行putfield指令,给count.count变量赋值,这样,栈顶的count.count变量值与它实际值就存在不一致的情况,接着执行完iadd指令后,再将结果赋值回去,就会出现错误。
JDK5.0以后开始提供Atomic Class,支持CAS(CompareAndSet)等一系列原子操作,来帮助我们简化多线程程序设计,要避免上述情况的发生,可以使用JDK提供的原子变量:
public class AtomicCount {
public AtomicInteger count = new AtomicInteger(0);
static class Job implements Runnable{
private AtomicCount count;
private CountDownLatch countDown;
public Job(AtomicCount count,CountDownLatch
countDown){
this.count = count;
this.countDown = countDown;
}
@Override
public void run() {
boolean isSuccess = false;
while(!isSuccess){
int countValue = count.count.get();
isSuccess = count.count.
compareAndSet(countValue, countValue + 1);
}
countDown.countDown();
}
}
public static void main(String[] args)
throws InterruptedException {
……
}
}通过AtomicInteger的compareAndSet方法,只有当假定的count值与实际的count值相同时,才将加1后的值赋值回去,避免多线程环境下变量值被并发修改而导致的数据紊乱。
通过查看AtomicInteger的compareAndSet方法的实现,可以发现它通过调用Unsafe对象的native方法compareAndSwapInt,来完成原子操作[2]:
public final boolean compareAndSet(int expect, int update) {
return unsafe.compareAndSwapInt(this, valueOffset, expect, update);
}而native方法compareAndSwapInt在Linux下的JDK的实现如下[3]:
UNSAFE_ENTRY(jboolean, Unsafe_CompareAndSwapInt(JNIEnv *env, jobject unsafe, jobject obj, jlong offset, jint e, jint x))
UnsafeWrapper("Unsafe_CompareAndSwapInt");
oop p = JNIHandles::resolve(obj);
jint* addr = (jint *) index_oop_from_field_offset_long(p, offset);
return (jint)(Atomic::cmpxchg(x, addr, e)) == e;
UNSAFE_ENDUnsafe_CompareAndSwapInt最终通过Atomic::cmpxchg(x, addr, e)来实现原子操作,而Atomic::cmpxchg在x86处理器架构下的Linux下的JDK实现如[4]:
inline jint Atomic::cmpxchg(jint exchange_value, volatile jint* dest, jint compare_value){
int mp = os::is_MP();
__asm__ volatile(LOCK_IF_MP(%4) "cmpxchgl %1,(%3)"
: "=a" (exchange_value)
: "r" (exchange_value),"a" (compare_value),"r" (dest),"r" (mp)
: "cc", "memory");
return exchange_value;
}通过os::is_MP()判断当前系统是否为多核系统,如果是,在执行cmpxchgl指令前,先通过LOCK_IF_MP宏定义将CPU总线锁定,这样同一芯片上其他处理器就暂时不能通过总线访问内存,保证了该指令在多处理器环境下的原子性。而cmpxchgl指令,则先判断eax寄存器中的compare_value变量值是否与exchange_value变量的值相等,如果相等,执行exchange_value与dest的交换操作,并将exchange_value的值返回。其中,“=a”中=表示输出,而“a”表示eax寄存器,变量前的“r”表示任意寄存器,“cc”表示告诉编译器cmpxchgl指令的执行,将影响到标志寄存器,而“memory”则是告诉编译器该指令需要重新从内存中读取变量的最新值,而非使用寄存器中已经存在的拷贝。
最终,JDK通过CPU的cmpxchgl指令的支持,实现AtomicInteger的CAS操作的原子性。
另一种情况便是数据库的事务操作,数据库事务具有ACID属性,即原子性(Atomic)、一致性(Consistency)、隔离性(Isolation)、持久性(Durability),为针对数据库的一系列操作提供了一种从失败状态恢复到正常状态的方法,使数据库在异常状态下也能够保持数据的一致性,且面对并发访问时,数据库能够提供一种隔离方法,避免彼此间的操作互相干扰。
数据库事务由具体的DBMS系统来保障操作的原子性,同一个事务当中,如果有某个操作执行失败,则事务当中的所有操作都需要进行回滚,回到事务执行前的状态。导致事务失败的原因有很多,可能是因为修改不符合表的约束规则,也有可能是网络异常,甚至是存储介质故障等,而一旦事务失败,则需要对所有已作出的修改操作进行还原,使数据库的状态恢复到事务执行前的状态,以保障数据的一致性,使修改操作要么全部成功、要么全部失败,避免存在中间状态[5]。
为了实现数据库状态的恢复,DBMS系统通常需要维护事务日志以追踪事务中所有影响数据库数据的操作,以便执行失败时进行事务的回滚。以MySQL的innodb存储引擎为例,innodb存储引擎通过预写事务日志[6]的方式,来保障事务的原子性、一致性以及持久性。它包含redo日志和undo日志,redo日志在系统需要的时候,对事务操作进行重做,如当系统宕机重启后,能够对内存中还没有持久化到磁盘的数据进行恢复,而undo日志,则能够在事务执行失败的时候,利用这些undo信息,将数据还原到事务执行前的状态。
事务日志可以提高事务执行的效率,存储引擎只需要将修改行为持久到事务日志当中,便可以只对该数据在内存中的拷贝进行修改,而不需要每次修改都将数据回写到磁盘。这样做的好处是,日志写入是一小块区域的顺序I/O,而数据库数据的磁盘回写则是随机I/O,磁头需要不停地移动来寻找需要更新数据的位置,无疑效率更低,通过事务日志的持久化,既保障了数据存储的可靠性,又提高了数据写入的效率。
多线程同步
同步的意思就是协同步调,按照预定的先后次序来执行,多线程同步指的是线程之间执行的顺序,多个线程并发既访问和操作同一数据,并且执行的结果与访问或者操作的次序有关,表示线程间存在竞争关系,为了避免这种竞争导致错误发生,我们需要保证一段时间内只有一个线程能够操作共享的变量或者数据,而为了实现这种保证,就需要进行一定形式的线程同步。对于线程中操作共享变量或者数据的那段代码,我们称为临界代码段。对于临界代码段来说,有一个简单易用的工具——锁,通过锁的保护,可以避免线程间的竞争关系,即一个线程在进入临界代码段之前,必须先获得锁,而当其退出临界代码段的时候,则释放锁给其他线程。
还是前面Count计数的例子,通过在Java中使用synchronized关键字和锁,实现线程间的同步:
public void run() {
synchronized(count){
count.count++;
}
……
}通过synchronized,能够保证同一时刻只有一个线程修改count对象。synchronized关键字在进过编译之后,会在同步块的前后分别形成monitorenter和monitorexit这两个字节码指令:
……
6: monitorenter
7: aload_0
8: getfield
11: dup
12: getfield
15: iconst_1
16: iadd
17: putfield
20: aload_1
21: monitorexit
……加入关键字后,run()方法反编译成的字节码如上所示,monitorenter和monitorexit这两个字节码都需要一个引用类型的参数,来指明锁定和解锁的对象,如果synchronized明确指定了对象参数,那锁的对象便是这个传入的参数,假如没有明确指定,则根据synchronized修饰的是实例方法还是类方法,找到对应的对象实例或者对应类的Class对象来作为锁对象。在执行monitorenter指令时,首先要尝试获取对象的锁,如果这个对象没有被锁定,或者当前线程已经拥有了该对象的锁,则将锁的计数器加1,相应的,在执行monitorexit指令时,锁的计数器将会减1,当计数器为0时,表示锁被释放。如果获取对象的锁失败了,则当前线程需要阻塞等待,直到对象的锁被释放为止。
另一种方式是使用ReentrantLock锁,来实现线程间的同步。在Count对象中加入ReentrantLock的实例:
private final ReentrantLock lock = new ReentrantLock();然后在count.count++之前加锁,并且,++操作完成之后,释放锁给其他线程:
count.lock.lock();
count.count++;
count.lock.unlock();这样,对于count.count变量的操作便被串行化了,避免了线程间的竞争。相对于synchronized而言,使用ReentrantLock的好处是,ReentrantLock的等待是可以中断的,通过tryLock(timeout, unit),可以尝试获得锁,并且指定等待的时间。另一个特性是可以在构造ReentrantLock的时候使用公平锁,公平锁指的是多个线程在等待同一个锁时,必须按照申请锁的先后顺序来依次获得,synchronized中的锁是非公平的,默认情况下ReentrantLock也是非公平的,但是可以在构造函数中指定使用公平锁。
对于ReentrantLock来说,还有一个十分实用的特性,它可以同时绑定多个Condition条件,以实现更精细化的同步控制:
class BoundedBuffer {
final Lock lock = new ReentrantLock();
final Condition notFull = lock.newCondition();
final Condition notEmpty = lock.newCondition();
final Object[] items = new Object[100];
int putptr, takeptr, count;
public void put(Object x) throws InterruptedException {
lock.lock();
try {
while (count == items.length)
notFull.await();
items[putptr] = x;
if (++putptr == items.length) putptr = 0;
++count;
notEmpty.signal();
} finally {
lock.unlock();
}
}
public Object take() throws InterruptedException {
lock.lock();
try {
while (count == 0)
notEmpty.await();
Object x = items[takeptr];
if (++takeptr == items.length) takeptr = 0;
--count;
notFull.signal();
return x;
} finally {
lock.unlock();
}
}
}这是Oracle官方文档中所提供的关于Condition使用的一个经典案例—有界缓冲区[7]。notFull(非满)和notEmpty(非空)两个条件与锁lock相关联,当缓冲区当前处于已满状态的时候,notFull条件await,执行put操作的当前线程阻塞,并且释放当前已获得的锁,直到take操作执行,notFull条件signal,等待的线程被唤醒,等待的线程需要重新获得lock的锁,才能从await返回,而当缓冲区为空的时候,notEmpty条件await,执行take操作的当前线程阻塞,并且释放当前已经获得的锁,直到put操作执行,notEmpty条件signal,执行take操作的线程才能够被唤醒,并且需要重新获得lock的锁,才能够从await返回。
数据一致性
分布式系统常常通过数据的复制来提高系统的可靠性和容错性,并且将数据的副本存放到不同的机器上,由于多个副本的存在,使得维护副本一致性的代价很高。因此,许多分布式系统都采用弱一致性或者是最终一致性,来提高系统的性能和吞吐能力,这样不同的一致性模型也相继被提出。
- 强一致性要求无论数据的更新操作是在哪个副本上执行,之后所有的读操作都要能够获取到更新的最新数据。对于单副本的数据来说,读和写都是在同一份数据上执行,容易保证强一致性,但对于多副本数据来说,若想保障强一致性,就需要等待各个副本的写入操作都执行完毕,才能提供数据的读取,否则就有可能数据不一致,这种情况需要通过分布式事务来保证操作的原子性,并且外界无法读到系统的中间状态。
- 弱一致性指的是系统的某个数据被更新后,后续对该数据的读取操作,取到的可能是更新前的值,也可能是更新后的值,全部用户完全读取到更新后的数据,需要经过一段时间,这段时间称作“不一致性窗口”。
- 最终一致性是弱一致性的一种特殊形式,这种情况下系统保证用户最终能够读取到某个操作对系统的更新,“不一致性窗口”的时间依赖于网络的延迟、系统的负载以及副本的个数。
分布式系统中采用最终一致性的例子很多,如MySQL数据库的主/从数据同步,ZooKeeper的Leader Election和Atomic Broadcas等。
系统可扩展性
系统的可扩展性也称为可伸缩性,是一种对软件系统计算处理能力的评价指标,高可扩展性意味着系统只要经过很少的改动,甚至只需要添加硬件设备,便能够实现整个系统处理能力的线性增长。单台机器硬件受制于科技水平的发展,短时间内的升级空间是有限的,因此很容易达到瓶颈,且随着性能的提升,成本也呈指数级升高,因此可扩展性更加侧重于系统的水平扩展。
大型分布式系统常常通过大量廉价的PC服务器,来达到原本需要小型机甚至大型机的同等处理能力。进行系统扩展的时候,只需要增加相应的机器,便能够使性能线性平滑提升,达到硬件升级同等的效果,并且不会受制于硬件的技术水平。水平扩展相对于硬件的垂直扩展来说,对于软件设计的能力要求更高,系统设计更复杂,但是却能够使系统处理能力几乎可以无限制扩展。
系统的可扩展性也会受到一些因素的制约,CAP理论指出,系统的一致性、可用性和可扩展性这三个要素,对于分布式系统来说,很难同时满足的,因此,在系统设计的时候,往往得做一些取舍。某些情况下,通过放宽对于一致性的严格要求,以使得系统更易于扩展,可靠性更高。
下面将介绍一个典型的案例,通过在数据一致性、系统可用性以及系统可扩展性之间找到平衡点,来完成瞬间高并发场景下的系统设计。
并发减库存
大部分电商网站都会有这样一个场景——减库存。正常情况下,对于普通的商品售卖来说,同时参与购买的人数不是很多,因此,问题并不那么明显,但是,对于像秒杀活动,低价爆款商品,抽奖活动这种并发数极高的场景来说,情况便显得不同了。比如在活动开始的瞬间,用户的下单和减库存请求将呈爆炸式增长,瞬间的qps可达平时的几千倍,这将对系统的设计和实现带来极大的挑战。
首先要解决的问题,便是杜绝网络投机者使用工具参与秒杀导致的不公平竞争行为,让竞争变得公平。而防止机器请求最原始最简单也是最有效的方式,便是采用图像验证码,用户必须手工输入图片上的字符,才能够进行后续操作,当然,随着技术的发展,简单图像也能够进行识别,因此,验证码技术也在不断演进,为了防止图像识别技术识别验证码字符,可以采用问答式的验证码,如“1+1=?”这样,即便是识别验证码上的字符,也无法自动识别答案。当然,验证码并非是一个完美的解决方案,它会导致系统的易用性降低,用户体验因此而下降。
其次要解决的便是数据一致性的问题,对于高并发访问的浏览型系统来说,单机数据库如不进行扩展,往往很难支撑,因此,常常会采用分库技术,来提高数据库的并发能力,并且通过使用分布式缓存技术,将磁盘磁头的机械运动,转化为内存的高低电平,以降低数据库的压力,加快后端的响应速度,响应得越快,线程释放也越快,能够支持的单位时间内的查询数也越高,并发的处理能力就越强。使用缓存和分库技术,吞吐量的确是上去了,带来的问题便是,跨数据库或者是分布式缓存与数据库之间,难以进行事务操作,由于下单和减库存这两个操作不在同一个事务当中,可能导致的问题便是,有可能下单成功,库存减失败,导致“超卖”的现象发生,或者是下单失败,而减库存成功,而导致“少卖”的现象,并且,在超高并发的情况下,导致这种失败的概率较往常更高,如图1所示。
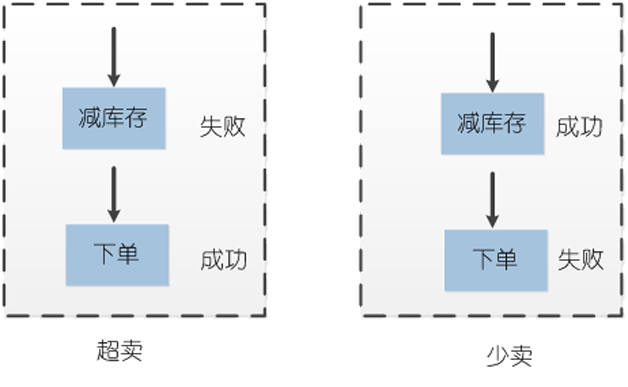
为了避免数据不一致的情况发生,并且,保证前端页面能够在高并发情况下正常浏览,可以采用实际库存和浏览库存分离的方式。由于前端页面验证码以及下单系统的限流保护,因此,真正到达后端系统下单的流量并没有前端浏览系统的流量大,因此,可以将真实的库存保存在数据库,而前端浏览的库存信息存放于缓存,这样,数据库下单与减库存两个动作,可以在同一个事务当中执行,避免出现数据不一致的情况,库存更新完毕以后,再将数据库中数据同步到缓存。
实际库存与浏览库存分离之后,虽解决了数据不一致的问题,但这一措施将引入新的问题。商业数据库如Oracle由于扩展成本太高,大部分互联网企业转而选用开源的MySQL数据库,MySQL根据存储引擎的不同,采用不同的锁策略。MyISAM存储引擎对写操作采用的是表锁策略,当一个用户对表进行写操作时,该用户会获得一个写锁,写锁会禁止其他用户的写入操作。InnoDB存储引擎采用的则是行所策略,只有在对同一行进行写入操作的时候,锁机制才会生效。显而易见,InnoDB更适合于高并发写入的场景。
那么,采用InnoDB存储引擎,对于高并发下单减库存的场景,会带来什么问题呢?每个用户下单之后,需要对库存信息进行更新,对于参与秒杀的热门商品来说,大部分更新请求最终都会落到少量的几条记录上,而行锁的存在,使得线程之间需要进行锁的争夺,一个线程获得行锁以后,其他并发线程就需要等待它处理完成,这样系统将无法利用多线程并发执行的优势,且随着并发数的增加,等待的线程会越来越多,rt急剧飚升,最终导致可用连接数被占满,数据库拒绝服务。
既然记录的行锁会导致无法并发利用资源的问题,那么,可以通过将一行库存拆分成多行,便可以解除行锁导致的并发资源利用的问题。当然,下单减库存操作最终路由到哪一条记录,可以采用多种策略,如根据用户ID取模、随机等,总的库存通过SUM函数进行汇总,再同步到缓存,给前端页面做展现,以降低数据库的压力。
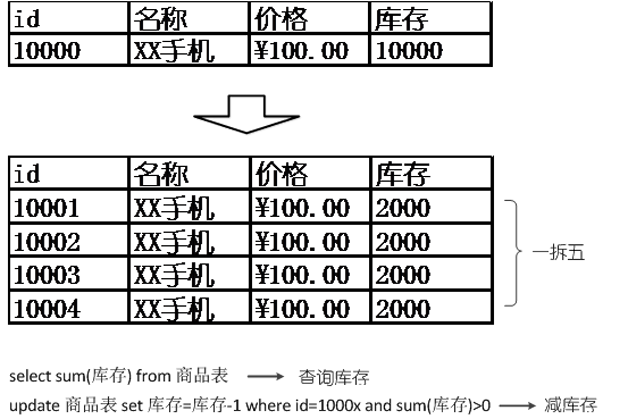
当然,这样也会导致另外一些问题,当总库存大于0的时候,前端的下单请求,可能刚好被路由到一条库存为0的记录,导致减库存失败,而实际此时还有其他记录的库存不为0。
【参考资料】
- 字节码并非最终执行的汇编指令,但是已经足够用来说明原子性问题
- 该段代码来自OpenJDK6的源码,源码下载地址为http://download.java.net/openjdk/jdk6/promoted/b27/openjdk-6-src-b27-26_oct_2012.tar.gz,路径为jdk/src/share/classes/java/util/concurrent/atomic/AtomicInteger.java
- 该段代码来自OpenJDK6的源码,代码的路径为hotspot/src/share/vm/prims/unsafe.cpp
- 该段代码来自OpenJDK6的源码,代码的路径为hotspot/src/os_cpu/linux_x86/vm/atomic_linux_x86.inline.hpp
- 关于数据库事务的介绍可参考http://zh.wikipedia.org/wiki/数据库事务
- 在写入数据之前,先将数据操作写入日志,称为预写日志
- Oracle关于Condition介绍的Java Doc地址。http://docs.oracle.com/javase/6/docs/api/java/util/concurrent/locks/Condition.html















 355
355

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









