







机器学习-linear regression with multiple varibles
参考资料链接:
http://aiku.me/bar/10633755
参考原材料:
Andrew Ng.老师的第四讲pdf课件
目录:
Andrew Ng.老师课件标题列表:
Linear Regression with multiplevarilbles
-Multiple features
-Gradient descent for multiple varibles
-Gradient descent in practice I:Feature Scaling
-Gradient descent in practice II:Learning rate
-Feature and poly nomial regression
-Normal equation
-Normal equation and non-invertibility
Rachel-Zhang“美女”的小标题列表:
(一)、Multiple Features:
(二)、Gradient Descent for Multiple Variables:
(三)、Gradient Descent for Multiple Variables - Feature Scaling
(四)、Gradient Descent for Multiple Variables - Learning Rate
(五)、Features and Polynomial Regression
(六)、Normal Equation
(七)、Normal Equation Noninvertibility
本人理解本章内容的章节标题列表:
-
Multiple Features(多特征)
-Gradient Descent for Multiple Variables(多元的函数的梯度下降)
-Gradient Descent for Multiple Variables - Feature Scaling(多元的函数的梯度下降-维数缩放)
-Gradient Descent for Multiple Variables - Learning Rate(多元的函数的梯度下降-学习率)
-Features and Polynomial Regression(多特征和多项式回归)
-Normal Equation(标准方程)
-
Normal Equation Noninvertibility(标准方程的不可逆)
-个人小结
-补充链接
注:在不同的领域,表达同样的意思采用不同的专业术语。如在数学领域叫“多变量”,而在人工智能的机器学习所采是的“多特征”,这是对训练集来说的。
本人之所以把三个人目录都写出来,主要是为了看自己的跟两个牛人差距,以向两个牛人学习。当然,每个人对同一个问题、同一件事的理解方式、解码编码编码解码方式都各有不同。有自己解码编码习惯。从这方面看,好的解码编码习惯是非常重要的。这也许是牛人特别之一吧。
关于Andrew Ng.授课方式的个人理解与总结:
本章内容的讲解,Andrew Ng.老师运用我们常用的逻辑思维方式,比如类比(单变量线性回归模型与多变量线性回归模型的类比)、对比(梯度下降与标准方程的求解的比较),分析-综合|结论(通过各个方面的分析之后,得出相应的结论)。
类比是知识迁移一种好方法。
对比能够找出两个方法的好坏,然后进行选择。
分析-综合|结论能把复杂的问题分解成小问题,一步一步分析,最终把问题解决。
Andrew Ng.老师分析-综合|结论
分析工具:Octave
分析材料:图像
分析方法:函数与变量变化之间的关系,用图表表示
本人在Andrew Ng.的基础上,采用综合|分析的方法,也就是说先列出结论,再写出分析过程。
摘要:
多变量线性回归模型将一个输入空间(特征)映射到一个输出空间(目标)。从线性系统的角度来看,多变量线性回归模型是一个多维的线性空间变换。相对单变量线性回归模型,多变量线性空间更加复杂,如梯度学习,同时表达的能力更强。两者在变量个数、假设模型表达、梯度计算、学习率的选择和特征选择都有相同之处和不同之处。
一、Multiple Features(多特征)
多变量线性回归模型的输入特征数比单变量线性回归模型的特征多,其参数与也随着变量的增多而增加,参数的个数跟变量的个数一样多。多变量线性回归模型数学表达方式也由“数量”值变成“矢量”,写成了向量的表达形式。
 >>>>>>>
>>>>>>> 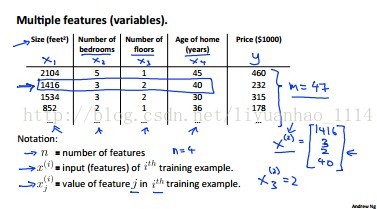
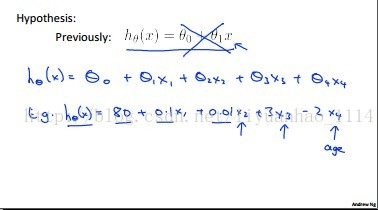 >>>>>>>
>>>>>>> 
二、
Gradient Descent for Multiple Variables(多元的函数的梯度下降)
由于特征的增多,参数的增多,所有它们都被集合在一个向量里面,假设模型h就成矢量形式的模形,对其求梯度的时候,就是对矢量求导(和矩阵理论知识相关连)。代价函数J对各个参数的求导的结果跟单变量线性回归模型的一样,都是等于(相应参数)相应特征乘以估计值(假设模型h相应样本的值)与真值值(相应单个样本目标)之差,然后取均值(整个训练集)。如下图所示:
 >>>>>>>
>>>>>>>
n个变量中的第i个变量就是对应含有n个特征的特征矢量中的第i特征。第i特征对应第i个参数。
三、Gradient Descent for Multiple Variables - Feature Scaling(多元的函数的梯度下降-维数缩放)
个人的看法,之所以对特征(注意是对同一特征,如房子的面积,进行缩放到一定的范围内,是为了防止后面计算的结果太大或者太小不利于计算的存储或者数据的可视化(在Matlab中显示图形时,值在一定范围内更利于分析)。当然,这样做的目的也可能是为了进行模式识别分类。具体情况,请查阅Andrew Ng.老师的Unsupervised Feature Learning and Deep Learning的网上教程。
分子减去均值,分母可以是整个训练集的每个特征的方差、最大值、最小值。如下图所示:



四、Gradient Descent for Multiple Variables - Learning Rate(多元的函数的梯度下降-学习率)
在计算梯度时,学习率大小的选择很重要。学习率大小,那代价函数J收敛到给定的值(取一次迭代代价函数增量的大小)就会很慢,增加了时间的复杂度;学习率太大,那代价函数J将找不到最优值,会发散。


当然,我们开始并不知道选择多大的学习率。我们可以通过猜测一个初始值,一般选择0.001作为初始值,然后根据代价函数与迭代次数变化的关系,再进行选择学习率的大小。根据分析代价函数跟迭代次数的变化关系,得出结果如果学习率初始值大了,那选择学习率初始值的十分之一,其次,选择学习率初始值的三分之一;分析的结果如果是学习率小了,那选择学习率初始值的十倍,其次,选择学习率初始值的三位。以之类推。

五、Features and Polynomial Regression(多特征和多项式回归)
在设计假设模型h的时候,特征数量(即函数中变量的数量)的选择很重要。因为有的变量可以表示其他变量,也就是说其他变量都是这个的函数。如果是这种情况的话,我们选择的假设模型H可以是含有一个变量的多项式。同时,你还得注意你所选择的模型是否跟实际的情况符合,如Rachel-Zhang“美女"据说的。如下图所示:
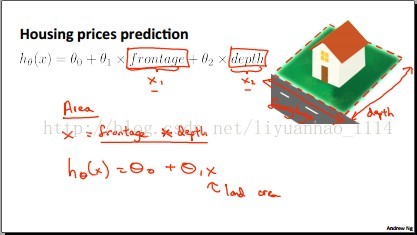
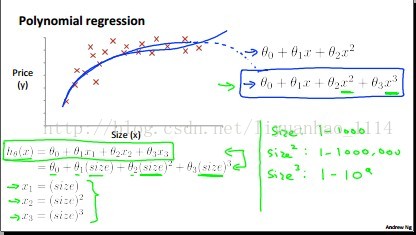
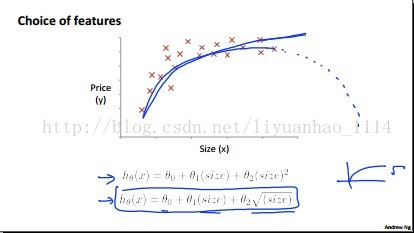
六、Normal Equation(标准方程)
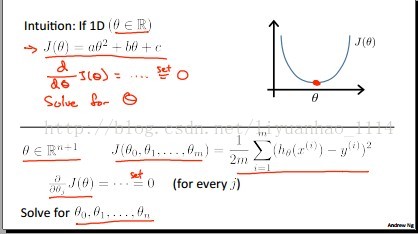
这节主要讲用我们高等数学中的方法求解多元函数最值,即函数导数为零的点是函数的值。
一维的假设模型h跟n维的假设模型比较:
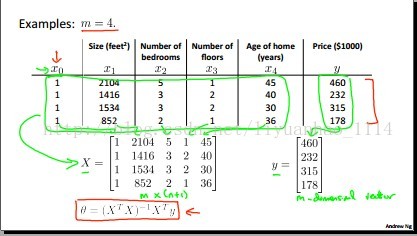
一个具体的例子:
一般的例子:
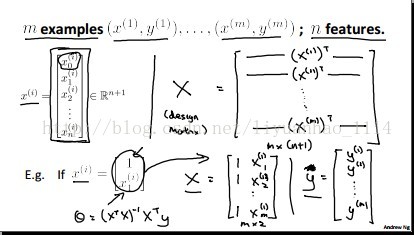
用Octave分析:

梯度下降与标准方程的比较:

七、Normal Equation Noninvertibility(标准方程的不可逆)
参数解当中的矩阵不可逆产生两个结果:
1、特征冗余的(即特征线性相关
2、特征太多(即训练集的数量小于特征数量)
*解决方法:1)去除多余的特征 2)利用正规化
pdf如下:


八、个人小结
本人的博客所采用的pdf页数没有Andrew Ng.老师用的多,这说明自己说的没有老师的详细清楚;而比Rachel-Zhang"美女”的多,这说明自己所采用的pdf没有“美女”用的有针对性,概括性。
九、补充链接














 3449
3449











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









