









一.题目描述
二.解题技巧
这道题和Remove Duplicates from Sorted Array这道题是类似的,只不过这里允许出现重复的数字而已,可以采用二分搜索的变种算法,只不过加入了剔除和第一个元素相同的元素的过程。
另一个思路是加入一个变量,用于记录元素出现的次数。这题因为是已经排序的数组,所以一个变量即可解决。如果是没有排序的数组,则需要引入一个hash表来记录出现次数。
三.示例代码
#include <iostream>
#include <vector>
class Solution
{
public:
int RemoveDuplicatesII(int A[], int n, int dupNum) // dupNum为允许重复的次数
{
if (n < (dupNum + 1)) return n; // 数组元素过少,无需删除重复数据
int num = dupNum; // 存放删除后数组的元素个数,至少有2个元素
for (int i = dupNum; i < n; i++)
{
if (A[i] != A[num - dupNum])
{
A[num++] = A[i]; // 使用不重复元素替换第num个元素的位置
}
}
// 执行算法后,数组A的前num个元素是所求的一个集合
return num;
}
};测试代码:
#include <algorithm>
#include "solution.h"
using namespace std;
int main()
{
int removeTime = 2; // 允许数组中每个元素最多重复的次数
int a[100]; // 定义一个存放100个元素的数组
int n = 100;
for (int i = 0; i < n; i++)
a[i] = rand() % 10 - 5;
sort(a, a + 100); // 要求在执行算法之前数组已经过排序
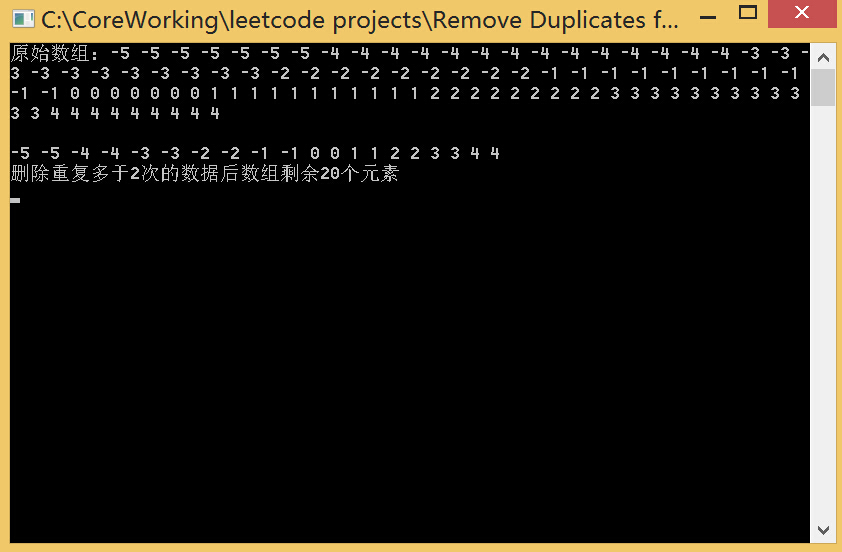
cout << "原始数组:";
for (int j = 0; j < n; j++)
cout << a[j] << " ";
cout << endl << endl;
Solution remove;
int result_num;
result_num = remove.RemoveDuplicatesII(a, n, removeTime);
for (int k = 0; k < result_num; k++) // 数组a中前result_num个元素是处理后的元素
cout << a[k] << " ";
cout << endl;
cout << "删除重复多于" << removeTime << "次的数据后数组剩余" << result_num << "个元素" << endl;
getchar();
return 0;
}一个测试结果:
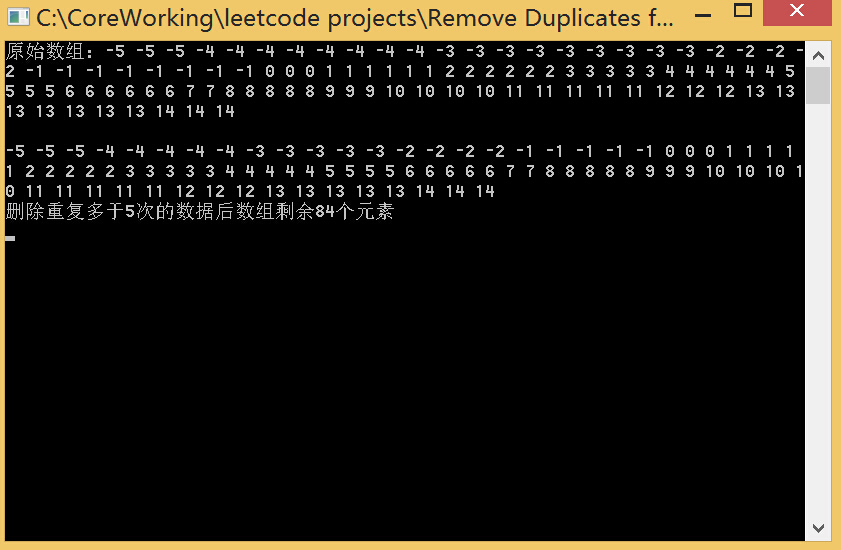
该方法有一定的扩展性,允许元素重复若干次,如以下情况元素允许重复最多5次:
另一种使用二分查找的方法:
class Solution {
public:
int RemoveDuplicatesFromStart(int* A, int n)
{
int NumberOfDuplicates = 0;
int Start = A[0];
for (int Index = 1; Index < n; Index++)
{
if ( Start != A[Index])
{
break;
}
NumberOfDuplicates++;
}
return NumberOfDuplicates;
}
int RemoveDuplicatesFromEnd(int* A, int n)
{
int NumberOfDuplicates = 0;
int Start = A[0];
for (int Index = n - 1; Index > 0; Index--)
{
if (Start != A[Index])
{
break;
}
NumberOfDuplicates++;
}
return NumberOfDuplicates;
}
bool search(int A[], int n, int target)
{
if (n < 1)
{
return false;
}
if (n == 1)
{
if (A[0] == target)
{
return true;
}
return false;
}
if (n == 2)
{
if (A[0] == target)
{
return true;
}
if (A[1] == target)
{
return true;
}
return false;
}
if (A[0] == target)
{
return true;
}
// remove the duplicates
int DuplicatesFromStart = RemoveDuplicatesFromStart(A, n);
if (DuplicatesFromStart == (n - 1))
{
return false;
}
int DuplicatesFromEnd = RemoveDuplicatesFromEnd(A, n);
if (DuplicatesFromEnd == (n - 1))
{
return false;
}
n = n - DuplicatesFromStart - DuplicatesFromEnd;
if (n < 2)
{
return false;
}
A = A + DuplicatesFromStart;
if (A[n / 2] == target)
{
return true;
}
if (A[0] > target)
{
if (A[0] < A[n / 2])
{
return search((A + n / 2), (n - n / 2 ), target);
}
if (A[n / 2] < target)
{
return search((A + n / 2), (n - n / 2), target);
}
return search(A, (n / 2), target);
}
else
{
if (A[0] < A[n / 2])
{
if (A[n / 2] < target)
{
return search((A + n / 2), (n - n / 2), target);
}
return search(A, (n / 2), target);
}
return search(A, (n / 2), target);
}
}
};
四.体会
第一种方法的时间复杂度O(n),空间复杂度O(1),支持in place运算,同时有一定的扩展性。
若采用变种的二分搜索算法,事实上则是加入了剔除和第一个元素相同的元素的过程,加入了这个过程之后,此时在最差情况下的时间复杂度为O(n)。















 86
86

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









