









“CPU执行乱序”是一个常见的话题,鉴于自己一直对这个概念存在些许理解的差池,故今日写一篇文章留作备忘。注,这里仅仅讨论CPU执行乱序,不涉及编译器的乱序。
1.CPU 为什么会乱序?
本质原因是CPU为了效率,将长费时的操作“异步”执行,排在后面的指令不等前面的指令执行完毕就开始执行后面的指令。而且允许排在前面的长费时指令后于排在后面的指令执行完。
如在 CPU0 上执行下面两句话:
a = 1;
b = 2;
在以下情况下 b=2 会先于 a=1 执行完:a 没有缓存于 CPU0 的 cache 上,而 b 缓存于 CPU0 的 cache上,且处于 Exclusive 状态。
在一个 CPU 上写入没有缓存的变量流程如下(该图来源于《cache 一致性》):

CPU0 不能仅仅在它的 cache 里写入 a=1,它还要告诉缓存 a 所在的 CPU:你上面的 a 缓存过期(invalidate)了! 等 CPU0 收到响应(Invalidate Ack)后,才能写入。
这一通信过程是需要耗费时间,而且距离收到 ack 的时间是不确定的,这限制于总线的繁忙程度以及 CPU1 是否在执行优先级高的任务等等。所以CPU0 不能干等着,它要向后继续执行指令:b=2,而 b 位于本 cache 上且处于 Exclusive 状态,可以直接修改b的值(b 变为 Modified 状态)。此时b=2已经执行完毕,而 a=1还没有执行完毕!从时序上来讲,这就是乱序执行。
[知识展开]
MESI 是一种常用的用于保证 CPU 的缓存一致性的协议,规定了位于缓存中的变量在不同时序下处的状态以及经过某些操作相互转化的状态。严格遵守这个协议可以保证缓存一致。这篇文章很好的讲解了MESI
2.CPU 乱序的解决思路?
CPU 执行乱序主要有以下几种:
一.写写乱序(store store):a=1;b=2-------------> b=2;a=1;
二.写读乱序(store load): a=1;load(b); ------------> load(b);a=1;
三.读读乱序(load load): load(a);load(b); -----------> load(b);load(a);
四.读写乱序(load store): load(a);b=2; ------------> b=2;load(a);
C++ 提供的内存模型约束,另一篇文章中提到了,可以灵活地根据需要对内存加以约束,达到强度不同的顺序执行效果,如全局的顺序,局部代码的顺序,逻辑相关的顺序等。这不是本文的重点,本文只笼统的使用读栅栏 lfence 和写栅栏 sfence 这两种约束。先给出现代的 CPU 架构:(该图来源于《cache 一致性》):
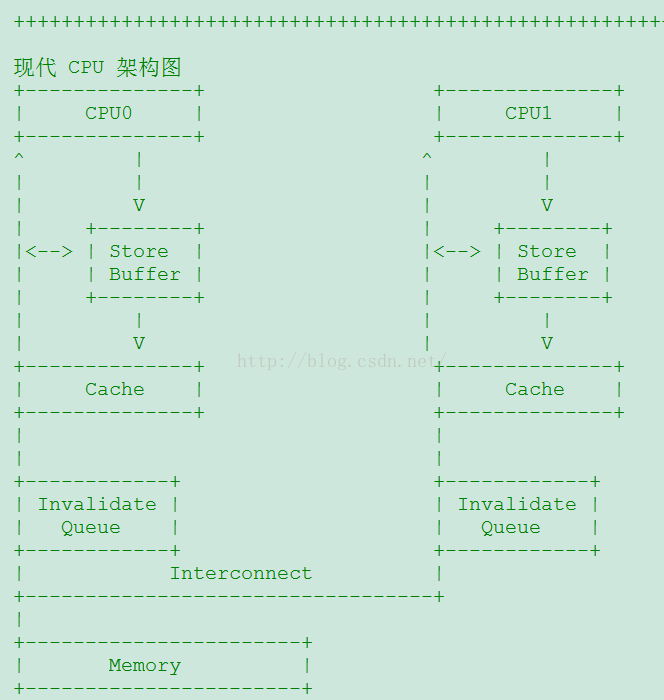
lfence : load fence,即,使得 CPU 应用 invalidate queue,使某个缓存失败,去其它 CPU 同步数据。
sfence: store fence,即,使得 CPU 应用 store buffer ,同步到 cache 中。
下面举例说明这两个内存栅栏的应用。
在不使用内存栅栏的情况下:
CPU0 执行
a = 1;
b = 1;
CPU1 执行
while (b != 1);
assert (a == 1);
CPU1的 assert 有可能会失败:只要 a 不位于 CPU0 的缓存上,b 不位于 CPU1 的缓存上。
CPU0 需要发出 read invalidate 的消息去改写 a 的值,此消息被 CPU1 接受到后立即响应:invalidate ack 并在 invalidate queue 中加入这条消息,但 CPU1 并没有实时处理此消息,而是等到合适的时机再去处理。
CPU1 需要发出 read 的消息去获得 b 的值,此消息被 CPU0 接受到后立即响应 b 的值。
一种导致assert失败的执行顺序如下:
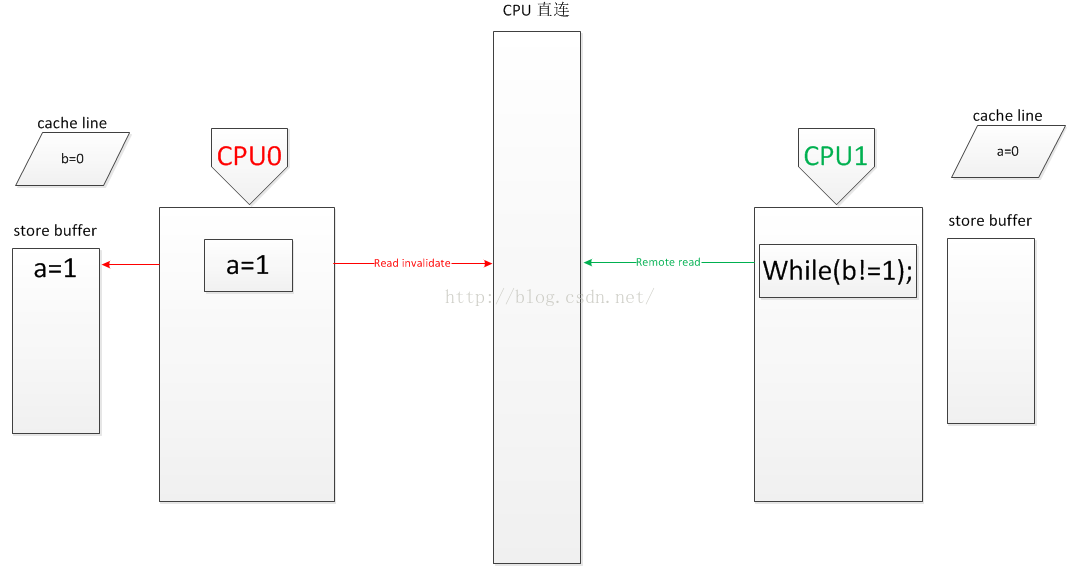
1. CPU0 和 CPU1 同时开始执行 a=1 和 while(b!=1).
CPU0 将 a=1写入 store buffer,发送 read invalidate 消息
CPU1 发送 (remote)read 消息
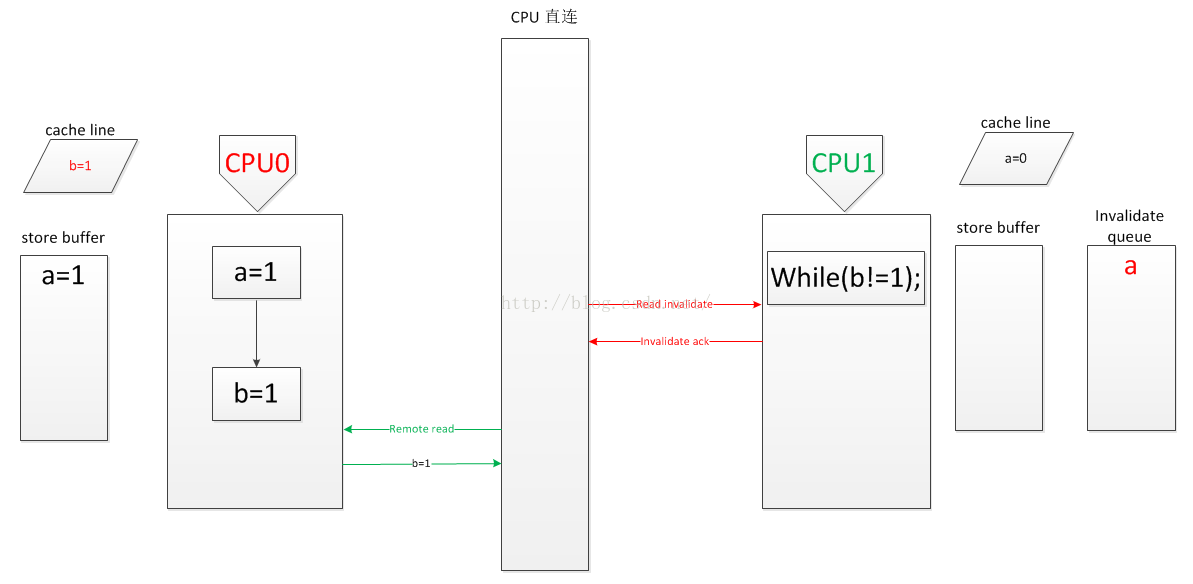
2.CPU0 执行完 b=1后收到 read 消息,CPU1 收到 read invalidate 消息.
CPU0 直接写入 CPU1 的 cache line: b=1
CPU1 在 invalidate queue 中标记 a,表示CPU1中的 a 值无效,返回 invalidate ack
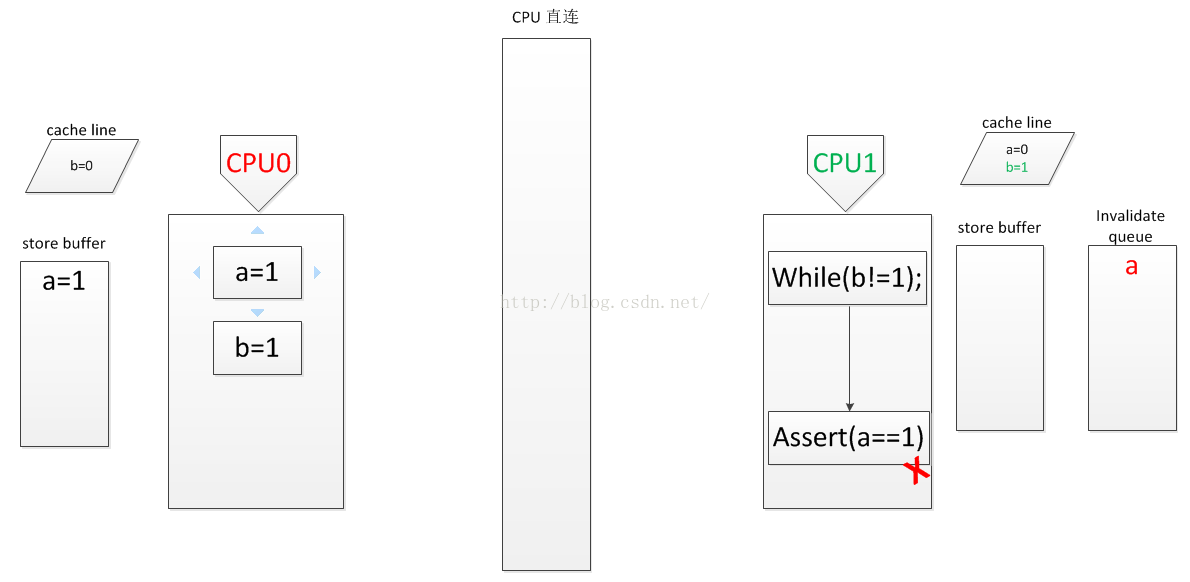
3.CPU0执行完毕;CPU1 取它缓存中的 a=0 执行 assert(a==1),失败
思考上面失败的原因,如果能保证两点即避免:
1.CPU1 在最后 assert(a==1) 时,如果能先去 invalidate queue 中查看到 a 是无效的,再去 CPU0 中请求 a 的最新值,则这一步不会失败。
2.还有一点需要保证:b==1 时必然已经 a==1。这就要求CPU0上的 a==1 的执行效果先于 b==1 上完成。也就是,先写入 a==1,再写入 b==1。
分别针对以上两点:load memory fence 可以保证1,store memory fence 可以保证2.
load memory fence (lfence)做的事情:处理 invalidate queue ,如果有已经失效的值,则重新请求。
store memory fence (sfence)作的事情:处理 store buffer,标记 store buffer 里的值(store buffer 有一个设计特点:如果 store buffer 里面还存在标记的量,则新写入的量不会立即写入到 cache 中[哪怕是此量在 cache 中],而是写入到 store buffer 中,该量不作标记。等到合适的时机,store buffer 被刷入cache 中时,保证先将被标记的量写入 cache,末被标记的量后写入。这就达成了写入有序性)。
于是上面的问题可以这样解决:
CPU0 执行
a = 1;
sfence(); //保证先写入 a,再写入 b
b = 1;
CPU1 执行
while (b != 1);
lfence(); //保证取得最新的 a值。
assert (a == 1);
sfence 具有 release 语义:位于 release 后面的代码不可能比它前面的代码先开始执行。之所以会有该语义,是因为 sfence 操作被强制成同步的操作。必须完成才能继续后面的指令。
lfence 具有 acquire 语义:位于 acquire 前面的代码不可能比它后面的代码后开始执行。之所以会有该语义的原因同上。
3.CPU 存储模型简单解析
简单地分析一下,为什么 CPU 中会有 store buffer 和 invalidate queue。
store buffer
在没有 store buffer 时,CPU 写入一个量,有以下情况。
1.量不在该 CPU 缓存中,则需要发送 read invalidate 信号,再等待此信号返回,之后再写入量到缓存中。
2.量在该 CPU 缓存中,如果该量的状态是 exclusive 则直接更改。而如果是 shared 则需要发送 invalidate 消息让其它 CPU 感知到这一更改后再更改。
这些情况中,很有可能会触发该 CPU 与其它 CPU 进行通讯,接着需要等待它们回复。这会浪费大量的时钟周期!为了提高效率,可以使用异步的方式去处理:先将值写入到一个 buffer 中,再发送通讯的信号,等到信号被响应,再应用到 cache 中。并且,此 buffer 能够接受该 CPU 读值。这个 buffer 就是 store buffer。而不等对某个量的赋值指令的完成,继续下一条指令,去 store buffer 中读该量的值,这种优化叫 store forwarding.
invalidate queue
同理,解决了主动发送信号端的效率问题,那么,接受端 CPU 接受到 invalidate 信号后如果立即采取相应行动(去其它 CPU 同步值),再返回响应信号,则时钟周期也太长了,此处也可优化。接受端 CPU 接受到信号后不是立即采取行动,而是将 invalidate 信号插入到一个 queue中,立即作出响应。等到合适的时机,再去处理这个 queue 中的 invalidate,作相应处理。这个 queue 就是 invalidate queue。
参考文献
深入Java内存模型
http://www.importnew.com/10589.html
深入理解Java内存模型(四)
http://www.infoq.com/cn/articles/java-memory-model-4/
何登成
http://hedengcheng.com/
几种不同的 fence
http://www.cnblogs.com/catch/p/3803130.html
学习load acquire 和store release
http://blog.csdn.net/summerhust/article/details/7406479
leveldb AotmicPointer 实现
http://brg-liuwei.github.io/tech/2014/10/15/leveldb-1.html
leveldb AotmicPointer 实现 2
http://huchh.com/2015/12/03/leveldb-atomicpointer/
store buffer & invalidate
http://www.importnew.com/10589.html
C++ 内存模型
http://blog.csdn.net/pongba/article/details/1659952
CPU cache 文集
http://blog.csdn.net/henzox/article/details/40427463
指令重排举例














 230
230











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









