






将去年年底翻译的书拿出来与大家分享,水平有限,欢迎大家批评指导~
转载请注明出处:http://blog.csdn.net/lonelytrooper/article/details/9959901
第一章 基础
Storm是一套分布式的、可靠的,可容错的用于处理流式数据的系统。处理工作会被委派给不同类型的组件,每个组件负责一项简单的、特定的处理任务。Storm集群的输入流由名为spout的组件负责。Spout将数据传递给名为bolt的组件,后者将以某种方式处理这些数据。例如bolt以某种存储方式持久化这些数据,或者将它们传递给另外的bolt。你可以把一个storm集群想象成一条由bolt组件组成的链,每个bolt对spout暴露出来的数据做某种方式的处理。
为了说明这个概念,这里有一个简单的示例。昨天晚上在我看新闻时,播音员们开始谈论政治家以及他们阵营的各种话题。播音员们一直重复着不同的名字,于是我想知道是否每个名字被提及了相同的次数,或者提到的次数是否有偏重。
把播音员们说的字幕认为成你的数据输入流。你可以让spout来从一个文件(或者套接字,通过HTTP,或者一些其他方法)读取输入。当文本行到达时,spout将它们交给一个bolt,该bolt将文本行流分隔成单词。单词流被传递到另一个bolt,在这个bolt里,每个单词会被与一个预先定义好的政治家名单列表作比较。每作一次比较,第二个bolt会在数据库中增加一次那个名字的计数。当你想查看结果时,你只要查询数据库,该数据库在数据到达时被会实时更新。所有组件的排列(spouts和bolts)及它们的连接被称为一个topology(见图1-1)。
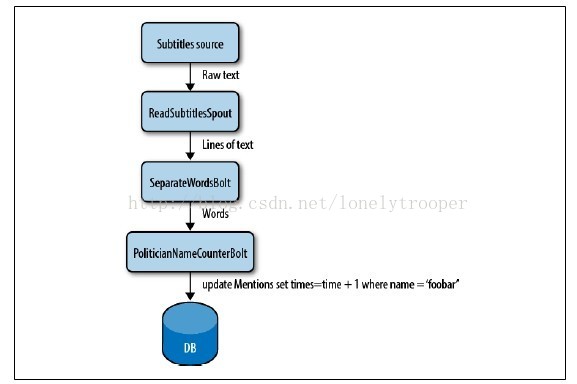
图1-1. 一个简单的topology
设想一下你可以简单地定义整个集群中每个bolt和spout的并行度,这样你就可以无限地扩展你的topology。很神奇,不是吗?尽管这只是一个简单的例子,你已经可以看到storm有多强大。
storm的典型用例有哪些呢?
流处理
正如前述示例中演示的,与其他的流处理系统不同,使用storm不需要中间队列。
持续计算
向客户端持续发送数据,这样它们可以实时更新并显示结果,例如站点度量。
分布式远程过程调用
简单地并行化cpu密集型操作。
Storm组件
在storm集群中,结点被一个持续运行的主结点管理。
Storm集群中有两种结点:主结点和工作结点。主结点运行一个叫做Nimbus的守护进程,它负责在集群内分发代码,为每个工作结点指派任务和监控失败的任务。工作结点运行一个叫做Supervisor的守护进程,它执行topology的一部分。Storm中的topology运行在不同机器的许多工作结点上。
因为storm保存所有集群状态在zookeeper或者本地磁盘上,因此这些守护进程是无状态的,并且可以在对系统健康无影响的情况下失败或者重启(见图1-2)。

图1-2 storm集群的组件
在底层,storm使用了zeromq(Omq,zeromq),一种高级的,可嵌入的、提供极好特性的网络库,这使得storm成为可能。我们列举一下zeromq的一些特性:
﹒充当并行框架的套接字库
﹒比TCP更快速,支持集群产品和超级计算
﹒在进程内、IPC、TCP和多播之间传递数据
﹒异步IO支持可扩展的多核消息传递应用
﹒通过展开、发布订阅、管道、请求应答连接N-to-N

Storm属性
在所有的这些设计理念及决策中,有一些非常好的属性使得storm与众不同。
编程简单
如果你尝试过从头开始构建实时处理系统,你会明白它有多痛苦。通过storm,复杂性被引人注目的减少了。
支持多种编程语言
使用基于JVM的开发语言很容易,但是storm支持任何语言只要你使用或者实现一个小的中间库。
容错
Storm关注worker数量的下降并在必要时刻对任务进行重分配。
可扩展
对于扩展,你所有要做的只是为集群增加更多的机器。Storm会为新机器分配任务当它们可用的时候。
可靠
所有的消息都确保至少处理一次。如果有错误,消息可能会被处理不止一次,但是你永远不会丢失数据。
快速
速度曾是驱动storm设计的关键因素。
事务
对于几乎任何计算,你可以获取确切的一次消息语义。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









