







转载请注明来源:http://blog.csdn.net/loongshawn/article/details/51542309
相关文章:
1、介绍
Apache PDFbox是一个开源的、基于Java的、支持PDF文档生成的工具库,它可以用于创建新的PDF文档,修改现有的PDF文档,还可以从PDF文档中提取所需的内容。Apache PDFBox还包含了数个命令行工具。
Apache PDFbox于2016年4月26日发布了最新的2.0.1版。
备注:本文代码均是基于2.0及以上版本编写。
官网地址:https://pdfbox.apache.org/index.html
PDFBox 2.0.1 API在线文档:https://pdfbox.apache.org/docs/2.0.1/javadocs/
2、特征
Apache PDFBox主要有以下特征:
PDF读取、创建、打印、转换、验证、合并分割等特征。
3、开发实战
3.1、场景说明
1、读取PDF文本内容,样例中为读取体检报告文本内容。
2、提取PDF文档中的图片。这里仅仅实现将PDF中的图片另存为一个单独的PDF,至于需要直接输出图片文件(暂时没有实现),大家可以参考我的代码加以拓展,主要就是处理PDImageXObject对象。
3.2、所需jar包
pdfbox-2.0.1.jar下载地址
fontbox-2.0.1.jar下载地址
将上述两jar包添加到工程库中,如下:
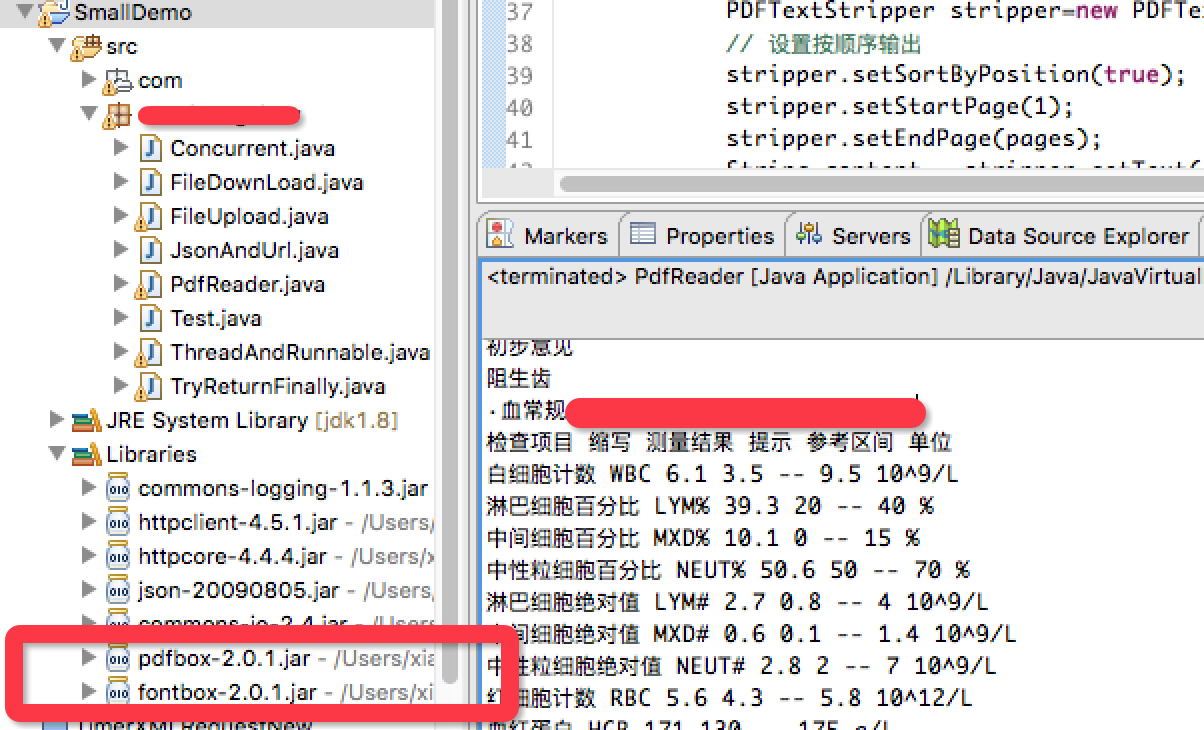
3.3、文本内容提取
3.3.1、文本内容提取
创建PdfReader类,编写下述功能函数。
package com.loongshaw;
import java.io.File;
import java.io.FileInputStream;
import java.io.InputStream;
import 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 5672
5672











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









