







 本文介绍了使用C#进行验证码识别的方法,主要包括样本库加载和字符匹配两个步骤。在样本库加载环节,文章详细说明了样本库的格式和结构。字符匹配部分,略过了图像处理的基础操作,直接进入关键的字符匹配算法讲解。
本文介绍了使用C#进行验证码识别的方法,主要包括样本库加载和字符匹配两个步骤。在样本库加载环节,文章详细说明了样本库的格式和结构。字符匹配部分,略过了图像处理的基础操作,直接进入关键的字符匹配算法讲解。
在这一篇中将讲验证码识别,也就是我们要实现自动化处理的部分。有了前面的知识,这一部分将会变得很容易,下面先说下具体的流程,如下图所示:
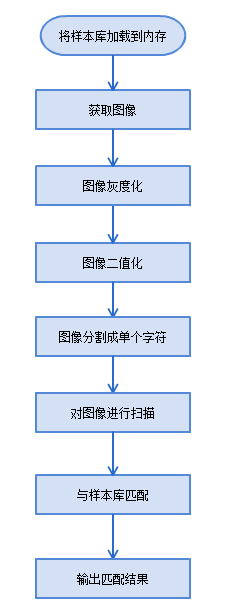
1. 将样本库加载到内存
首先需要再回顾下样本库的格式,如下:

上图中每一个行的第一个数代表图片中的字符,第二个值代表字符的宽度,后面的一连串的数值是字符扫描的结果。每一行所对应的类的结构如下:
public class codeStruct
{
public string character;
public int len;
public ulong[] code;
public codeStruct(string databaseString)
{
string[] stringArray = databaseString.Split(',');
character=stringArray[0];
len=int.Parse(stringArray[1]);
code=new ulong[len];
for(int i=0;i<len;i++)
{
code[i]=ulong.Parse(stringArray[i+2]);
}
}
public override string ToString()
{
string rtn="";
rtn+=character;
rtn+=","+len.ToString();
foreach(ulong number in code)
rtn+=","+number;
return rtn;
}
} public class CodeList: List<codeStruct>
{
public List<codeStruct> GetItem(int length)
{
List<codeStruct> list = new List<codeStruct>();
foreach(codeStruct cs in this)
{
if (cs.len == length)
list.Add(cs);
}
return list;
}
}</pre><pre name="code" class="csharp"> public class Database
{
public CodeList[] codeArray=new CodeList[36];
public Database()
{
for (int i = 0; i < 36; i++)
codeArray[i] = new CodeList();
}
public Database(string filePath)
{
for (int i = 0; i < 36; i++)
codeArray[i] = new CodeList();
StreamReader sr = new StreamReader(filePath);
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 818
818

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









