







 本文详细介绍了Spark中的RDD Transformation函数,包括union、intersection、distinct、groupByKey、reduceByKey、sortByKey、join、cogroup、cartesian和coalesce。这些函数用于数据集的合并、去重、分组、排序、连接和分区调整,是Spark编程中的核心操作。
本文详细介绍了Spark中的RDD Transformation函数,包括union、intersection、distinct、groupByKey、reduceByKey、sortByKey、join、cogroup、cartesian和coalesce。这些函数用于数据集的合并、去重、分组、排序、连接和分区调整,是Spark编程中的核心操作。
作者:周志湖
网名:摇摆少年梦
微信号:zhouzhihubeyond
本文主要内容
- RDD 常用Transformation函数
1. RDD 常用Transformation函数
(1)union
union将两个RDD数据集元素合并,类似两个集合的并集
union函数参数:
/**
* Return the union of this RDD and another one. Any identical elements will appear multiple
* times (use `.distinct()` to eliminate them).
*/
def union(other: RDD[T]): RDD[T] RDD与另外一个RDD进行Union操作之后,两个数据集中的存在的重复元素
代码如下:
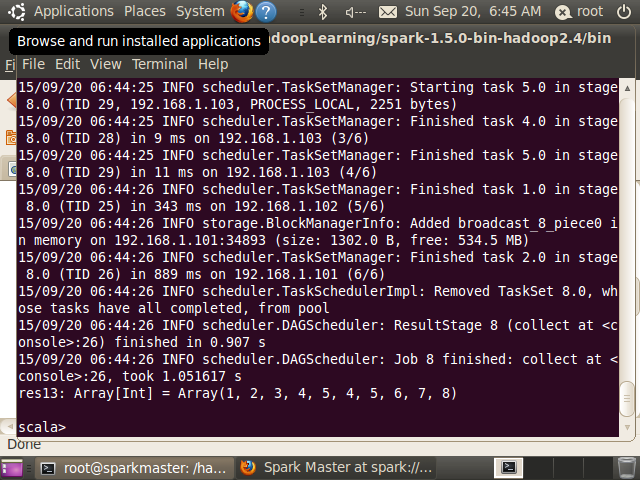
scala> val rdd1=sc.parallelize(1 to 5)
rdd1: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[15] at parallelize at <console>:21
scala> val rdd2=sc.parallelize(4 to 8)
rdd2: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[16] at parallelize at <console>:21
//存在重复元素
scala> rdd1.union(rdd2).collect
res13: Array[Int] = Array(1, 2, 3, 4, 5, 4, 5, 6, 7, 8)
(2)intersection
方法返回两个RDD数据集的交集
函数参数:
/**
* Return the intersection of this RDD and another one. The output will not contain any duplicate
* elements, even if the input RDDs did.
*
* Note that this method performs a shuffle internally.
*/
def intersection(other: RDD[T]): RDD[T]
使用示例:
scala> rdd1.intersection(rdd2).collect
res14: Array[Int] = Array(4, 5)
(3)distinct
distinct函数将去除重复元素
distinct函数参数:
/**
* Return a new RDD containing the distinct elements in this RDD.
*/
def distinct(): RDD[T]
scala> val rdd1=sc.parallelize(1 to 5)
rdd1: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[0] at parallelize at <console>:21
scala> val rdd2=sc.parallelize(4 to 8)
rdd2: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[1] at parallelize at <console>:21
scala> rdd1.union(rdd2).distinct.collect
res0: Array[Int] = Array(6, 1, 7, 8, 2,  最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 787
787

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









