







目录
3.4 说明SparkStreaming下checkpoint的使用场景
8.4 SparkSQL中RDD、DataFrame、DataSet三者的转换
9.4 SparkStreaming有哪几种方式消费Kafka中的数据,它们之间的区别是什么
9.6 SparkStreaming写一个WordCount案例
10 Spark中某个task挂掉了,如何知道是哪个task挂掉了
1 SparkShuffle
Spark Shuffle 分为两种:一种是基于 Hash 的 Shuffle;另一种是基于 Sort 的 Shuffle。
1.1 HashShuffle
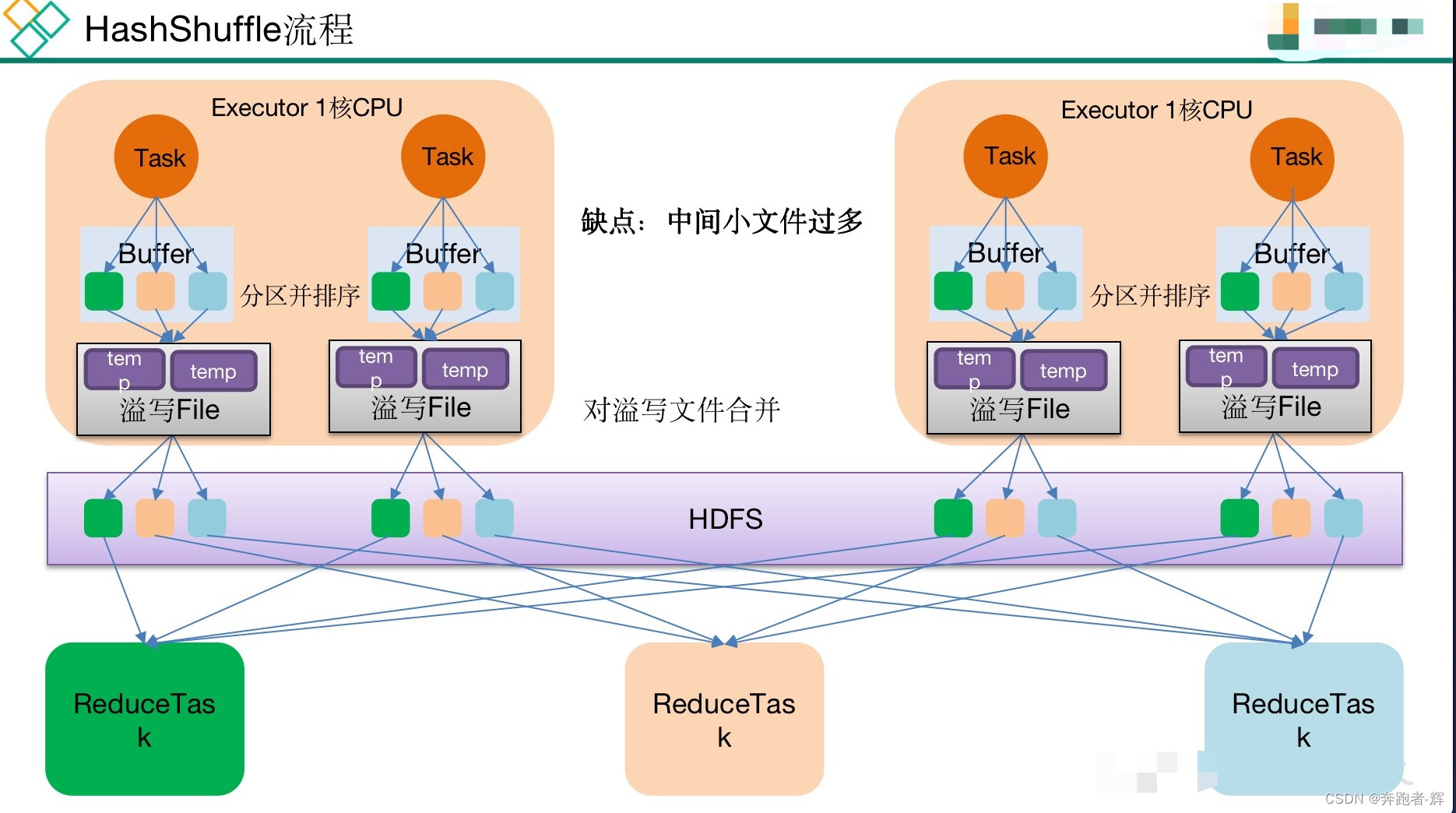
未优化的HashShuffle流程:
① 每1个mapTask将不同结果写到不同buffer中,每个buffer大小为32k,buffer起到数据缓存的作用;
② 每个buffer文件最后对应1个磁盘小文件;
③ reduce task来拉取对应磁盘小文件。
优点:可以省略不必要的排序开销,避免了排序所需的内存开销。
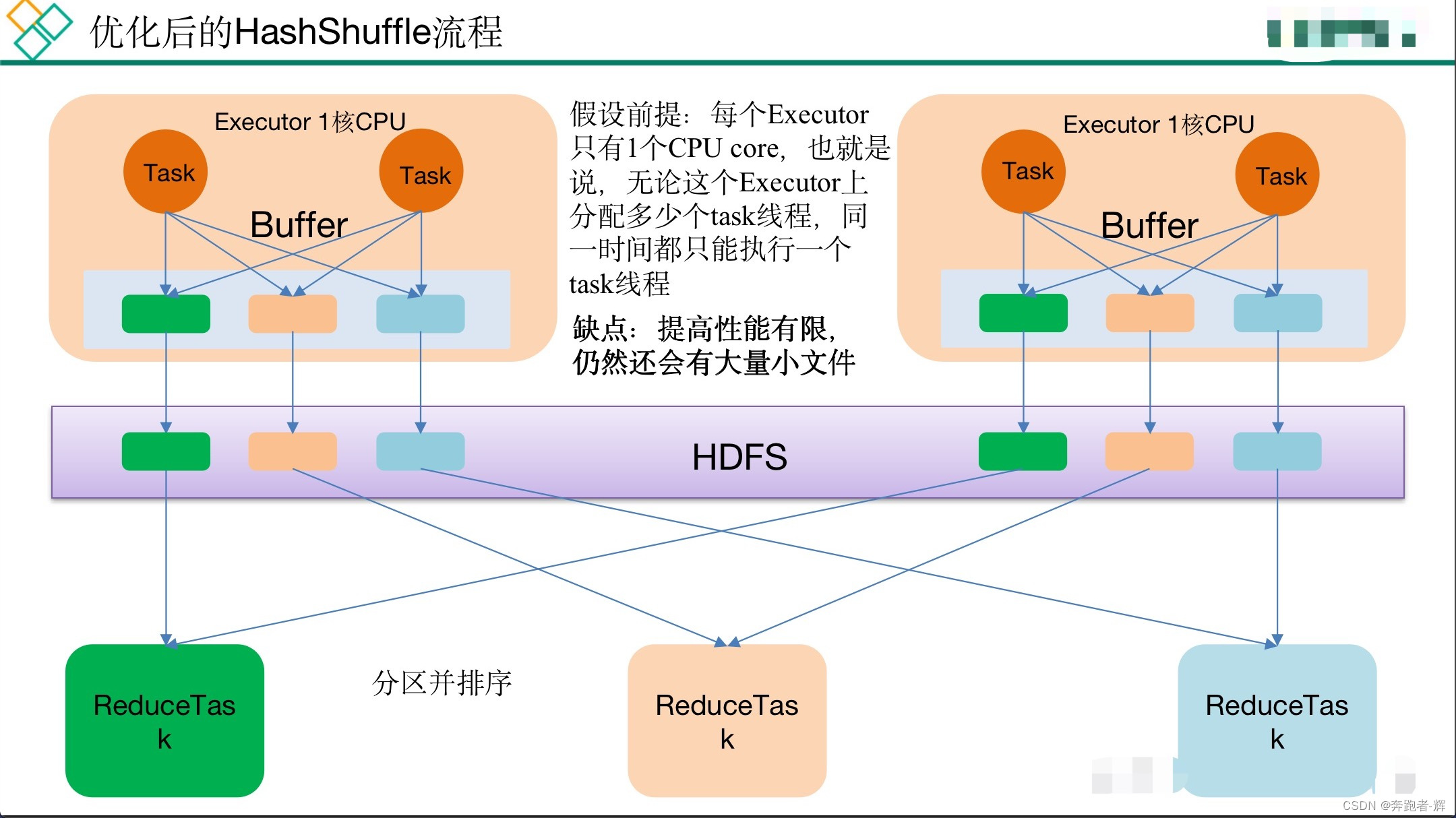
缺点:提高性能有限,仍然还会有大量小文件。
优化后的HashShuffle
1.2 SortShuffle
1.2.1 普通模式
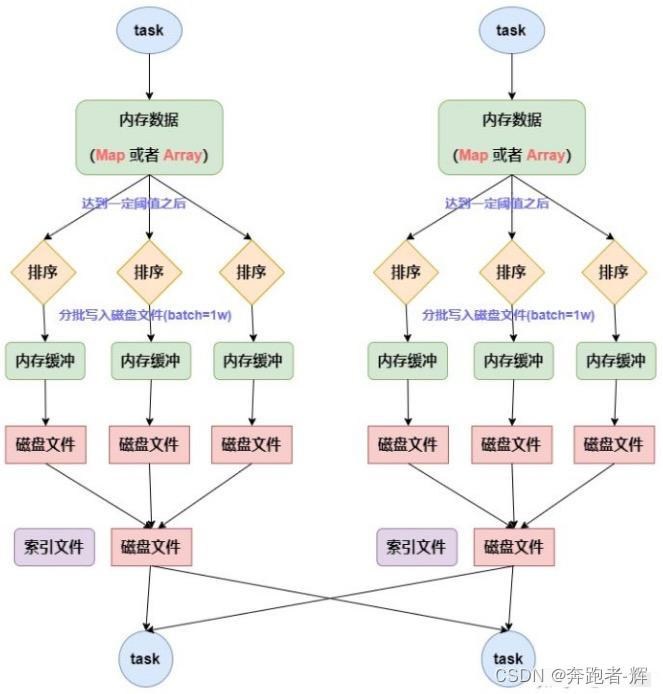
普通的sort shuffle:
① maptask的计算结果会写入到一个内存数据结构里面,内存数据结构默认为5m;
② 在shuffle的时候会有1个定时器,不定期去估算这个内存结构大小;
③ 如果申请成功不会进行溢写,如果申请不成功,这时候会发生溢写磁盘;
④ 在溢写之前内存结构中数据会进行排序分区;
⑤ 然后开始溢写磁盘,写磁盘亿batch的形式写,一个batch里是一万条数据;
⑥ maptask执行完成后,会将这些磁盘小文件合并成一个大的磁盘文件(有序),同时生成一个索引文件;
⑦ reducetask去map端拉取数据的时候,首先解析索引文件,根据索引文件,去拉取数据。
1.2.2 bypass机制
当shuffle read task 的数量小于等于spark.shuffle.sort.bypassMergeThreshold参数的值时(默认为 200),就会启用bypass机制;
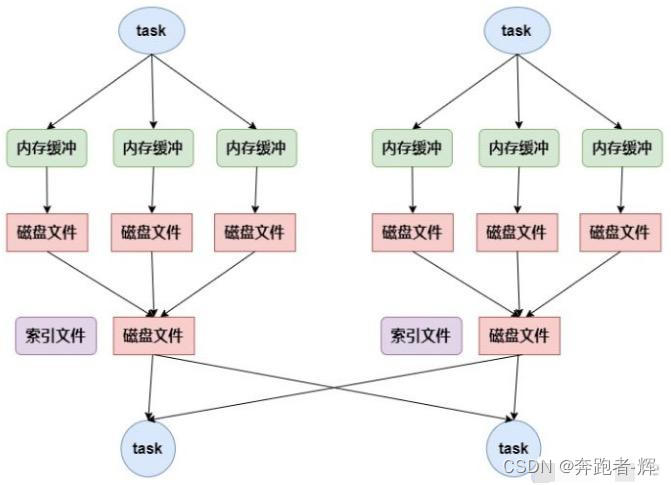
优点:减少了小文件,不排序,效率较高。
2 容错机制
RDD的容错机制又称Lineage(血统)容错,Lineage本质上类似于数据库中的重做日志(Redo Log)
,只不过此重做日志粒度很大,是对全局数据做同样的重做进而来恢复数据。
RDD的Lineage记录的是粗颗粒度的特定数据Transformation操作(如filter、map、join等)
。当这个RDD的部分分区数据丢失时,它可以通过Lineage获取足够的信息来重新运算和恢复丢失的数据分区。
3 Checkpoint
3.1 checkpoint 检查点机制
所谓的检查点其实就是通过将RDD中间结果写入磁盘,由于血缘依赖过长会造成容错成本过高,这样就不如在中间阶段做检查点容错,如果检查点之后有节点出现问题,可以从检查点开始重做血缘,减少了开销。
对RDD进行checkpoint操作并不会马上被执行,必须执行Action操作才能触发。
检查点机制是我们在spark streaming中用来保障容错性的主要机制,它可以使spark streaming阶段性的把应用数据存储到诸如hdfs 等可靠存储系统中,以供恢复时使用。
3.2 checkpoint 与 持久化机制的区别
checkpoint 的数据通常是保存在高可用的文件系统中,比如HDFS中,所以数据丢失可能性极低,稳定性较好;
持久化的数据丢失的可能性更大,因为节点的故障会导致磁盘、内存的数据丢失。
3.3 checkpoint在spark的2块应用
① 在sparkcore中对RDD做checkpoint,将RDD数据保存到可靠性存储(hdfs)以便恢复;
通过将计算代价大的RDD checkpoint一下,当下游RDD计算出错时,可以直接从checkpoint过的RDD那里读取数据继续计算。
② 应用在SparkStreaming中,使用checkpoint用来保存Dstreamgraph以及相关配置信息,以便在Driver崩溃重启的时候能够接着之前进度继续进行处理;
3.4 说明SparkStreaming下checkpoint的使用场景
① 使用场景:有状态的计算 和 容错的恢复;
② Checkpoint里边存的:元数据检查点 和 数据检查点;
③ 何时启动checkpoint检查点: 做状态计算 和 容错恢复时。
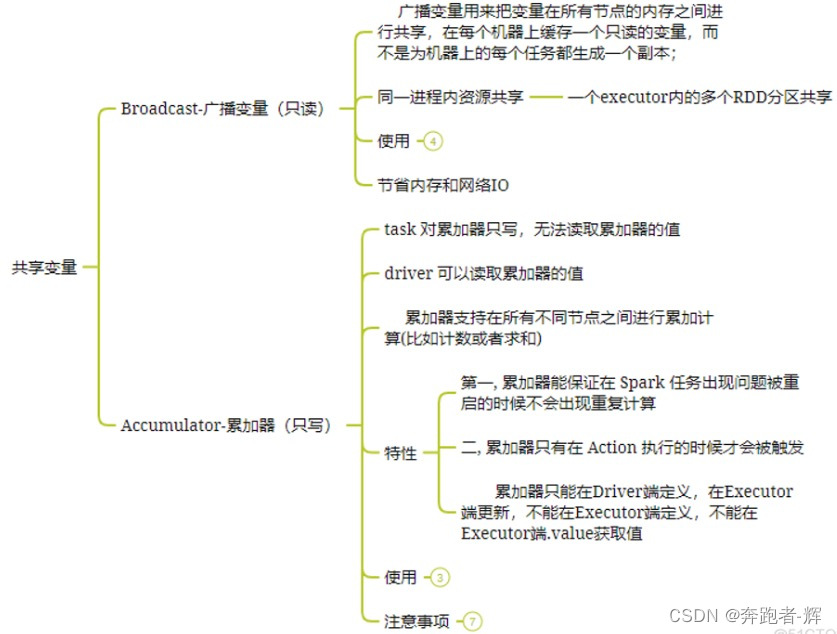
4 广播变量
对于经常用到的变量值,在分布式计算中,多个点检task一定会多次请求这个变量就会产生大量网络IO,会影响效率,这时可以使用广播变量的方式将数据广播到对应Executor端,这个executor启动的所有的task会共享这个变量,节省了通信的成本和服务器的资源。
优点:不用从Driver端拉取数据了,也不用从其它节点拉取数据了,只需要从自己的Executor端获取数据就可以了,减少了网络IO,提高效率。
缺点:数据一旦广播出去,后期数据发生变化,无法同步到Executor端,有些场景下可以使用redis.
注意事项:
① 不能将一个RDD使用广播变量广播出去;
② 广播变量只能在driver端定义,不能在Executor端定义;
③ 在Driver端可以修改广播变量值,在Executor端无法修改广播变量的值。
5 累加器
如果一个变量不被声明为一个累加器,那么它将在被改变时不会在driver端进行全局汇总,即使是在分布式运行中每个task运行的只是原始变量的一个副本,并不能改变原始变量的值。但是当这个变量被声明为累加器后,该变量就会有分布式计数的功能,对数据进行聚合,全局汇总总计。
应用场景:
① 能够准确的统计数据的各种数据;
② 作为调试工具,能够观察每个task信息,通过累加器可以在Spark UI观察到每次task所处理的记录数。
注意事项:
① 累加器在driver端定义赋初值;
② 累加器只能在driver端读取,在executor端更新。
综上,对于广播变量和累加器总结
广播变量:用来高效分发较大的对象。 累加器:用来对信息进行聚合
6 Kryo序列化
Kryo序列化比Java序列化更快更紧凑,但Spark默认序列化是Java序列化并不是Spark序列化,因为Spark并不支持所有序列化类型,而且每次使用都必须进行注册。注册只针对于RDD。在DataFrames和DataSet当中自动实现了Kryo序列化。
7 Spark中数据的本地化方式分为5种
① process_local : 进程本地化 , task计算的数据在当前Executor中, 不同task计算的时候可以共同用这一个数据集,效率高,节省资源;
② node_local : 节点本地化 , task计算的数据在当前节点上,task计算的时候不需要跨节点拉取数据,速度也是比较快的;
③ no_pref : 没有本地化 ,这个方式的意思就是数据不是本地化的数据; 比如我们的MySQL数据库, 如果我们需要的数据在MySQL中 就不牵扯到数据本地化的这个说法;
④ rack_local : task计算所需要的数据在同机架不同节点上, 这种方式中,task计算的数据在不同节点上,就牵扯到网络传输的问题了 ,效率就没有那么高了;
⑤ any : 这种方式就是比较随意的,可能会牵扯到跨机架的数据传输,效率最低;
默认的优先级是从上到下依次降低。
8 SparkSql执行流程
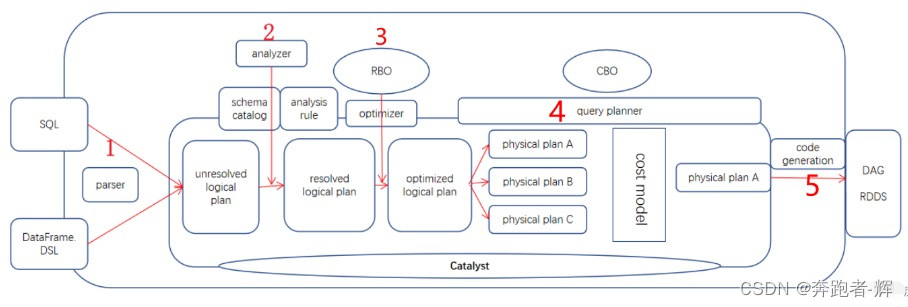
① Parser转换器,第三方类库 Antlr 实现。将 sql 字符串切分成 Token,根据语义规则解析成一颗AST语法树,称为Unresolved Logical Plan 未解决的逻辑计划;
简单来说就是判断 SQL 语句是否符合规范,比如select from where 这些关键字是否写对。就算表名字段名写错也无所谓。
② Unresolved Logical Plan经过Analyzer分析器,借助于表的真实数据元数据 schema catalog,进行数据类型绑定和函数绑定,解析为 resolved Logical Plan 已解决的逻辑计划;
简单来说就是判断 SQL 语句的表名,字段名是否真的在元数据库里存在。
③ Optimizer优化器,基于各种优化规则(常量折叠,谓词下推,列裁剪),将上面的resolved Logical Plan进一步转换为语法树 Optimized Logical Plan 优化的逻辑计划。这个过程称作 RBO(Rule Based Optimizer 基于规则的优化))。
简单来说就是把可执行的SQL 再调整一下,以便跑得更快。
④ query planner 查询计划器,基于 planning 计划过程,将逻辑计划转换成多个物理计划,再根据代价模型 cost model,筛选出代价最小的物理计划。这个过程称之为 CBO(Cost Based Optimizer 基于成本的优化)。
上面2-3-4步骤合起来,就是 Catalyst 优化器。
⑤ 最后依据最优的物理计划,生成 java 字节码,将 SQL 转换为 DAG,以 RDD 形式进行操作。
8.1 RDD 与 SparkSQL 运行时的区别
和 RDD 不同, SparkSQL 的 Dataset 和 SQL 并不是直接生成计划交给集群执行, 而是经过了一个叫做 Catalyst 的优化器, 这个优化器能够自动帮助开发者优化代码。
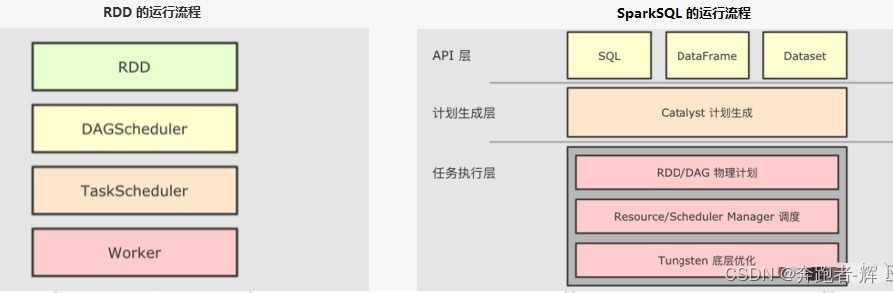
8.2 explain参看逻辑计划和物理计划
- SparkSQL中的DSL方式:
spark.sql('select count(1) from test_db.table1').explain(True)
spark.sql('select count(1) from test_db.table1').explain(True) 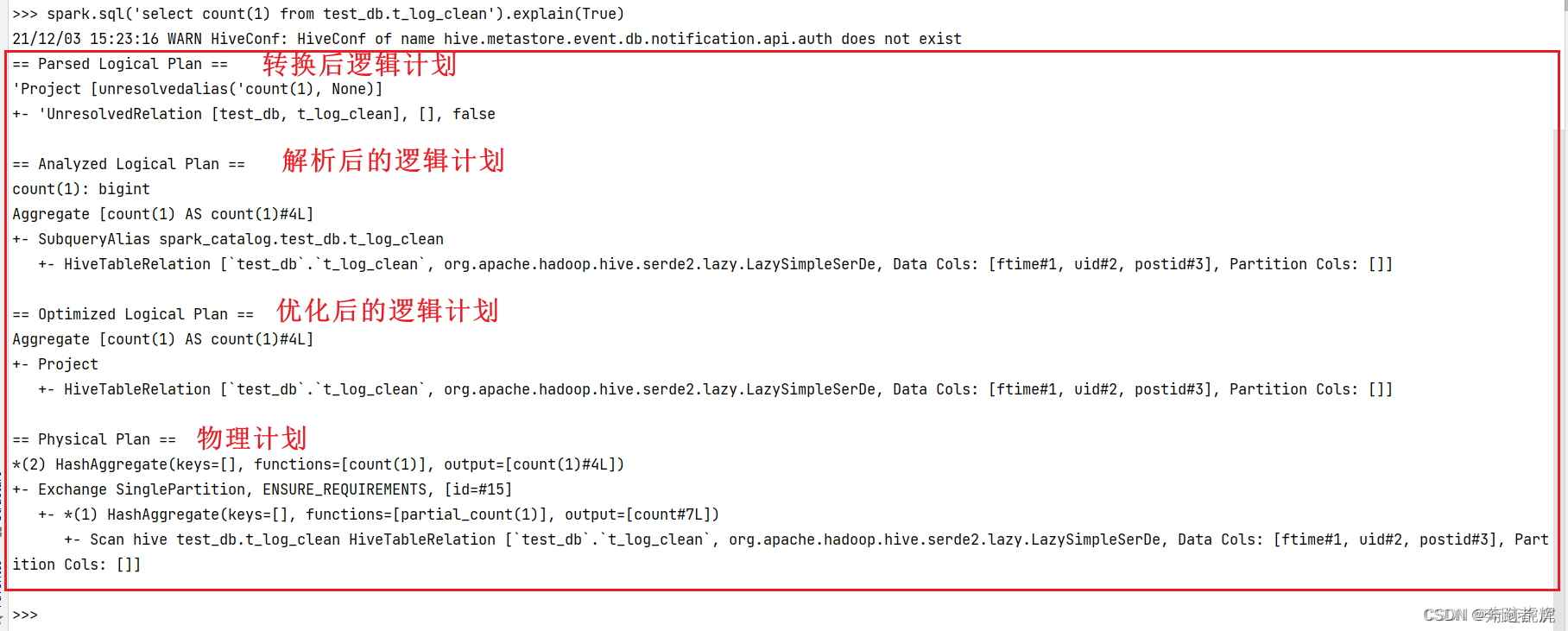
- 普通SQL方式 explain extended select count(1) from table1;
explain extended select count(1) from table1; 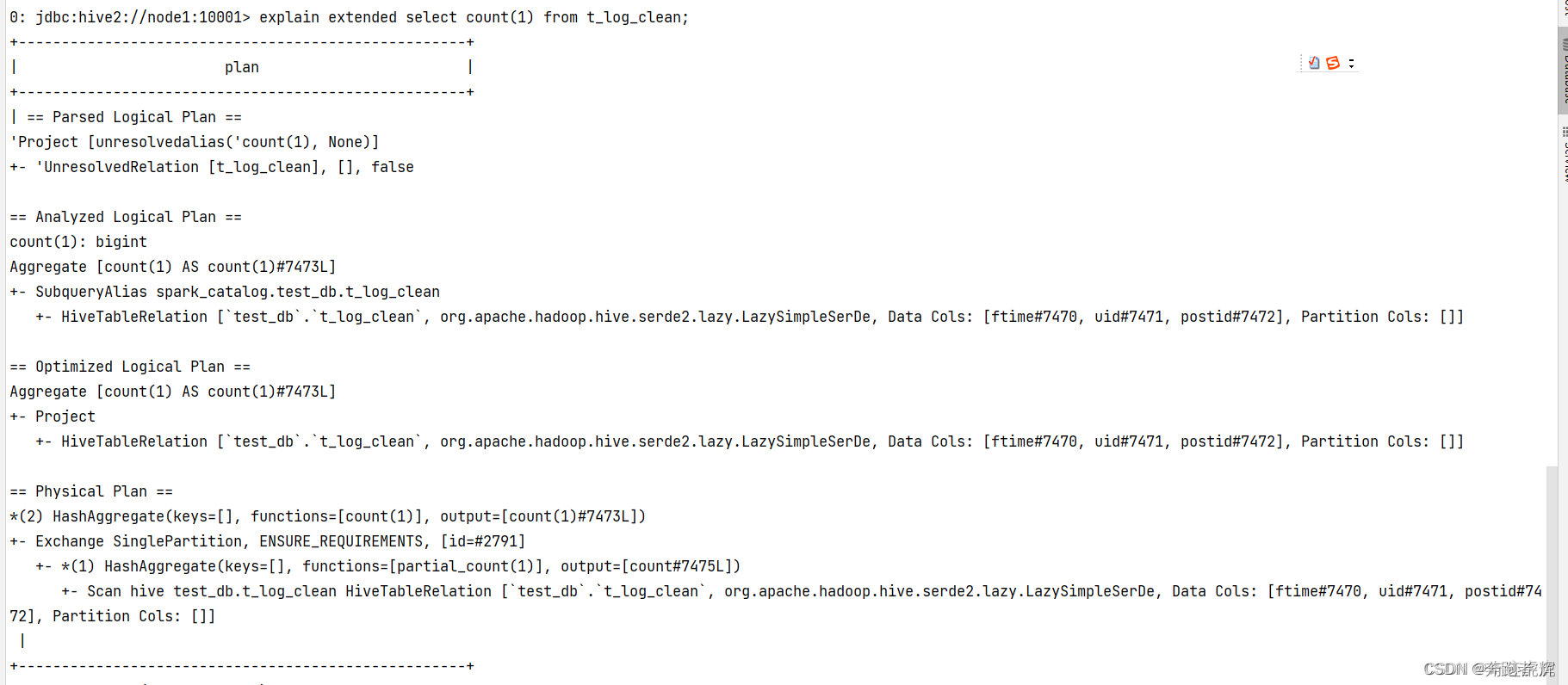
8.3 Spark SQL 是如何将数据写到Hive表的
方式一:是利用 Spark RDD 的 API 将数据写入 hdfs 形成 hdfs 文件,之后再将 hdfs 文件和 hive 表做加载映射;
方式二:利用 Spark SQL 将获取的数据 RDD 转换成 DataFrame,再将 DataFrame 写成缓存表,最后利用 Spark SQL 直接插入 hive 表中。
8.4 SparkSQL中RDD、DataFrame、DataSet三者的转换
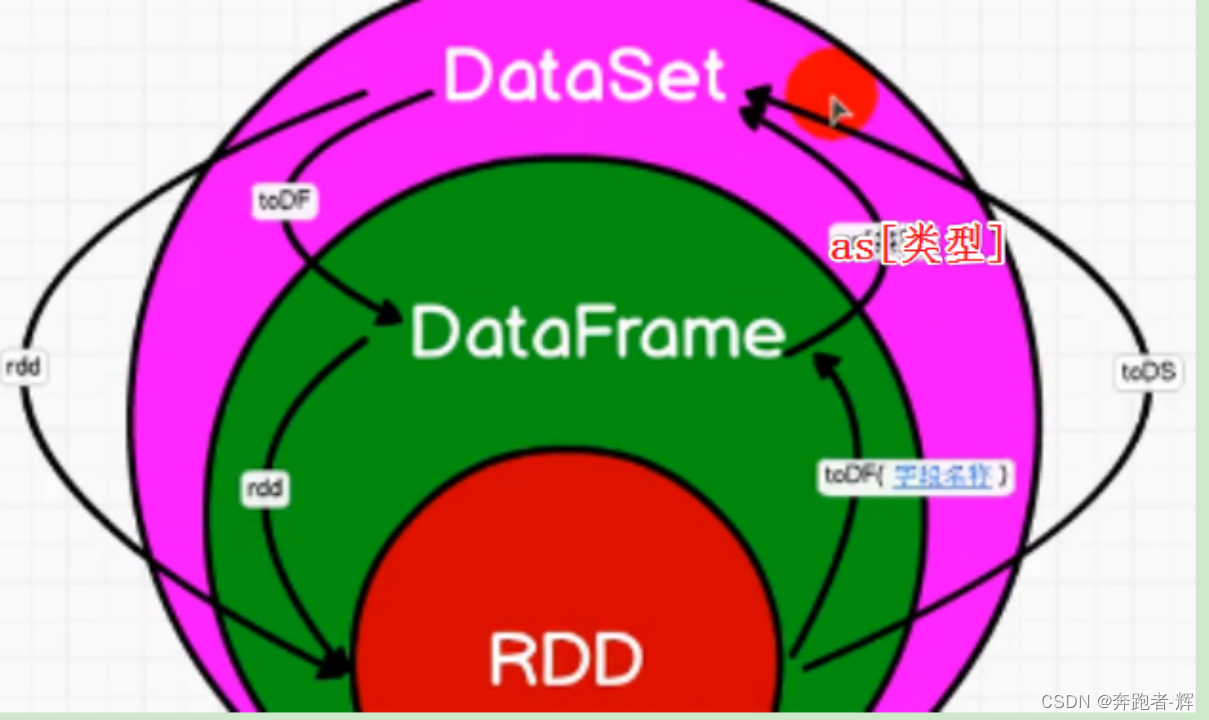
8.4.1 三者共性
① RDD、DataFrame、DataSet全部都是spark平台下的分布式弹性数据集,为处理超大数据提供便捷;
② 三者都有惰性,在进行创建、转换,如map方法时,不会立即执行,只有在遇到Action算子,如foreach()时,三者才会开始遍历运算;
③ 三者都会根据spark的内存情况自动缓冲运算,这样即使数据量大,也不会担心内存溢出;
④ 三者都有partition概念;
⑤ 三者都有许多共同函数,如:filter、排序等;
⑥ 在对DateFrame和DataSet进行操作的都需要包支持; 导入 import spark.implicts._ ;
⑦ DataFrame和DataSet均可使用模式匹配获取各个字段的值和类型;
8.4.2 三者区别
① RDD:
RDD一般和SparkMlib(机器学习库)同时使用;
RDD不支持SparkSql操作;
② DataFrame
与RDD和DataSet不同,DataFrame每一行固定内容为Row,每一列的值没法直接访问,只有通过解析才能获取各个字段值;
DataFrame和DataSet一般不与SparkMlib同时使用;
DataFrame和DataSet一般都支持SparkSql的操作;
DataFrame和DataSet支持一些特别方便的保存方式,比如:csv ;
③ DataSet
DataSet和DataFrame拥有完全相同的成员函数,区别只是每一行数据类型不同;
DataFrame也可以叫DataSet[Row],每一行类型是Row,不解析,每一行究竟有哪些字段,各个字段又是什么类型都无从得知。
9 Spark Streaming

9.1 Spark Streaming 基本工作原理
spark streaming 是 spark core API 的一种扩展,可以用于进行大规模、高吞吐量、容错的实时数据流的处理;
原理:接受实时输入数据流,然后将数据拆分成 batch,比如每收集一秒的数据封装成一个 batch,然后将每个 batch 交给 spark 的计算引擎进行处理,最后会生产处一个结果数据流,其中的数据也是一个一个的 batch 组成的。
9.2 DStream以及基本工作原理
DStream 是 spark streaming 提供的一种高级抽象,代表了一个持续不断的数据流;
DStream 可以通过输入数据源来创建,比如 Kafka、flume 等,也可以通过其他 DStream 的高阶函数来创建,比如 map、reduce、join 和 window 等;
DStream 内部其实不断产生 RDD,每个 RDD 包含了一个时间段的数据;
Spark streaming 一定是有一个输入的 DStream 接收数据,按照时间划分成一个一个的 batch,并转化为一个 RDD,RDD 的数据是分散在各个子节点的 partition 中。
9.3 Spark Streaming精准一次消费
① 手动维护偏移量;
② 处理完业务数据后,再进行提交偏移量操作
极端情况下,如在提交偏移量时断网或停电会造成spark程序第二次启动时重复消费问题,所以在涉及到金额或精确性非常高的场景会使用事物保证精准一次消费。
9.4 SparkStreaming有哪几种方式消费Kafka中的数据,它们之间的区别是什么
① receiver方式:
将数据拉取到 executor 中做操作,若数据量大,内存 存储不下,可以通过 WAL,设置了本地存储,保证数据不丢失,然后使用 Kafka 高级 API 通过 zk 来维护偏移量,保证消费数据。receiver 消费 的数据偏移量是在 zk 获取的,此方式效率低,容易出现数据丢失。
② 基于Direct 方式:
使用 Kafka 底层 Api,其消费者直接连接 kafka 的分 区上,因为 createDirectStream 创建的 DirectKafkaInputDStream 每 个 batch 所对应的 RDD 的分区与 kafka 分区一一对应,但是需要自己维护偏移量,即用即取,不会给内存造成太大的压力,效率高。
③ 对比:
基于receiver的方式,是使用Kafka的高阶API来在ZooKeeper中保存消费过的offset的。这是消费Kafka数据的传统方式。这种方式配合着WAL机制可以保证数据零丢失的高可靠性,但是却无法保证数据被处理一次且仅一次,可能会处理两次。因为Spark和ZooKeeper之间可能是不同步的。
基于direct的方式,使用kafka的简单api,Spark Streaming自己就负责追踪消费的offset,并保存在checkpoint中。Spark自己一定是同步的,因此可以保证数据是消费一次且仅消费一次。
在实际生产环境中大都用Direct方式
9.5 简述SparkStreaming窗口函数的原理
窗口函数就是在原来定义的SparkStreaming计算批次大小的基础上再次进行封装,每次计算多个批次的数据,同时还需要传递一个滑动步长的参数,用来设置当次计算任务完成之后下一次从什么地方开始计算。
9.6 SparkStreaming写一个WordCount案例
import org.apache.spark.streaming.dstream.{DStream, ReceiverInputDStream}
import org.apache.spark.streaming.{Seconds, StreamingContext}
import org.apache.spark.SparkConf
object StreamWordCount {
def main(args: Array[String]): Unit = {
//1.初始化Spark配置信息
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("StreamWordCount") //实时程序里线程数大于2
//2.初始化SparkStreamingContext
val ssc = new StreamingContext(sparkConf, Seconds(5)) //采集周期为5秒
//3.通过监控端口创建DStream,读进来的数据为一行行
val lineStreams = ssc.socketTextStream("NODE01", 9999)
//4.将每一行数据做切分,形成一个个单词
val wordStreams = lineStreams.flatMap(_.split(" "))
//5.将单词映射成元组(word,1)
val wordAndOneStreams = wordStreams.map((_, 1))
//6.将相同的单词次数做统计
val wordAndCountStreams = wordAndOneStreams.reduceByKey(_+_)
//7.打印
wordAndCountStreams.print()
//8.启动采集器SparkStreamingContext,开始执行计算
ssc.start()
//9.等待某个批次的任务处理完,在停止服务.
ssc.awaitTermination()
}
}10 Spark中某个task挂掉了,如何知道是哪个task挂掉了
在spark程序中,task有失败重试机制(根据Spark.task.maxFailures配置,默认是4次),当task任务执行失败时,并不会直接导致程序drown掉,只是重试了Spark.task.maxFailures 4次后仍然失败的情况下,程序才会drown掉。
解决:通过“自定义监控器”
需要获取SparkListenerTaskEnd事件,得继承SparkListener类,并重写onTaskEnd方法,在该方法中获取task失败reason日志,发邮件给对应的负责人,这样我们可以在第一时间知道那个task是以什么原因失败的了。















 2638
2638











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









