







2.1字符集简史
最初的ASCII在开发过程中,对确定长度是6,7或者8位产生了争议。最后确定了字符有26个小写26大写加数字等共128个字符,也就是7位长度。很明显这些字符不适用于非美国英语以外的语言,于是增加到了8位,共256个字符。也就是说如果要使用一个字节保存字符,则要128个(2^7)附加字符来补充ASCII。
ASCII码( SBCS )
ASCII 码使用指定的7 位或8 位二进制数组合来表示128 或256 种可能的字符。标准ASCII 码也叫基础ASCII码,使用7 位二进制数来表示所有的大写和小写字母,数字、标点符号,以及在美式英语中使用的特殊控制字符。
单字节字符集(single-bytecharacter set or SBCS)。在这种编码模式下,所有的字符都只用一个字节表示。ASCII是SBCS。以一个字节表示的0用来标志SBCS字符串的结束。
DBCS( MBCS )
英语用ascii编码就够了,但是世界上每个国家都有自己的文字,ascii肯定是不能满足,如中文,就必须使用两个字节(byte)来代表一个字符。DBCS从256开始,和ASCII一样,最初128个代码是ASCII,较高的128个代码中某些总是跟随第二个字节,这两个字节一起定义一个字符。习惯称为双字节(即DBCS:Double-Byte Character Set),由于Windows里使用的多字节字符绝大部分是两个字节长,所以MBCS常被用DBCS代替。
但也出现了一个问题:
双字符集并不是说字符由两个字节代表。一些字符(特别是ASCII字符)由1 个字节表示。这会引起附加的程序设计问题。如,字符串中的字符数不能由字符串的字节数决定。必须剖析字符串来决定其长度,这就要求必须检查每个字节以确定是否为双字节字符的首字节。这显然增加了设计的难度。
UNICODE
如上面所说的出现的问题,unicode正是为解决此问题而制定的。与混乱的256个字符映像及含有1字节和2字节代码的双字节不同。unicode统一16位,这样就可以表示65536个字符。这对所有目前出现的字符,符号等来说都是足够用的。
优点:只有一个字符集。
缺点:统一的16位,占用的内存是ASCII的两倍。
总结:最初的ASCII只有7位(128个字符),包含美国标准的符号,其后扩展为8位(256字符)。但也不能足够适用于其他国家的语言,于是出现了双字节字符集。但双字节字符集中有字符是占用1字节,有些却是两字节,在判断一个字符是否是8位还是16位的问题上出现了混乱。最后出现了unicode字符集,统一16位,足够使用的同时也解决了混乱问题。 ps:vc6.0默认为DBCS VS默认unicode 2.2宽字符和C语言 下面讨论把unicode和宽字节字符作为同义语。 char数据类型C语言在Win32程序中的标准定义: char c=”aaaa”; len=strlen(c); 很明显len=4; 当在在unicode下时: 没有改变char数据型态在C 中的含义。 char继续表示1 个字节的储存空间, sizeof (char)继续返回1 。 但C 中的宽字符基于wchar_t数据型态,在包括WCHAR.H的头文件中定义,如: typedef unsigned short wchar_t ; //wchar_t为16位 同样定义: wchar_t c=L"aaaa”; len=strlen(c); 引号前面的大写字母L(long)。告诉编译器该字符串按宽字符保存-即每个字符占用2个字节。 这时虽然会报错(strlen 该函数应接收char类型的指标,但它现在却接收了一个unsigned short类型的指标),但还是能运行,而此时len=1. (Ps:这里真不知道作者用的什么编译器,反正我用了vs13和vc6.0都是不能运行的,都是报错,不能转换unsign short 到const char.这里结果为1的理解是,L前缀说明每个字符是2字节,也就是16位,也就是高8位0,低8位是该字符。而strlen得到一个字符串长度并把第1个非0字节做为字符开始计数,但下一个字节是0(表示字符串结束),这样也就只能取得前面一个字符了。) 很明显在使用strlen函数时把c作为16位短整型数据处理了。这也就是两者不同的区别。 这样就面临了一个问题,在不同的编码格式下函数不通用?是否要重写这些函数?事实上这些函数也都提供了宽字符的版本。如: strlen函数的宽字符版是wcslen(wide-characterstring length:宽字符串长度),在STRING.H(包含strlen)和WCHAR.H中均有定义。 strlen函数:: size_t __cdecl strlen (const char *) ; wcslen函数: size_t __cdecl wcslen (const wchar_t *) ; 这样如果要得到宽字符串长度可以调用len = wcslen (c) ; 这时len=4。ps:改成宽字节后,字符串的字符长度不改变,组长改变。 维护单一原始码 使用unicode的缺点是占用空间过大,如果一个程序能处理ASCII字符串,另一个版本处理Unicode字符串。最好的解决办法是维护既能按ASCII编译又能按Unicode编译的单一原始码文件。 我们定义如下:#define _tcslen wcslen //如果定义了——UNICODE标识符,且包含了TCHAR.H头文件 #define _tcslen strlen //如果没有定义unicode typedef wchar_t TCHAR //Unicode typedef char TCHAR #define _T(x) L##x //Unicode L添加到宏参数上,如x为aaa,则L##x 为L”aaa” #define _T(x) x
此外,还有两个宏与_T相同#define _T(x) _T(x) #define _TEXT(x) _T(x)WINNT.H中还定义了一个宏: #define _TEXT(quote) L##quote //Unicode #define _TEXT(quote) quote //非Unicode #define TEXT(quote) _TEXT(quote)
T(x)和TEXT(x)作用相同,但无论采用哪一个,都应该在宏内定义字符串文字,如TEXT(“Hello!”) 2.3宽字符和Windows 一个Windows程序包括头文件WINDOWS.H。该文件包括许多其它头文件,如WINDEF.H,定义了许多Windows中使用的基本类型,其也包括WINNT.H。 WINNT.H处理基本的Unicode支持。 WINNT.H包含C的头文件CTYPE.H,是C众多的头文件之一,包括wchar_t的定义。WINNT.H定义了新的数据类型:N,L表示near和long。在16位系统中有大小区别,在32位系统中无区别typedef char CHAR; typedef wchar_t WCHAR;
WINNT.H头文件进而定义了可用做8位字符串指针的六种数据类型和四个可用做const 8位字符串指针的数据型态。typedef CHAR *PCHAR,*LPCH,*PCH,*NPSTR,*PSTR; typedef CONST CHAR *LPCCH,*PCCH,*LPCSTR,*PCSTR;
同理定义了六种可作为16位字符串指针的数据类型和四种可作为const 16位字符串指针的数据类型。
typedef WCHAR * PWCHAR, * LPWCH, * PWCH, *NWPSTR, * LPWSTR, * PWSTR ;
typedef CONST WCHAR * LPCWCH, * PCWCH, *LPCWSTR, * PCWSTR ;兼容两种字符集的写法
#ifdef UNICODE
typedef WCHAR TCHAR, * PTCHAR ;
typedef LPWSTR LPTCH, PTCH, PTSTR, LPTSTR ;
typedef LPCWSTR LPCTSTR ;
#else
typedef char TCHAR, * PTCHAR ;
typedef LPSTR LPTCH, PTCH, PTSTR, LPTSTR ;
typedef LPCSTR LPCTSTR ;
#endif
上面的各种宏定义可能看起来复杂麻烦,但终究是为了一个目的:编写的程序能兼容ASCII和UNICODE
Windows函数调用
WINDOWS.H中函数定义如下:
int WINAPI MessageBox (HWND, LPCSTR,LPCSTR, UINT) ;
函数的第二、三个参数是指向常数字符串的指针。当处理这个函数时,动态链接时其实是调用不同的函数,定义如下:
WINUSERAPI int WINAPI MessageBoxA (HWNDhWnd, LPCSTR lpText, LPCSTR lpCaption, UINT uType) ;
WINUSERAPI int WINAPI MessageBoxW (HWNDhWnd, LPCWSTR lpText,LPCWSTR lpCaption, UINT uType) ;
//定义了宽字符串版本
但我们在调用时可以知道依旧是使用MessageBox函数,关键是在WINUSER.H中完成了,如下:
#ifdef UNICODE
#define MessageBox MessageBoxW
#else
#define MessageBox MessageBoxA
#endifWindows中使用printf.
Windows对标准输入输出没概念,所以在windows中不能使用printf,取而代之的是fprintf
但仍然可以使用sprintf及sprintf系列中的其它函数来显示文字。
sprintf函数声明
int sprint(char* szBuffer,const char*szFormat,…);
考虑以下代码:
printf(“The sum of %i and %i is %i”,1,2,1+2);
等价于:
char buf[100];
sprint(buf, “The sum of %i and %i is %i”,1,2,1+2);
puts(buf);
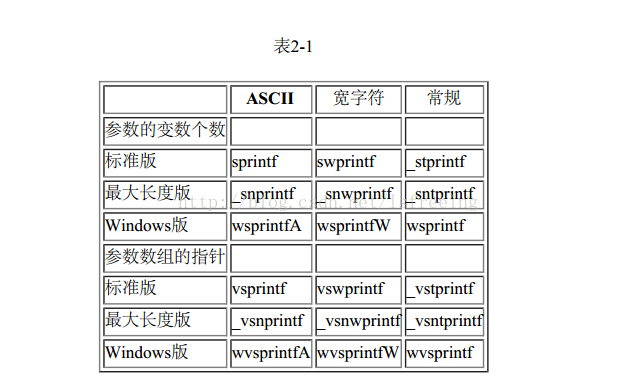
随着宽字符的发展,sprintf类型函数的增多,使得函数名称变得极为混乱。下面列出了Microsoft C 执行时期链接库和Windows支持的所有sprintf函数。
/*--------------------------------------------------------------------------- SCRNSIZE.C -- Displays screen size in a message box (c) Charles Petzold, 1998 ----------------------------------------------------------------------------*/ #include <windows.h> #include <tchar.h> #include <stdio.h> int CDECL MessageBoxPrintf (TCHAR * szCaption, TCHAR * szFormat, ...) { TCHAR szBuffer [1024] ; va_list pArgList ; va_start (pArgList, szFormat) ; _vsntprintf ( szBuffer, sizeof (szBuffer) / sizeof (TCHAR), szFormat, pArgList) ; va_end (pArgList) ; return MessageBox (NULL, szBuffer, szCaption, 0) ; } int WINAPI WinMain (HINSTANCE hInstance, HINSTANCE hPrevInstance, PSTR szCmdLine, int iCmdShow) { int cxScreen, cyScreen ; cxScreen = GetSystemMetrics (SM_CXSCREEN) ; cyScreen = GetSystemMetrics (SM_CYSCREEN) ; MessageBoxPrintf ( TEXT ("ScrnSize"), TEXT ("The screen is %i pixels wide by %i pixels high."), cxScreen, cyScreen) ; return 0 ; }














 1534
1534











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









