







转载 http://my.oschina.net/flashsword/blog/156798
FYI
概述
Jsoup的代码相当简洁,Jsoup总共53个类,且没有任何第三方包的依赖,对比最终发行包9.8M的SAXON,实在算得上是短小精悍了。
jsoup
├── examples #样例,包括一个将html转为纯文本和一个抽取所有链接地址的例子。
├── helper #一些工具类,包括读取数据、处理连接以及字符串转换的工具
├── nodes #DOM节点定义
├── parser #解析html并转换为DOM树
├── safety #安全相关,包括白名单及html过滤
└── select #选择器,支持CSS Selector以及NodeVisitor格式的遍历使用
Jsoup的入口是Jsoup类。examples包里提供了两个例子,解析html后,分别用CSS Selector以及NodeVisitor来操作Dom元素。
这里用ListLinks里的例子来说明如何调用Jsoup:
public static void main(String[] args) throws IOException {
String url = "http://xx.com";
print("Fetching %s...", url);
Document doc = Jsoup.connect(url).get();
Elements links = doc.select("a[href]");
Elements media = doc.select("[src]");
Elements imports = doc.select("link[href]");
print("\nMedia: (%d)", media.size());
for (Element src : media) {
if (src.tagName().equals("img"))
print(" * %s: <%s> %sx%s (%s)",
src.tagName(), src.attr("abs:src"), src.attr("width"), src.attr("height"),
trim(src.attr("alt"), 20));
else
print(" * %s: <%s>", src.tagName(), src.attr("abs:src"));
}
print("\nImports: (%d)", imports.size());
for (Element link : imports) {
print(" * %s <%s> (%s)", link.tagName(), link.attr("abs:href"), link.attr("rel"));
}
print("\nLinks: (%d)", links.size());
for (Element link : links) {
print(" * a: <%s> (%s)", link.attr("abs:href"), trim(link.text(), 35));
}
}
private static void print(String msg, Object... args) {
System.out.println(String.format(msg, args));
}
private static String trim(String s, int width) {
if (s.length() > width)
return s.substring(0, width - 1) + ".";
else
return s;
}HtmlToPlainText的例子说明了如何使用NodeVisitor来遍历DOM树,将html转化为纯文本,并将需要换行的标签替换为换行\n:
private static final String userAgent = "Mozilla/5.0 (jsoup)";
private static final int timeout = 5 * 1000;
public static void main(String[] args) throws IOException {
Document doc = Jsoup.connect("http://xx.com").userAgent(userAgent).timeout(timeout).get();
String plainText = getPlainText(doc.body());
System.out.println("plainText = " + plainText);
System.out.println("=================================");
System.out.println(doc.text());
}
/**
* Format an Element to plain-text
*
* @param element the root element to format
* @return formatted text
*/
public static String getPlainText(Element element) {
FormattingVisitor formatter = new FormattingVisitor();
NodeTraversor traversor = new NodeTraversor(formatter);
traversor.traverse(element); // walk the DOM, and call .head() and .tail() for each node
return formatter.toString();
}
// the formatting rules, implemented in a breadth-first DOM traverse
private static class FormattingVisitor implements NodeVisitor {
private static final int maxWidth = 80;
private int width = 0;
private StringBuilder accum = new StringBuilder(); // holds the accumulated text
// hit when the node is first seen
public void head(Node node, int depth) {
String name = node.nodeName();
if (node instanceof TextNode)
append(((TextNode) node).text()); // TextNodes carry all user-readable text in the DOM.
else if (name.equals("li"))
append("\n * ");
else if (name.equals("dt"))
append(" ");
else if (StringUtil.in(name, "p", "h1", "h2", "h3", "h4", "h5", "tr"))
append("\n");
}
// hit when all of the node's children (if any) have been visited
public void tail(Node node, int depth) {
String name = node.nodeName();
if (StringUtil.in(name, "br", "dd", "dt", "p", "h1", "h2", "h3", "h4", "h5"))
append("\n");
else if (name.equals("a"))
append(String.format(" <%s>", node.absUrl("href")));
}
// appends text to the string builder with a simple word wrap method
private void append(String text) {
if (text.startsWith("\n"))
width = 0; // reset counter if starts with a newline. only from formats above, not in natural text
if (text.equals(" ") &&
(accum.length() == 0 || StringUtil.in(accum.substring(accum.length() - 1), " ", "\n")))
return; // don't accumulate long runs of empty spaces
if (text.length() + width > maxWidth) { // won't fit, needs to wrap
String words[] = text.split("\\s+");
for (int i = 0; i < words.length; i++) {
String word = words[i];
boolean last = i == words.length - 1;
if (!last) // insert a space if not the last word
word = word + " ";
if (word.length() + width > maxWidth) { // wrap and reset counter
accum.append("\n").append(word);
width = word.length();
} else {
accum.append(word);
width += word.length();
}
}
} else { // fits as is, without need to wrap text
accum.append(text);
width += text.length();
}
}
@Override
public String toString() {
return accum.toString();
}
}DOM结构相关类
我们先来看看nodes包的类图:
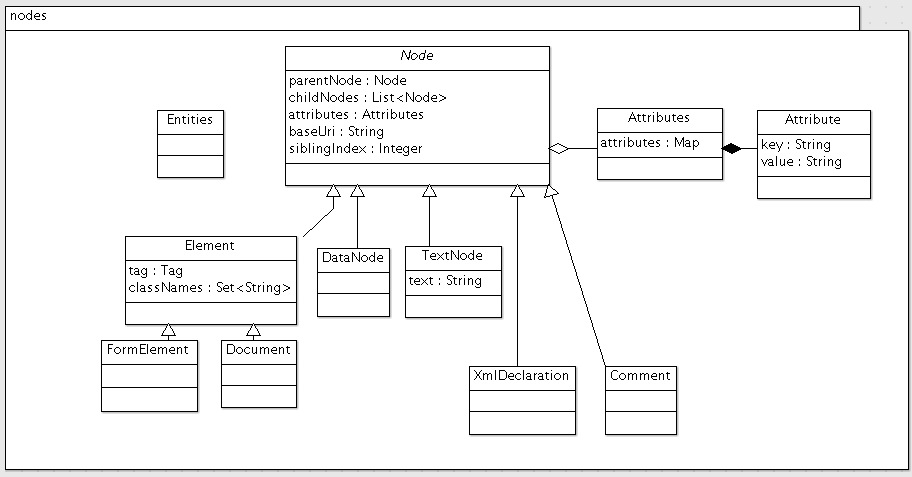
这里可以看到,核心无疑是Node类。
Node类是一个抽象类,它代表DOM树中的一个节点,它包含:
父节点parentNode以及子节点childNodes的引用
属性值集合attributes
页面的uribaseUri,用于修正相对地址为绝对地址
在兄弟节点中的位置siblingIndex,用于进行DOM操作
Node里面包含一些获取属性、父子节点、修改元素的方法,其中比较有意思的是absUrl()。我们知道,在很多html页面里,链接会使用相对地址,我们有时会需要将其转变为绝对地址。Jsoup的解决方案是在attr()的参数开始加”abs:“,例如attr(“abs:href”),而absUrl()就是其实现方式
URL base;
try {
try {
base = new URL(baseUri);
} catch (MalformedURLException e) {
// the base is unsuitable, but the attribute may be abs on its own, so try that
URL abs = new URL(relUrl);
return abs.toExternalForm();
}
// workaround: java resolves '//path/file + ?foo' to '//path/?foo', not '//path/file?foo' as desired
if (relUrl.startsWith("?"))
relUrl = base.getPath() + relUrl;
// java URL自带的相对路径解析
URL abs = new URL(base, relUrl);
return abs.toExternalForm();
} catch (MalformedURLException e) {
return "";
}Node还有一个比较值得一提的方法是abstract String nodeName(),这个相当于定义了节点的类型名(例如Document是’#Document’,Element则是对应的TagName)。
Element也是一个重要的类,它代表的是一个HTML元素。它包含一个字段tag和classNames。classNames是”class”属性解析出来的集合,因为CSS规范里,“class”属性允许设置多个,并用空格隔开,而在用Selector选择的时候,即使只指定其中一个,也能够选中其中的元素。所以这里就把”class”属性展开了。Element还有选取元素的入口,例如select、getElementByXXX,这些都用到了select包中的内容,这个留到下篇文章select再说。
Document是代表整个文档,它也是一个特殊的Element,即根节点。Document除了Element的内容,还包括一些输出的方法。
Document还有一个属性quirksMode,大致意思是定义处理非标准HTML的几个级别,这个留到以后分析parser的时候再说。
DOM树的遍历
Node还有一些方法,例如outerHtml(),用作节点及文档HTML的输出,用到了树的遍历。在DOM树的遍历上,用到了NodeVisitor和NodeTraversor来对树的进行遍历。NodeVisitor在上一篇文章提到过了,head()和tail()分别是遍历开始和结束时的方法,而NodeTraversor的核心代码如下:
public void traverse(Node root) {
Node node = root;
int depth = 0;
//这里对树进行后序(深度优先)遍历
while (node != null) {
//开始遍历node
visitor.head(node, depth);
if (node.childNodeSize() > 0) {
node = node.childNode(0);
depth++;
} else {
//没有下一个兄弟节点,退栈
while (node.nextSibling() == null && depth > 0) {
visitor.tail(node, depth);
node = node.parent();
depth--;
}
//结束遍历
visitor.tail(node, depth);
if (node == root)
break;
node = node.nextSibling();
}
}
}这里使用循环+回溯来替换掉了我们常用的递归方式,从而避免了栈溢出的风险。
实际上,Jsoup的Selector机制也是基于NodeVisitor来实现的,可以说NodeVisitor是更加底层和灵活的API。















 5784
5784

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









