









之前写过一篇文章android 项目实战——打造超级课程表一键提取课表功能,里面用到了这个库,但是在那篇文章里,jsoup的使用几乎是没有讲到,因此,此篇文章补上。
jsoup 是一款Java 的HTML解析器,可直接解析某个URL地址、HTML文本内容。它提供了一套非常省力的API,可通过DOM,CSS以及类似于jQuery的操作方法来取出和操作数据
开始讲一大堆语法,如果你不敢兴趣,大可跳过这部分,直接看代码实战部分。
Jsoup可以解析和遍历一个文档,一个文档的对象模型是由以下几部分组成。
1. Document又Elements和TextNodes组成
2. 继承关系是:Document继承Element,Element继承Node.TextNode,Node.TextNode继承自Node
3. 一个Element节点包含了一系列的孩子节点Node,并且拥有一个父节点Element
如果你想从一个字符串中解析文档,那么使用下面的这个个方法即可
Jsoup.parse(String html)
如果你想解析body片段,可以使用下面的方法
Jsoup.parseBodyFragment(String html)
如
String html = "<div><p>Lorem ipsum.</p>";
Document doc = Jsoup.parseBodyFragment(html);
Element body = doc.body();你还可以从URL中加载一个文档,使用下面的方法即可
Jsoup.connect(String url)
甚至是从一个文件中加载文档,使用下面的方法
Jsoup.parse(File in, String charsetName, String baseUri)
文档解析有很多方法,先介绍几个简单的方法,用于获取文档中的信息,比如标题等。
location()
head()
body()
title()
选择节点,该类型的方法和js里的dom操作很像
寻找节点的相关函数
getElementById(String id)
getElementsByTag(String tag)
getElementsByClass(String className)
getElementsByAttribute(String key)
寻找节点的同辈:
siblingElements()
firstElementSibling()
lastElementSibling()
nextElementSibling()
previousElementSibling()
还可以找到父亲和孩子
parent()
children()
child(int index)
节点数据
attr(String key) 获得该属性的值
attr(String key, String value) 设置该属性的值
attributes() 获得所有属性
id()
className()
classNames()
text() 获得文本内容
text(String value) 设置文本内容
html() 获得html内容
html(String value) 设置html内容
outerHtml()获得外围html值
data() 获得元素内容 (比如script和style标签)
tag()
tagName()
HTML 和text操作
append(String html)
prepend(String html)
appendText(String text)
prependText(String text)
appendElement(String tagName)
prependElement(String tagName)
html(String value)
此外选择节点的操作还可以使用选择器选择,使用select函数
Selector选择器概述
• tagname: 通过标签查找元素,比如:a
• ns|tag: 通过标签在命名空间查找元素,比如:可以用 fb|name 语法来查找 <fb:name> 元素
• #id: 通过ID查找元素,比如:#logo
• .class: 通过class名称查找元素,比如:.masthead
• [attribute]: 利用属性查找元素,比如:[href]
• [^attr]: 利用属性名前缀来查找元素,比如:可以用[^data-] 来查找带有HTML5 Dataset属性的元素
• [attr=value]: 利用属性值来查找元素,比如:[width=500]
• [attr^=value], [attr$=value], [attr*=value]: 利用匹配属性值开头、结尾或包含属性值来查找元素,比如:[href*=/path/]
• [attr~=regex]: 利用属性值匹配正则表达式来查找元素,比如: img[src~=(?i)\.(png|jpe?g)]
• *: 这个符号将匹配所有元素
Selector选择器组合使用
• el#id: 元素+ID,比如: div#logo
• el.class: 元素+class,比如: div.masthead
• el[attr]: 元素+class,比如: a[href]
• 任意组合,比如:a[href].highlight
• ancestor child: 查找某个元素下子元素,比如:可以用.body p 查找在"body"元素下的所有 p元素
• parent > child: 查找某个父元素下的直接子元素,比如:可以用div.content > p 查找 p 元素,也可以用body > * 查找body标签下所有直接子元素
• siblingA + siblingB: 查找在A元素之前第一个同级元素B,比如:div.head + div
• siblingA ~ siblingX: 查找A元素之前的同级X元素,比如:h1 ~ p
• el, el, el:多个选择器组合,查找匹配任一选择器的唯一元素,例如:div.masthead, div.logo
伪选择器selectors
• :lt(n): 查找哪些元素的同级索引值(它的位置在DOM树中是相对于它的父节点)小于n,比如:td:lt(3) 表示小于三列的元素
• :gt(n):查找哪些元素的同级索引值大于n,比如: div p:gt(2)表示哪些div中有包含2个以上的p元素
• :eq(n): 查找哪些元素的同级索引值与n相等,比如:form input:eq(1)表示包含一个input标签的Form元素
• :has(seletor): 查找匹配选择器包含元素的元素,比如:div:has(p)表示哪些div包含了p元素
• :not(selector): 查找与选择器不匹配的元素,比如: div:not(.logo) 表示不包含 class=logo 元素的所有 div 列表
• :contains(text): 查找包含给定文本的元素,搜索不区分大不写,比如: p:contains(jsoup)
• :containsOwn(text): 查找直接包含给定文本的元素
• :matches(regex): 查找哪些元素的文本匹配指定的正则表达式,比如:div:matches((?i)login)
• :matchesOwn(regex): 查找自身包含文本匹配指定正则表达式的元素
• 注意:上述伪选择器索引是从0开始的,也就是说第一个元素索引值为0,第二个元素index为1等
在获得了一个Document对象,并查找到一些元素之后,你希望取得在这些元素中的数据。
• 要取得一个属性的值,可以使用Node.attr(String key) 方法
• 对于一个元素中的文本,可以使用Element.text()方法
• 对于要取得元素或属性中的HTML内容,可以使用Element.html(), 或 Node.outerHtml()方法
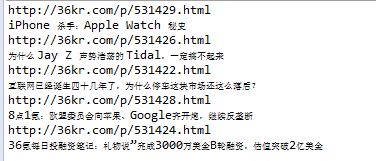
讲完了所有的基础语法内容,我们来实战一下。我们来解析下36氪首页的数据,将下图的文字和链接提取出来
通过审查元素,会发现器html代码大致是这样的
<article class="headline__news">
<a href="http://36kr.com/p/531426.html" class="topic-post-small one" target="_blank">
<div class="image-overlay small"></div>
<div class="topic-title">
<h1>为什么 Jay Z 声势浩荡的 Tidal,一定搞不起来</h1>
</div>
</a>
</article>关键代码如下
Document doc = Jsoup.connect("http://36kr.com/").get();
Elements news = doc.getElementsByClass("headline__news");//通过class来选择
for (Element element : news) {
Elements aNode = element.getElementsByTag("a");//标签选择
String link = aNode.attr("href");//获得属性值
System.out.println(link);
Elements hNode = element.getElementsByTag("h");//标签选择
String title = aNode.text();//获得文本内容
System.out.println(title);
}运行效果如下
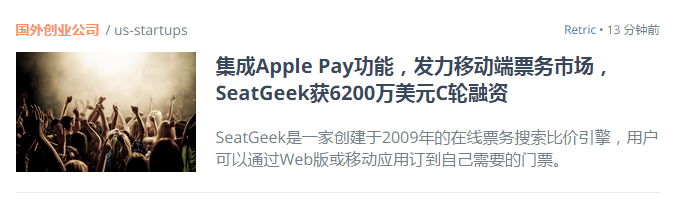
下面我们解析具体文章内容,就是下面截图的这部分内容
先看下文档结构
<div class="post">
<div class="left left-col">
<div class="image feature-img thumb-180">
<a href="http://36kr.com/p/531438.html">
<img src="http://a.36krcnd.com/nil_class/0fbfb739-bd6e-4f2d-aa54-98ec5d7745de.jpg!slider" alt="" />
</a>
</div>
</div>
</div>
<div class="right-col">
<h1>
<a href="http://36kr.com/p/531438.html" target="_blank" >集成Apple Pay功能,发力移动端票务市场,SeatGeek获6200万美元C轮融资</a>
</h1>
<p>SeatGeek是一家创建于2009年的在线票务搜索比价引擎,用户可以通过Web版或移动应用订到自己需要的门票。</p>
</div>
</article>
<article class="posts post-1 cf">
<div class="info cf">
<div class="topic left">
<span>
<a class="breaking" href="/columns/breaking" > 国外资讯 </a> / breaking
</span>
</div>
<div class="postmeta right">
<a href="javascript:void(0)"> feng </a>
•
<time class="timeago" datetime="2015-04-03 11:56:11 +0800">3 分钟前</time>
</div>
</div>因为还涉及到页数,因为这些新闻都是分页的,所以应该还有一个参数就是页数,我们将其封装成函数。
首先编写新闻实体类,可以从截图中看到,应该有一个标题(包括链接),一个描述,一张缩略图,以及一个发表时间(这里使用String类型),以及还有一个分类信息,还有一个作者。
package cn.edu.zafu;
public class News {
private String title;
private String url;
private String description;
private String img;
private String author;
private String time;
private String cat;
public String getTitle() {
return title;
}
public void setTitle(String title) {
this.title = title;
}
public String getUrl() {
return url;
}
public void setUrl(String url) {
this.url = url;
}
public String getDescription() {
return description;
}
public void setDescription(String description) {
this.description = description;
}
public String getImg() {
return img;
}
public void setImg(String img) {
this.img = img;
}
public String getAuthor() {
return author;
}
public void setAuthor(String author) {
this.author = author;
}
public String getTime() {
return time;
}
public void setTime(String time) {
this.time = time;
}
public String getCat() {
return cat;
}
public void setCat(String cat) {
this.cat = cat;
}
@Override
public String toString() {
return "News [title=" + title + ", url=" + url + ", description="
+ description + ", img=" + img + ", author=" + author
+ ", time=" + time + ", cat=" + cat + "]";
}
}
解析部分代码
package cn.edu.zafu;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
public class Main {
private static List<News> list=new ArrayList<News>();
private static String url="http://36kr.com/?page=PAGE";
public static void main(String[] args) throws IOException {
parseByPage(1);
System.out.println(list);
}
public static void parseByPage(int page) throws IllegalArgumentException{
//页数不合法
if(page<=0)
throw new IllegalArgumentException("页数不合法");
try {
Document doc=Jsoup.connect(url.replace("PAGE", page+"")).get();
//获得新闻
Elements posts = doc.select("article.posts");
//遍历
for (Element element : posts) {
//解析
Elements cat = element.select("span a");
Elements author = element.select("div.postmeta a");
Elements time = element.select("div.postmeta .timeago");
Elements img = element.select("img");
Elements title = element.select("div.right-col h1 a");
Elements description = element.select("div.right-col p");
//赋值
News news=new News();
news.setCat(cat.text());
news.setAuthor(author.text());
news.setTime(time.text());
news.setImg(img.attr("src"));
news.setTitle(title.text());
news.setUrl(title.attr("href"));
news.setDescription(description.text());
list.add(news);
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
运行后可以看到抓取的第一页的新闻

就这样,dom操作和选择器操作的用法也结束了,其实jsoup还有很多东西,具体的内容就有待诸位去挖掘了















 790
790

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









