







算法导论第六章总结:堆排序
这一章介绍了另一种排序算法:堆排序。它的时间复杂度为 O(n lg n),且具有空间原址性(即任何时候只需要常数个额外的元素空间存储临时数据)。时间复杂度优于插入排序,与归并排序相同。且具有归并排序不具备的空间原址性这一优点。并且,这一章引入了“堆”这种数据结构。
一、堆 P84、85
(二叉)堆是一个数组,它可以被看成是一个近似的完全二叉树。树上的每一个结点对应数组中的一个元素。除了最底层外,该树是完全充满的,而且是从左向右填充。表示堆的数组 A 包括两个属性:A.length 给出数组元素的个数,A. heap-size 表示有多少个堆元素存储在该数组中。
给定一个结点的下标 i,我们可计算出它的父节点、左孩子和右孩子的下标:
PARENT(i) LEFT(i) RiGHT(i)
return└ i/2 ┘ return 2i return2i+1
二叉堆可分为两种形式:最大堆和最小堆。其中最大堆是指对除根结点外的所有结点 i 满足:A[ PARENT(i) ] ≥ A[i]。最小堆则是 A[ PARENT(i) ] ≤ A[i]。之后我们的算法均默认为最大堆。
接下来介绍一些基本过程,其中n代表元素个数。
MAX-HEAPIFY:其时间复杂度为 O(lgn),用来维护最大堆性质,也就是使堆满足A[ PARENT(i) ] ≥ A[i]。
BUILD-MAX-HEAP:具有线性复杂度,从无序的输入数据数组中构造一个最大堆。
HEAPSORT:其时间复杂度为 O(n lg n),对一个数组进行原址排序。
MAX-HEAP-INSERT、HEAP-EXTRACT-MAX、HEAP-INCREASE-KEY和HEAP-MAXIMUM:时间复杂度O(lgn),功能是从利用堆来实现一个优先队列。
二、维护堆的性质(最大堆)P85~87
MAX-HEAPIFY 用于维护最大堆的性质。它的输入为一个数组 A 和一个下标 i。它使以 A[i] 为根节点的树满足最大堆性质,但前提是假定根结点为 LEFT(i) 和 RIGHT(i) 的二叉树都是最大堆。MAX-HEAPIFY 通过让 A[i] 在最大堆中“逐级下降”,从而使得以下标i为根结点的子树重新遵循最大堆的性质。
MAX-HEAPIFY( A, i )
l=LEFT (i)
r=RIGHT (i)
if l ≤ A. heap-size and A[l]> A[i]
largest = l
else largest = i
if r ≤A. heap-size and A[r]> A[largest]
largest = r
if largest ≠ i
exchange A[i] with A[largest]
MAX-HEAPIFY( A, largest )

上述递归式的解为T(n)=O( lgn)。
三、建堆 P87~P89
我们用 MAX-HEAPIFY 把一个大小为n =A.length 的数组 A[ 1…n ] 转换为最大堆。因为子数组的元素是树的叶结点,所以对其他结点调用 MAX-HEAPIFY 即可。
BUILD-MAX-HEAP (A)
A. heap-size = A. length
for i =MAX-HEAPIFY (A , i)

图1 时间复杂度分析(没太看懂。。。)
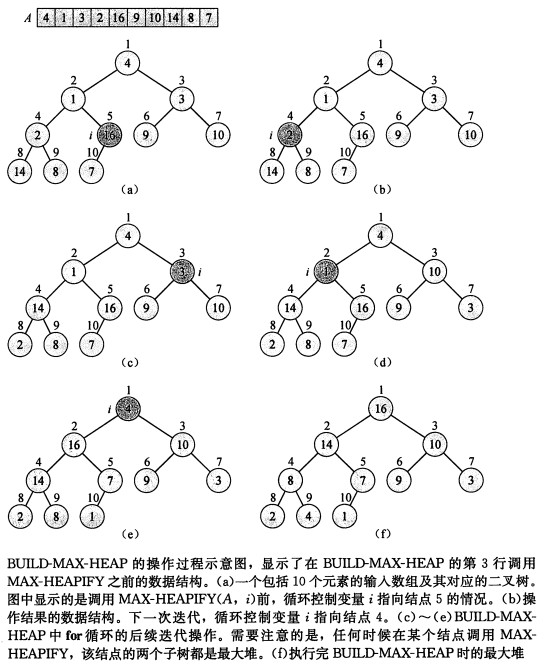
图2 BUILD-MAX-HEAP操作过程示意图
四、堆排序算法 P89、90
堆排序算法就是已知一个最大堆,并把该最大堆按照从大到小的顺序排成数组。对于此算法,通俗地讲,就是先把根结点元素取出,放进数组中作为最大值,原因是最大堆中根结点元素一定最大,我们通过将 A[1] 和 A[n] 互换并减少 A. heap-size(A. heap-size =A. heap-size- 1)来实现。将 A[n] 换上去之后,不再满足最大堆性质(但高度h - 1以下仍满足最大堆性质),所以我们调用 MAX-HEAPIFY ( A , 1 ),让换上去的元素找到自己合适的位置,使整个堆(A[1]~A[n-1])重新满足最大堆的性质。不断重复这一过程,直到最后一个元素。
HEAPSORT(A)
BUILD-MAX-HEAP(A)
for i = A. lengthdownto 2
exchange A[1] with A[i]
A. heap-size = A. heap-size - 1
MAX-HEAPIFY (A , 1)
HEAPSORT 过程的时间复杂度是 O(n lg n),因为调用 BUILD-MAX-HEAP 的时间复杂度是 O(n) ,而 n-1 次调用 MAX-HEAPIFY,每次的时间为 O(lg n)。
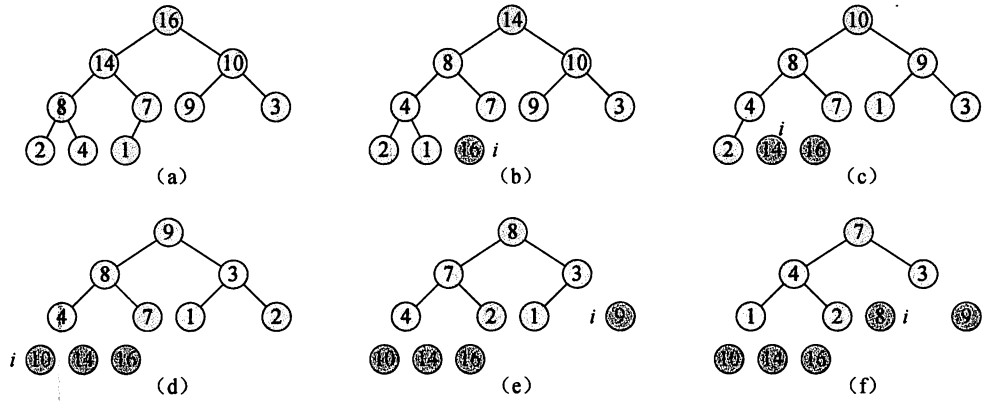
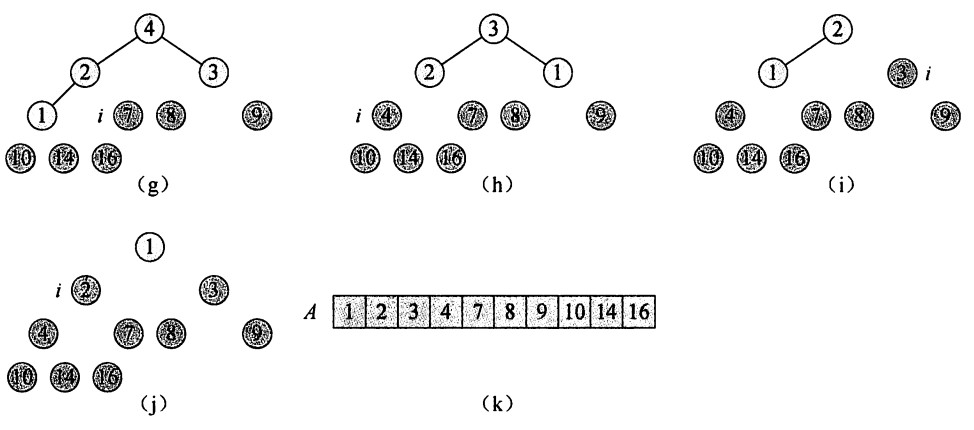
图3 HEAPSORT 过程操作过程示意图
五、优先队列 P90~P92
这一节介绍了堆的一个常见应用:优先队列。这里,我们关注如何基于最大堆来实现最大优先队列。
普通的队列是一种先进先出的数据结构,元素在队列尾追加,而从队列头删除。在优先队列中,元素被赋予优先级。当访问元素时,具有最高优先级的元素最先删除。优先队列具有最高级先出 (largest-in,first-out)的行为特征。其中每个元素都有一个相关的值,称为关键字( key )。
一个最大优先队列支持以下操作:
INSERT(S,x ): 把元素x插入到集合S中。
MAXIMUM(S ): 返回S中具有最大关键字的元素。
EXTRACT_MAX(S ): 去掉并返回S中具有最大关键字的元素。
INCREASE_KEY( S, x, k ): 将元素x的关键字值增加到k,这里假设k的值不小于x的原关键字值。优先队列可以用堆来实现。在用堆的来实现优先队列时,需要在堆中的每个元素里存储对应对象的句柄。关于句柄,其含义依赖于具体程序,但我的理解就是一种标识,比如指针、数组下标,可通过句柄访问对象。接下来,我们讨论如何实现最大优先队列的操作。
HEAP-MAXIMUM(A)
returnA[1]
HEAP-EXTRACT-MAX(A)
1 if A. heap-size < 1
2 error “heap underflow”
3 max = A[1]
4 A[1] = A[A.heap.size]
5 A. heap-size = A. heap-size - 1
6 MAX-HEAPIFY (A , 1)
7 returnmax
理论上讲,HEAP-EXTRACT-MAX 只需要返回 A[1] 即可,4~6行是为了维护最大堆性质,保证提取 max 之后仍为最大堆。
HEAP-INCREASE-KEY (A, i, key)
if key < A[i]
error “new key is smaller than current key”
A[i] = key
while i > 1 and A[parent(i)]< A[i]
exchange A[i] with A[parent(i)]
i = PARENT(i)
算法第3行做了关键字更新的结点到根结点的路径长度为 O(lg n) ,所以时间复杂度为 O(lg n) 。该算法增大 A[i] 的关键字到 key,并重新选择 A[i] 的位置,使整个堆满足最大堆的性质。
MAX-HEAP-INSERT (A, key)
A. heap-size = A. heap-size - 1
A[A. heap-size] =-∞
HEAP-INCREASE-KEY (A, A. heap-size,key)
该算法的输入时要被插入到最大堆 A 中的新元素的关键字。首先扩展最大堆,然后调用 HEAP-INCREASE-KEY 为新结点设置对应的关键字,同时保持最大堆的性质。时间复杂度为 O(lg n)。
总之,包含 n 个元素的堆中,所有优先队列的操作都可以在 O(lg n) 时间内完成。















 406
406

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









