







这一章简要介绍了一个贯穿全书的框架。对于这个框架,我的理解就是算法的流程吧。
(1) 问题:算法需要实现的功能。
(2) 思想:算法的设计。
(3) 实现:代码,本书中采用“伪代码”实现,需根据实际情况自己完成具体代码。
(4) 分析:分析算法性能。比如时间复杂度,运行时间与输入规模的关系。
本书在这一章以插入排序和归并排序为例子,这里我们再加上比较基础的冒泡排序。以下都按照从小到大来进行排序。
首先,这三种排序方法解决的问题是一样的,即输入:n个数的序列{a1, a2,… , an}。输出:得到序列{a1’, a2’,… , an’},满足a1’≤ a2’≤ …≤ an’。
一、插入排序 P9~P16
以书中的扑克牌排序来理解此算法。开始时,我们的左手为空并且桌子上的牌面向下。然后,我们每次从桌子上拿走一张牌并将它插入左手中正确的位置。为找到一张牌的正确位置,我们从右到左将它与已在手中的每张牌做比较(已在左手中的这些牌总是排好序的)。来选择合适的位置插入。
INSERTION-SORT(A)
1 for j=2 to A.length
2 key=A[j]
3 // Insert A[j] into the sorted sequence A[1…j-1]
4 i=j-1
5 while i>0 and A[i]>key
6 A[i+1]=A[i]
7 i=i-1
8 A[i+1]=key
对于归并排序,其关键是“合并”步骤中两个已排序序列的合并。我们通过调用一个辅助过程MERGE(A,p,q,r)来完成合并,其中A是一个数组,p、q和r是数组下标,满足p≤q<r。该过程假设子数组A[p…q]和A[q+1…r]都已排好序, 它合并这两个子数组形成单一的已排好序的子数组并代替当前的子数组A[p…r]。
回到扑克牌的例子,假设桌上有两堆牌面朝上的牌,两堆都已排好序,最小的牌在顶上。我们希望把这两堆牌合并成单一的排好序的输出堆,牌面朝下地放在桌上,我们的基本步骤包括在牌面朝上的两堆牌的顶上两张牌中选取较小的一张,将该牌从其堆中移开(该堆的顶上将显露一张新牌)并牌面朝下地将该牌放置到输出堆。重复这个步骤,直到一个输入堆为空,这时,我们只是拿起剩余的输入堆并牌面朝下地将该堆放置到输出堆。因为我们只是比较顶上的两张牌,所以计算上每个基本步骤需要常量时间。因为我们最多执行 n步,所以合并需要O(n)的时间。
下面的伪代码实现了上面的思想,但有一个额外的变化,为避免在每个基本步骤必须检査是否有堆为空。在每个堆的底部放置一张哨兵牌,它包含一个特殊的值,用于简化代码。这里,我们使用∞作为哨兵值,结果每当显露一张值为∞的牌,它不可能为较小的牌,除非两个堆都已显露出其哨兵牌。但是,一旦发生这种情况,所有非哨兵牌都已被放置到输出堆,因为我们事先知道刚好r-p+1 张牌将被放置到输出堆,所以一旦已执行 r-p+1个基本步骤,算法就可以停止。MERGE(A,p,q,r)
1 n1=q-p+1 // 前子数组元素个数
2 n2=r-q // 后子数组元素个数
3 let L[1…n1+1] and R [1…n2+1] be new arrays
4 for i=1 to n1
5 L[i]= A [p+i-1] // 前子数组赋值为L
6 for j=1 to n2
7 R[j] = A[q + j] // 后子数组赋值为R
8 L [n1+1]= ∞
9 R [n2+1] =∞
10 i=1
11 j=1
12 for k=p to r
13 if L[i]≤R[j]
14 A[k]=L[i]
15 i=i+1
16 else A[k]=R[j]
17 j=j+1
该MERGE过程可以作为归并排序的子程序来用,即第三步。下面的过程MERGE-SORT(A,p, r)排序子数组A[p…r]中的元素。
MERGE-SORT (A,p,r)
1 if p<r
2 q=|(p+r)/2|
3 MERGE-SORT(A,p,q) // 前子数组排序
4 MERGE-SORT(A,q+1,r) // 后子数组排序
5 MERGE (A,p,q,r) // 排好序的两数组合并
为了排序整个序列 A=<A[1], A[2], … , A[n]>,我们执行初始调用MERGE-SORT(A, 1,A.length),这里再次有A.length =n。图1 自底向上地说明了当n为2的幂时该过程的操作。算法由以下操作组成:合并只含1项的序列对形成长度为2的排好序的序列,合并长度为2的序列对形成长度为4的排好序的序列,依此下去,直到长度为 n/2的两个序列被合并最终形成长度为 n的排好序的序列。
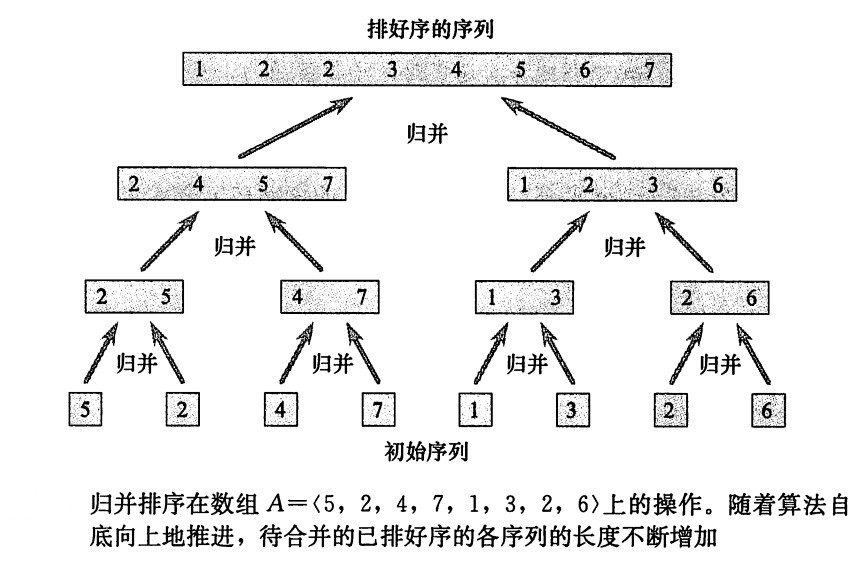
图 1 MERGE-SORT的操作
该算法时间复杂度T(n)为
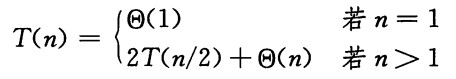
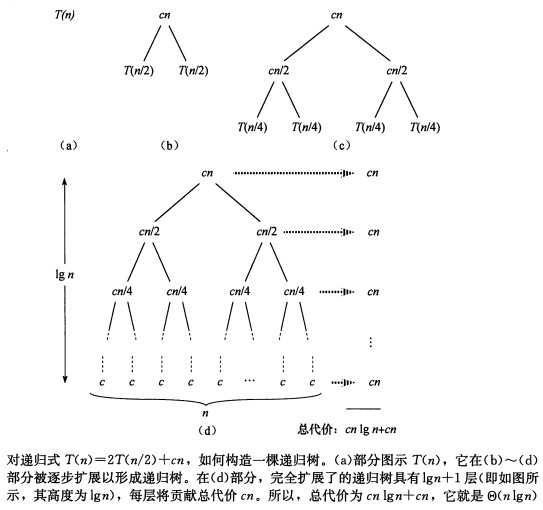
求解该递归式即为O(nlgn),其中lgn代表log2n。
图2 对其做了解释,即为何时间复杂度为O(n lg n)。
三、冒泡排序
冒泡排序重复地走访过要排序的数列,一次比较两个元素,如果他们的顺序错误就把他们交换过来。这个算法的名字由来是因为越大的元素会经由交换慢慢“浮”到数列的顶端。
冒泡算法的流程如下:
1 比较相邻的元素。如果第一个比第二个大,就交换他们两个。
2 对每一对相邻元素作同样的工作,从开始第一对到结尾的最后一对。在这一点,最后的元素应该会是最大的数, 即每次最大的元素都会被排到最后。
3 针对所有的元素重复以上的步骤,除了最后一个。
4 持续每次对越来越少的元素重复上面的步骤,直到没有任何一对数字需要比较。
其时间复杂度为O(n2),这个容易理解。
<span style="font-family:Times New Roman;font-size:18px;"># include<stdio.h>
# define SIZE 8
voidbubble_sort(int a[],int n);
voidbubble_sort(int a[],int n) //n为数组a的元素个数
{
int i,j,temp;
for(j=0;j<n-1;j++)
for(i=0;i<n-1-j;i++) //每次循环把最大的数放在最后,所以a[n-1-j]到a[n-1]是排好序的
{
if(a[i]>a[i+1])//数组元素大小按升序排列
{
temp=a[i];
a[i]=a[i+1];
a[i+1]=temp;
}
}
}
int main()
{
int number[SIZE]={95,45,15,78,84,51,24,12};
int i;
bubble_sort(number,SIZE);
for(i=0;i<SIZE;i++)
{
printf("%d",number[i]);
}
printf("\n");
}
</span>以上主要参考自http://baike.baidu.com/link?url=pzcHpcSEr-A8OjK-VZb-dKx2K0eb-oDwiCjmSN7hy8ekC_pelNk7j3sTpgiB_15yUqF9vTBr6kqbssg34JrNNq
此外,冒泡排序具体思想可参考 http://blog.csdn.net/doublelions/article/details/6402626















 504
504

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









