







算法导论第八章总结:线性时间排序
这一章首先证明了对于 n 个元素的输入序列来说,任何比较排序(最终的次序依赖于元素之间的比较的排序方法)在最坏情况下都要经过 Ω(n lgn ) 次比较。因此,归并排序和堆排序是渐进最优的,并且任何已知的比较排序最多就是在常数因子上优于它们。
之后讨论了三种线性时间复杂度的排序算法:计数排序、基数排序和桶排序。这些算法是用运算而不是比较来确定排序次序的。
一. 计数排序 P108~P110
计数排序假设 n 个输入元素中的每一个都是在0到k区间内的一个整数,其中 k 为某个整数。当 k =O(n) 时,排序的运行时间为 Θ (n)。
计数排序的基本思想是:对每一个输入元素 x,确定小于x的元素个数。利用这一信息,就可以直接把x放到它在输出数组中的位置上了。例如,如果有17个元素小于 x,则 x 就该在第18个输出位置上。当有几个元素相同时,这一方案要略做修改,因为不能把它们放在同一个输出位置上。
在计数排序算法的代码中,假设输入是一个数组 A[1…n],A.length =n。我们还需要两个数组:B [1…n] 存放排序的输出,C[0…k] 提供临时存储空间。
COUNTING-SORT (A,B,k)
1 let C [0…k] be a new array
2 for i = 0 to k
3 C[i] = 0
4 for j =1 toA.length
5 C[A[j]] = C[A[j]] + 1
// C[A[j]]是把A中等于i的元素放入C[i]中(A[j] = i),比如把A中值为2的元素
//放入到C[2]中,最后C[i]存的是A中值为i的元素的个数。
6 for i = 1 to k
7 C[i] =C[i] + C[i-1]
// C[i]存的是A中值小于等于i的元素的个数。
8 for j = A.length downto 1
9 B[C[A[j]]] = A[j]
10 C[A[j]] = C[A[j]] - 1
在第8~10行的 for 循环部分,把每个元素 A[j] 放到它在输出数组 B 中的正确位置上。如果所有元素都是互异的,那么当第一次执行第8行时,对每一个 A[j] 值来说,C[A[j] ]就是 A[j] 在输出数组中的最终正确位置。这是因为共有 C[A[j]] 个元素小于等于 A[j]。因为所有原色可能并不都是互异的,所以我们每将一个值 A[j] 放入数组 B 中以后,都要将 C[A[j]] 的值减1。这样,当遇到下一个值等于 A[j] 的输入元素(如果存在)时,该元素直接被放到输出数组中 A[j] 的前一个位置上。
整个操作过程如图1所示,以它为例说明一下具体过程,代码第8~10行 j = 8,A[j] = 3,C[A[j]] =C[3] = 7,含义就是 A 中小于等于3的元素有7个,并把该元素 A[j] = 3 放到 B 中第7个位置上。C[A[j]] – 1 表示 A 中小于等于3的元素减一个,下次再有 A[j] = 3 时放入到数组 B 的下标 C[A[j]] – 1 处。
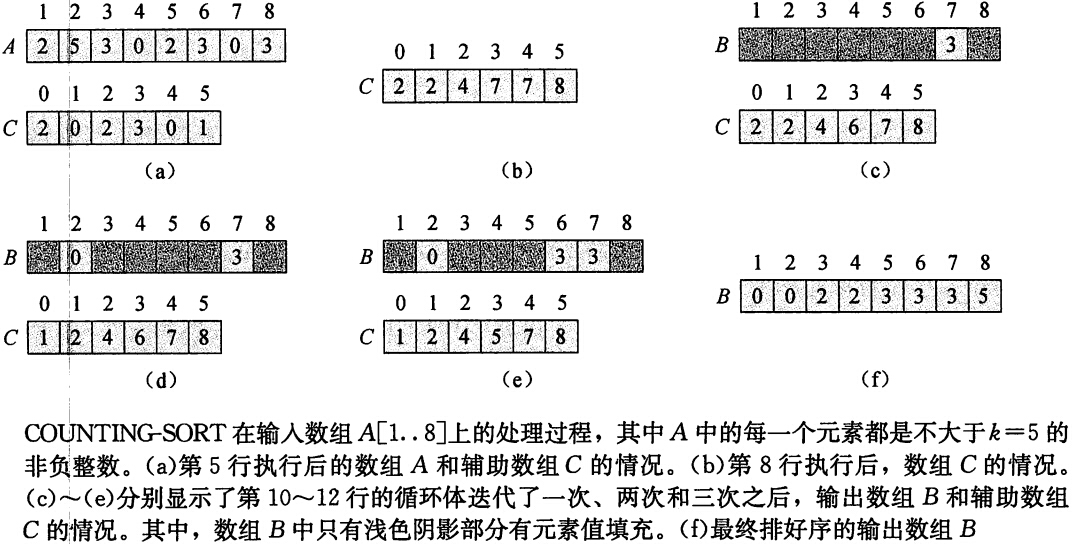
图1 计数排序流程图
计数排序的时间复杂度为 Θ (n),它使用输入元素的实际值来确定其在数组中的位置,脱离了比较模型。
计数排序另一大优点就是具有稳定性:具有相同值的元素在输出数组中的相对次序与它们在输入数组中的相对次序相同。也就是说,对两个相同的数,在输入数组中先出现的,在输出数组中也位于前面,可见图1(c) 和 (e)。这种稳定性只有当进行排序的数据还附带卫星数据时才比较重要。还有就是:计数排序经常会被用作基数排序的一个子过程。
计数排序的缺点就是得知道输入元素的取值范围,即 k。还有就是需要额外的空间 C,而且当 A 中取值较大或者有一个值较大时,C 的范围就必须很大。比如 A 中大部分元素很小,而有个元素是100000,那么 C 的大小就得从0到100000,尽管其中大部分元素取值为零。
二. 基数排序 P110、P111
基数排序,我的理解就是对要排序的所有数组元素的每个对应数位进行计数排序,并将结果综合得到基数排序的结果。
基数排序是先按最低有效位来进行排序的,即先比较个位,然后十位、百位,依次类推。书中说明了不采用最高有效位进行排序的原因,但是我没有很理解,网上查了些资料,可见 http://www.zhihu.com/question/27021728。RADIX-SORT (A ,d)
for i =1 to d
use a stable sort to sort array A on digit (counting-sort )
基数排序的时间代价依赖于所使用的稳定排序算法。当每位数字都在0到 k-1 区间内,且 k 不太大时,比如 k = 10,计数排序是个好选择。对 n 个 d 位数来说,每轮排序耗时Θ (n+k)。共有d 轮,因此基数排序总时间为 Θ (d (n+ k))。而当 d 为常数且 k=O (n) 时,基数排序具有线性时间代价。
三. 桶排序 P112~P114
桶排序假设输入数据服从均匀分布,平均情况下它的时间代价为O(n)。桶排序假设输入是由一个随机过程产生,该元素将元素均匀、独立地分布在 [0,1)区间上。
桶排序将[0,1)区间划分为n个相同大小的子区间,或称为桶。然后,将 n 个输入数分别放在各个桶中。因为输入数据是均匀、独立地分布在[0,1)区间上,所以一般不会出现很多数落在同一个桶中的情况。为了得到输出结果,我们先对每个桶中的数进行排序,然后遍历每个桶,按照次序把各个桶中的元素列出来即可。
在桶排序的代码中,我们假设输入是一个包含 n 个元素的数组 A,且每个元素 A[i] 满足0 ≤ A[i] < 1。此外,算法还需要一个临时数组 B [0.。。n - 1] 来存放链表(即桶),并假设存在一种用于维护这些链表的机制。
BUCKET-SORT(A)
1 n= A.length
2 let B[0…n - 1] be a new array
3 for i = 0 to n-1
4 make B[i] an empty list
5 for i =1 to n
6 insert A[i] into list
7 for i = 0 to n -1
8 sort list B[i] with insertion sort
9 concatenate the lists B[0],B[1],…,B[n-1] together
图2 显示了在一个包含10个元素的输入数组上的桶排序过程。
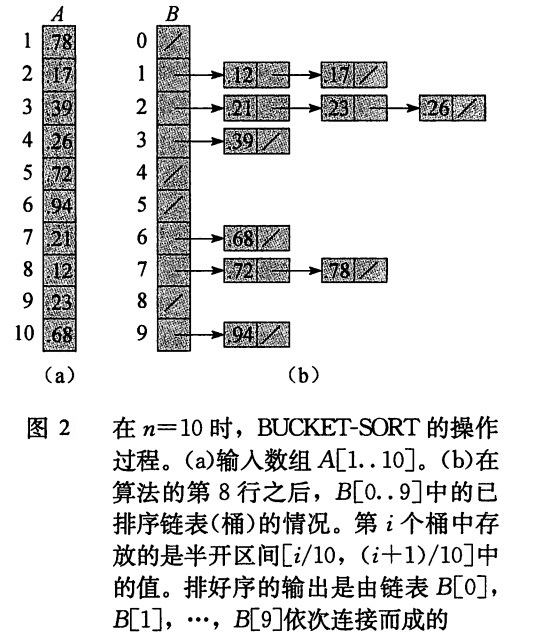
桶排序的期望运行时间为 :Θ(n) + n ∙O(2 – 1/n) = Θ (n)。证明过程见书上113页。
即使输入数据不服从均匀分布,桶排序依然可以线性时间内完成。只要输入数据满足下列性质:所有桶的大小的平方和与总的元素数呈线性关系。















 376
376

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









