







由于链表本身结构的单一性,链表的题目很少会有很大的变种,基本都是围绕几个基本的考点出题目。所以链表的题目比较好掌握,但是链表的题目又不太容易一次就AC通过,由于边界情况未考虑、空指针(比如head.next不存在但是却给head.next赋值了,就会抛出nullpointer的错误)、越界等边界情况,我们需要在测试用例的时候多考虑边界条件。在模拟计算的时候一定要用纸和笔把中间的操作过程给画出来,这样比较容易形成思路。
在LintCode的ladder1中,链表那一章有如下这一些题目:
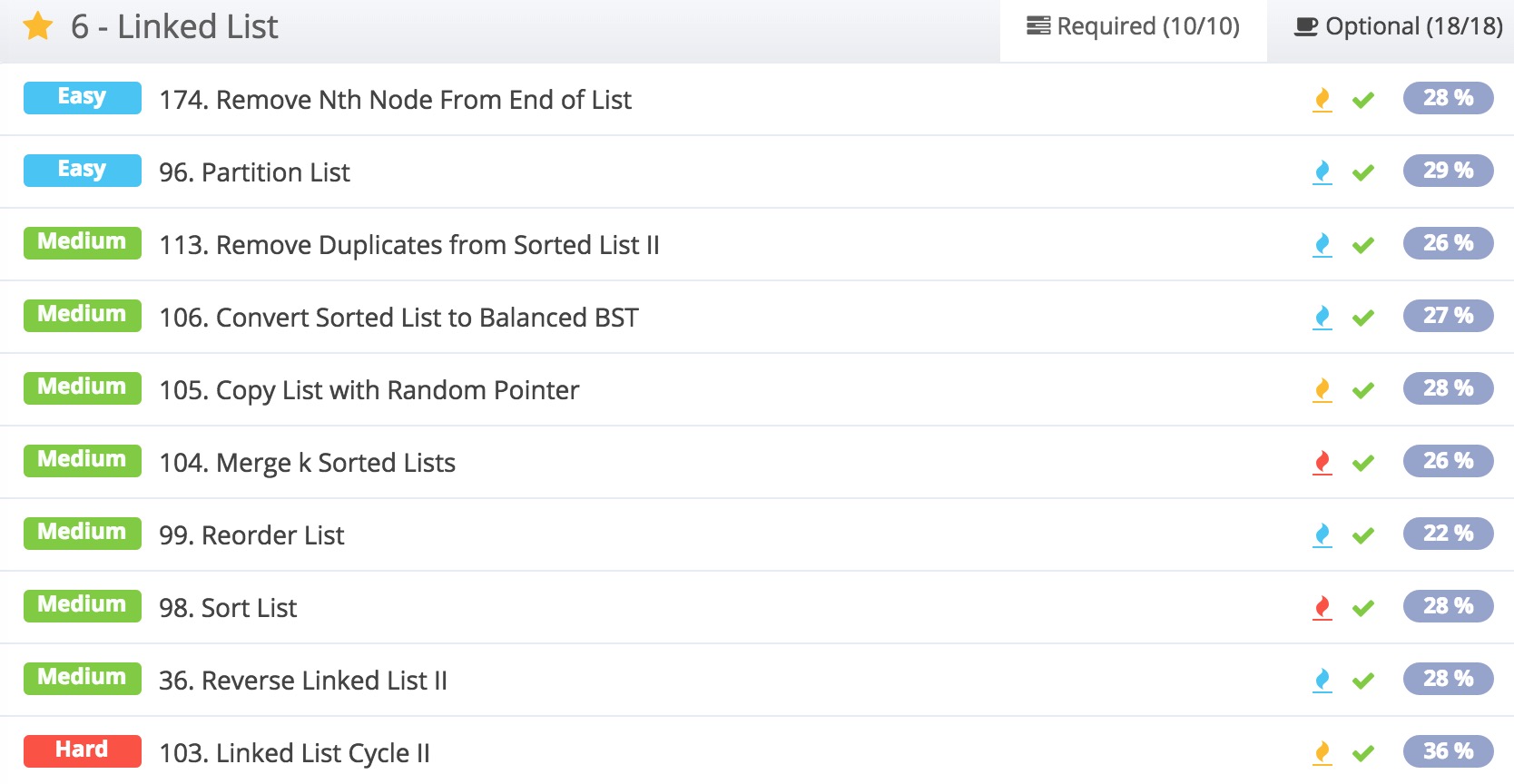
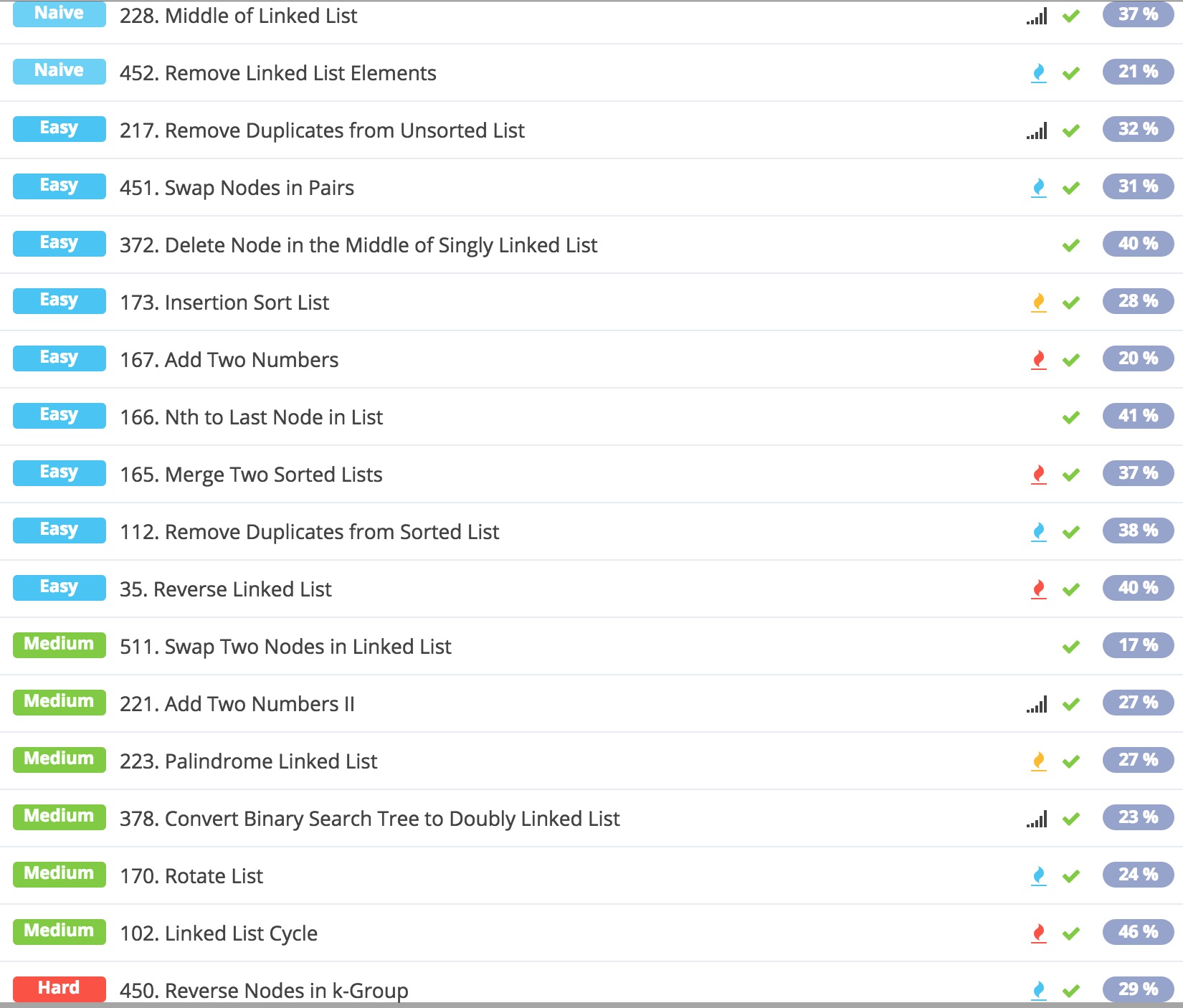
此外,LintCode的LinkedList标签下面还有380. Intersection of Two Linked Lists 以及 134. LRU Cache这两道题。
基本上把这些题目做完,链表的题目就差不多十拿九稳了。
我们来一道一道看看这几道题的解法。
1)174. Remove Nth Node From End of List
这道题是要删除链表的倒数第n个节点,也就是从链表末尾开始计数。是一道典型的双指针/快慢指针解法题,就预先将2个指针设置相互之间的距离为n,然后同时遍历链表,当fast快指针的下一个节点是null的时候,slow慢指针的下一个元素就是要删除的节点了。然后把slow的next设置为要删除的节点的下一个节点就OK了。但是需要考虑几个特殊情况,a)当输入的n小于等于0的时候 || 当输入的n大于链表长度的时候 || 链表为空 || 链表只有一个节点的时候,返回null;b)当n等于链表长度(即要删除的是第一个节点的时候),返回head的next就好。(这道题如果用加dummy节点的做法来做的话,代码会简洁一些。)
这道题对链表进行分区,对于输入的x,链表中所有value小于x的节点都在x的左边,所有value大于x的节点都在x的右边。这道题我的解法很直白,就是直接新键2个dummy节点,分别用于存放链表中小于x的节点和链表中大于等于x的节点。然后把这两个list合并起来,返回就好。(注意考虑链表为空返回null)
3)113. Remove Duplicates from Sorted List
这道题要在有序链表中删除重复的元素,所有的重复元素都要删除。思路也很简单,就是遍历链表,记得用dummy节点。从头结点扫描到尾节点,中间如果一旦找到重复的就开始一个子循环,子循环里面做删除操作(即将当前的next指向下一个节点的next)。(注意考虑链表为空 || 链表只有一个元素 返回null)
4)106. Convert Sorted List to Balanced BST
这道题要把一个有序链表转换为平衡二叉搜索树。我的代码如下:
private TreeNode buildTree(ListNode begin, ListNode end) {
if (begin == end) {
return null;
}
ListNode fast = begin, slow = begin;
while (fast.next != end && fast.next.next != end) {
slow = slow.next;
fast = fast.next.next;
}
fast = slow.next;
TreeNode root = new TreeNode(slow.val);
root.left = buildTree(begin, slow);
root.right = buildTree(fast, end);
return root;
}
public TreeNode sortedListToBST(ListNode head) {
if (head == null) {
return null;
}
if (head.next == null) {
return new TreeNode(head.val);
}
return buildTree(head, null);
}
5)105. Copy List with Random Pointer
这道题就是要对一个链表进行深拷贝,不过这不是一个简单的链表,每个链表节点除了有next指针外,还有一个random指针指向随机的元素。思路就是对于next节点先做一次拷贝,存放在原节点后面。然后再对random指针进行拷贝(说是拷贝,其实是改变random指针所指的节点)。然后再对原链表进行split操作就可以了。可以对照着代码在纸上画一画模拟操作就更加明白了:

代码如下:
private void copyNext(RandomListNode head) {
while (head != null) {
RandomListNode tmp = new RandomListNode(head.label);
tmp.next = head.next;
tmp.random = head.random;
head.next = tmp;
head = head.next.next;
}
}
private void copyRandom(RandomListNode head) {
while (head != null) {
if (head.next.random != null) {
head.next.random = head.random.next;
}
head = head.next.next;
}
}
private RandomListNode splitList(RandomListNode head) {
RandomListNode newHead = new RandomListNode(0);
newHead.next = head;
RandomListNode toReturn = newHead;
while (newHead.next != null) {
newHead.next = newHead.next.next;
newHead = newHead.next;
}
// newHead.next = null;
return toReturn.next;
}
public RandomListNode copyRandomList(RandomListNode head) {
if (head == null) {
return null;
}
copyNext(head);
copyRandom(head);
return splitList(head);
}
我的思路就是不断地两两之间merge,这样进行k-1次两两之间的merge操作就可以了。
这道题对链表进行重新排序,原链表为:L0 → L1 → … → Ln-1 → Ln;要将它变为:L0 → Ln → L1 → Ln-1 → L2 → Ln-2 → …
我的思路就是先对原链表进行反转,然后再逐个的把原链表和反转链表进行合并。合并不需要遍历完整个链表,只需要遍历到一半就好,所以还需要一个函数来计算一下链表长度。
对链表进行排序,建议最好分别用归并排序和快排实现一次。归并排序简单一点,快排稍微难一点。这道题一下子还是挺难写出来的,建议多看看程序:http://www.jiuzhang.com/solutions/sort-list/
这道题对链表进行区间内的反转。比如给定 1->2->3->4->5->NULL, m = 2 并且 n = 4, 需要返回 1->4->3->2->5->NULL
和反转全部链表的代码区别就在于需要找到反转开始的地方和结束的地方。代码如下:
public ListNode reverseBetween(ListNode head, int m , int n) {
if (head == null || head.next == null) {
return head;
}
ListNode dummy = new ListNode(0);
dummy.next = head;
head = dummy;
for (int i = 1; i < m; i++) {
if (head == null) {
return null;
}
head = head.next;
}
ListNode newHead = head;
head = head.next;
ListNode tail = head;
ListNode prev = null;
for (int i = m; i <= n; i++) {
ListNode tmp = head.next;
newHead.next = head;
head.next = prev;
prev = head;
head = tmp;
}
tail.next = head;
return dummy.next;
}10)103. Linked List Cycle II
找到一个链表中循环开始的节点。
Like the picture shows below: assume linked list has cycle,the length of cycle is Y,the length outside cycle is X
two pointers, one goes one step per time, another goes two steps per time. If they went t times and meet at the K node
for pointer 1: t = X+nY+K
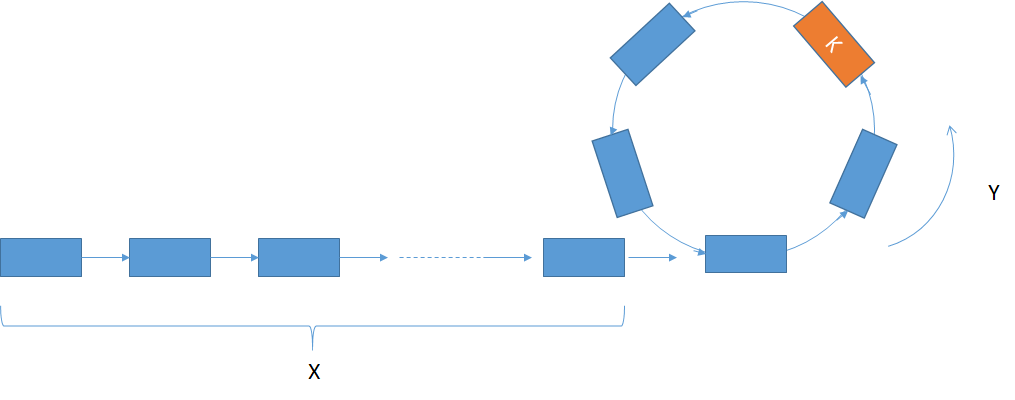
for pointer 2: 2t = X+mY+K (m,n is unknown)
From above equation, we could get:
2X + 2nY + 2K = X + mY + K
=> X+K = (m-2n)Y
It is clear that the relationship between X and K is complementary based on Y. Which is to say, if pointer 1 goes X steps from start node and pointer 2 goes X steps form K node. They will meet at the start place of cycle. Complexity is O(n)
数学证明如上所示,所以如果用快慢指针,然后快慢指针在某个点相遇了之后,我从头结点走k步,同时慢指针也走k步,他两将在循环开始的地方相遇。
代码如下所示:
public ListNode detectCycle(ListNode head) {
ListNode slow = head;
ListNode fast = head;
while(fast != null && fast.next != null){
slow = slow.next;
fast = fast.next.next;
if(slow == fast)
break;
}
if(fast == null || fast.next == null)
return null;
slow = head;
while(slow != fast){
slow = slow.next;
fast = fast.next;
}
return fast;
}需要注意的是,如果我们将快慢指针初始化为fast = slow.next的话,那么为了处理循环开始的地方是头结点head的情况,代码应该如下这么写才对:
public ListNode detectCycle(ListNode head) {
if (head == null || head.next == null) {
return null;
}
ListNode fast = head.next, slow = head;
while (slow != fast) {
if (fast == null || fast.next == null) {
return null;
}
fast = fast.next.next;
slow = slow.next;
}
while (head != slow.next) {
slow = slow.next;
head = head.next;
}
return head;
}读者可以在纸上画画,细细体味其中的奥妙。
比较简单,找到链表的中点,用快慢指针扫描,当快指针到达链表末尾时,返回慢指针就可以了。
12)452. Remove Linked List Elements
比较简单,删除链表中所有等于给定val的节点,遍历一次链表,如果发现有节点的val等于指定val,就删除它(previous的next指向下一个)。需要用到dummy节点。
13)217. Remove Duplicates from Unsorted List
比较简单,删除无序链表中的重复元素,需要用到HashSet和dummy节点。如果元素在HashSet中出现了就删除,未出现就加入HashSet。
比较简单,成对的交换链表中的节点,每两两之间交换位置。1->2->3->4 变为 2->1->4->3。需要用到dummy节点,然后遍历链表,两两之间互换元素。
15)372. Delete Node in the Middle of Singly Linked List
比较简单,给定链表中的某个节点,要求只删除它。由于没法从头遍历整个链表,所以无从得知那个节点前面的节点是啥。所以只有把要删除的节点的val设置为下一个节点的val,然后再把它给remove掉。
对链表进行插入排序,需要用到dummy节点。注意到插入排序的精髓就是当前的链表一定是有序的,然后需要插入的新节点就从前往后遍历,找到它合适的位置插入,如此循环往复。
对链表的节点进行加法运算,Given 7->1->6 + 5->9->2. That is, 617 + 295. Return 2->1->9. That is 912. Given 3->1->5 and 5->9->2, return 8->0->8
增加一个carry进位变量,然后同时遍历两个链表进行模拟加法运算,最后如果两个链表遍历完后有剩余,再把剩余的节点加上去就好。代码如下:
public ListNode addLists(ListNode l1, ListNode l2) {
if (l1 == null || l2 == null) {
return null;
}
ListNode head = new ListNode(0);
ListNode p = head;
int carry = 0;
while (l1 != null && l2 != null) {
int sum = l1.val + l2.val + carry;
carry = sum / 10;
sum = sum % 10;
p.next = new ListNode(sum);
p = p.next;
l1 = l1.next;
l2 = l2.next;
}
while (l1 != null) {
int sum = l1.val + carry;
carry = sum / 10;
sum = sum % 10;
p.next = new ListNode(sum);
p = p.next;
l1 = l1.next;
}
while (l2 != null) {
int sum = l2.val + carry;
carry = sum / 10;
sum = sum % 10;
p.next = new ListNode(sum);
p = p.next;
l2 = l2.next;
}
if (carry != 0) {
p.next = new ListNode(carry);
}
return head.next;
}
18)166. Nth to Last Node in List
比较简单,返回链表的倒数第n个节点。用快慢指针法,快慢指针初始化为相距n,然后同时遍历链表。当快指针到达末尾的时候,返回慢指针即可。
19)165. Merge Two Sorted Lists
比较简单,对两个有序链表进行合并。用到dummy节点,然后逐个遍历2个节点,小的放在前,大的放在后。如果后面还有剩余,就再把剩余的元素加进链表来。
20)112. Remove Duplicates from Sorted List
比较简单,删除有序链表里的重复元素。如果下一个元素与当前元素相等,就把当前元素的next指针往后移,如此循环往复,直到扫描到尾节点为止。
反转链表,用到dummy节点代码量会简洁一点。就是不断地把元素加到dummy节点的后边。注意衔接前后的代码判断。
22)511. Swap Two Nodes in Linked List
指定位置,交换链表中的2个节点,注意是交换节点不是交换value。看起来简单,操作起来需要考虑一下边界情况,首先遍历链表找到2个节点的位置,m节点和n节点以及他们的前继节点的位置。如果m节点或者n节点找不到的话,就返回null。找到这两个节点后,First change next of previous pointers, then change next of current pointers。代码如下:
public ListNode swapNodes(ListNode head, int v1, int v2) {
ListNode dummy = new ListNode(0);
dummy.next = head;
head = dummy;
ListNode p1 = null, p2 = null, preP1 = null, preP2 = null;
// find the pos of 2 nodes
ListNode p = head;
while (p != null) {
if (p.next != null && p.next.val == v1) {
preP1 = p;
p1 = p.next;
}
if (p.next != null && p.next.val == v2) {
preP2 = p;
p2 = p.next;
}
p = p.next;
}
if (p1 == null || p2 == null) {
return dummy.next;
}
// swap 2 nodes
// first change the next of preP, then change the next of 2 nodes
preP1.next = p2;
preP2.next = p1;
ListNode tmp = p1.next;
p1.next = p2.next;
p2.next = tmp;
return dummy.next;
}
这道题是 17)167. Add Two Numbers 的变种,基本思路与这道题一样,只不过需要和反转链表的函数配合来解决。
24)223. Palindrome Linked List
判断链表是不是回文串,就先把链表反转,然后再从头到尾遍历,看反转链表和原链表是否一样。如果一样就是回文串,若不一样就不是回文串。
25)378. Convert Binary Search Tree to Doubly Linked List
将二分搜索树转换为双向链表。思路就是用中序遍历+Queue队列,中序遍历完的结果保存在队列中,然后再把队列中的元素逐个拿出来建立双向链表。代码如下:
private void inorder(TreeNode root, Queue<Integer> q) {
if (root != null) {
inorder(root.left, q);
q.offer(root.val);
inorder(root.right, q);
}
return;
}
public DoublyListNode bstToDoublyList(TreeNode root) {
if (root == null) {
return null;
}
Queue<Integer> q = new LinkedList<Integer>();
inorder(root, q);
DoublyListNode head = new DoublyListNode(q.poll());
DoublyListNode p = head;
while (q.isEmpty() == false) {
DoublyListNode tmp = new DoublyListNode(q.poll());
p.next = tmp;
tmp.prev = p;
p = p.next;
}
return head;
}对链表进行移位,Given 1->2->3->4->5 and k = 2, return 4->5->1->2->3。利用快慢指针,找到分叉点的位置,把他们断开,然后再重新合并起来。
判断链表中是否有循环。就用快慢指针。如果两个指针相等了,就代表存在循环。
28)450. Reverse Nodes in k-Group
以k个元素为小组,分别对小组内的元素进行反转。Given this linked list: 1->2->3->4->5 For k = 2, you should return: 2->1->4->3->5 For k = 3, you should return: 3->2->1->4->5
算是反转链表的变种题,代码如下:
private boolean canGo(ListNode head, int k) {
int count = 0;
ListNode p = head;
while (p != null) {
count++;
p = p.next;
if (count >= k) {
return true;
}
}
return false;
}
public ListNode reverseKGroup(ListNode head, int k) {
if (k == 1) {
return head;
}
ListNode dummy = new ListNode(0);
ListNode tail = dummy;
while (canGo(head, k) == true) {
ListNode last = null;
for (int i = 1; i <= k && head != null; i++) {
ListNode tmp = head.next;
tail.next = head;
head.next = last;
last = head;
head = tmp;
}
for (int i = 1; i <= k && tail != null; i++) {
tail = tail.next;
}
}
if (head != null) {
tail.next = head;
}
return dummy.next;
}29)380. Intersection of Two Linked Lists
A: a1 → a2
↘
c1 → c2 → c3
↗
B: b1 → b2 → b3 private int calLength(ListNode head) {
int count = 0;
while (head != null) {
count++;
head = head.next;
}
return count;
}
public ListNode getIntersectionNode(ListNode headA, ListNode headB) {
int aLength = calLength(headA);
int bLength = calLength(headB);
int toGo = Math.abs(aLength - bLength);
if (aLength > bLength) {
for (int i = 0; i < toGo; i++) {
headA = headA.next;
}
} else {
for (int i = 0; i < toGo; i++) {
headB = headB.next;
}
}
while (headA != null && headB != null) {
if (headA == headB) {
return headA;
}
headA = headA.next;
headB = headB.next;
}
return null;
} Design and implement a data structure for Least Recently Used (LRU) cache. It should support the following operations: get and set.
get(key) - Get the value (will always be positive) of the key if the key exists in the cache, otherwise return -1.
set(key, value) - Set or insert the value if the key is not already present. When the cache reached its capacity, it should invalidate the least recently used item before inserting a new item.
- 题目大意:为LRU Cache设计一个数据结构,它支持两个操作:
1)get(key):如果key在cache中,则返回对应的value值,否则返回-1
2)set(key,value):如果key不在cache中,则将该(key,value)插入cache中(注意,如果cache已满,则必须把最近最久未使用的元素从cache中删除);如果key在cache中,则重置value的值。
- 解题思路:题目让设计一个LRU Cache,即根据LRU算法设计一个缓存。在这之前需要弄清楚LRU算法的核心思想,LRU全称是Least Recently Used,即最近最久未使用的意思。在操作系统的内存管理中,有一类很重要的算法就是内存页面置换算法(包括FIFO, LRU, LFU等几种常见页面置换算法)。事实上,Cache算法和内存页面置换算法的核心思想是一样的:都是在给定一个限定大小的空间的前提下,设计一个原则如何来更新和访问其中的元素。下面说一下LRU算法的核心思想,LRU算法的设计原则是:如果一个数据在最近一段时间没有被访问到,那么在将来它被访问的可能性也很小。也就是说,当限定的空间已存满数据时,应当把最久没有被访问到的数据淘汰。
我们可以利用链表和HashMap来实现,链表用于存放数据,链表尾部代表最近使用过的数据,链表头部是很久都没有用过的数据。如果读写的数据在链表中存在(命中),就把那个节点移动到链表尾部。这样一来在链表尾部的节点就是最近访问过的数据项。
由于在链表中遍历查找太费时间了,我们采取用空间换时间的策略,加上HashMap,查找的时候在HashMap中查找,直接对应到那个节点来进行操作,这样就可以极大的加快我们访问的速度。
当需要get(获取)数据的时候,如果数据在HashMap中不存在(即在链表中不存在),那么就返回-1。如果存在的话,就把那个节点移动到尾部,然后再返回它的值。
当需要set(设置)数据的时候,如果数据在HashMap中存在,就更新一下它的值,然后把那个节点移动到链表尾部。如果数据在HashMap中不存在,那就首先判断一下是否容量已经达到上限了,如果容量达到上限,就先把头结点删了(否则就没有足够的空间可以用来插入数据);确保空间足够的话,然后再把新建的节点插入到链表尾部,并同时添加进HashMap中。
代码如下:
public class Solution {
private class Node {
int key;
int value;
Node prev;
Node next;
public Node(int key, int value) {
this.key = key;
this.value = value;
this.prev = null;
this.next = null;
}
}
private int capacity;
private Node head = new Node(-1, -1);
private Node tail = new Node(-1, -1);
private HashMap<Integer, Node> hash = new HashMap<Integer, Node>();
// @param capacity, an integer
public Solution(int capacity) {
this.capacity = capacity;
head.next = tail;
tail.prev = head;
}
private void moveToTail(Node current) {
current.next = tail;
current.prev = tail.prev;
current.prev.next = current;
current.next.prev = current;
}
// @return an integer
public int get(int key) {
if (!hash.containsKey(key)) {
return -1;
}
// remove current
Node current = hash.get(key);
current.prev.next = current.next;
current.next.prev = current.prev;
// move to tail
moveToTail(current);
return current.value;
}
// @param key, an integer
// @param value, an integer
// @return nothing
public void set(int key, int value) {
if (get(key) != -1) {
hash.get(key).value = value;
return;
}
if (hash.size() == capacity) {
hash.remove(head.next.key);
head.next = head.next.next;
head.next.prev = head;
}
Node insert = new Node(key, value);
hash.put(key, insert);
moveToTail(insert);
}
}总结一下的话,链表的题目整体来说还是比较容易掌握的。注意一定要用纸上画一画、模拟一下操作,这样形成的思路较为清晰。然后多注意考虑边界情况。无非就是用到dummy节点、快慢指针、反转链表、增删查改创建、归并之类的知识点。如果链表的结构需要改变的话,最好加上dummy节点来作为帮助,这样写出来的代码会更加简洁。















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









