







前后端开发模式
补充知识:
后端开发工程师在写前端的时候,有两个前端的后台管理模板可以供我们使用
- x-admin:这个是国人基于layui+jquery写的后台管理系统模板
- admin-lte:这个是外国人基于bootstrap+jquery写的后台管理系统模板
由于现在前后端分离的开发模式使用度,x-admin已经不更新了
两种开发模式:
-
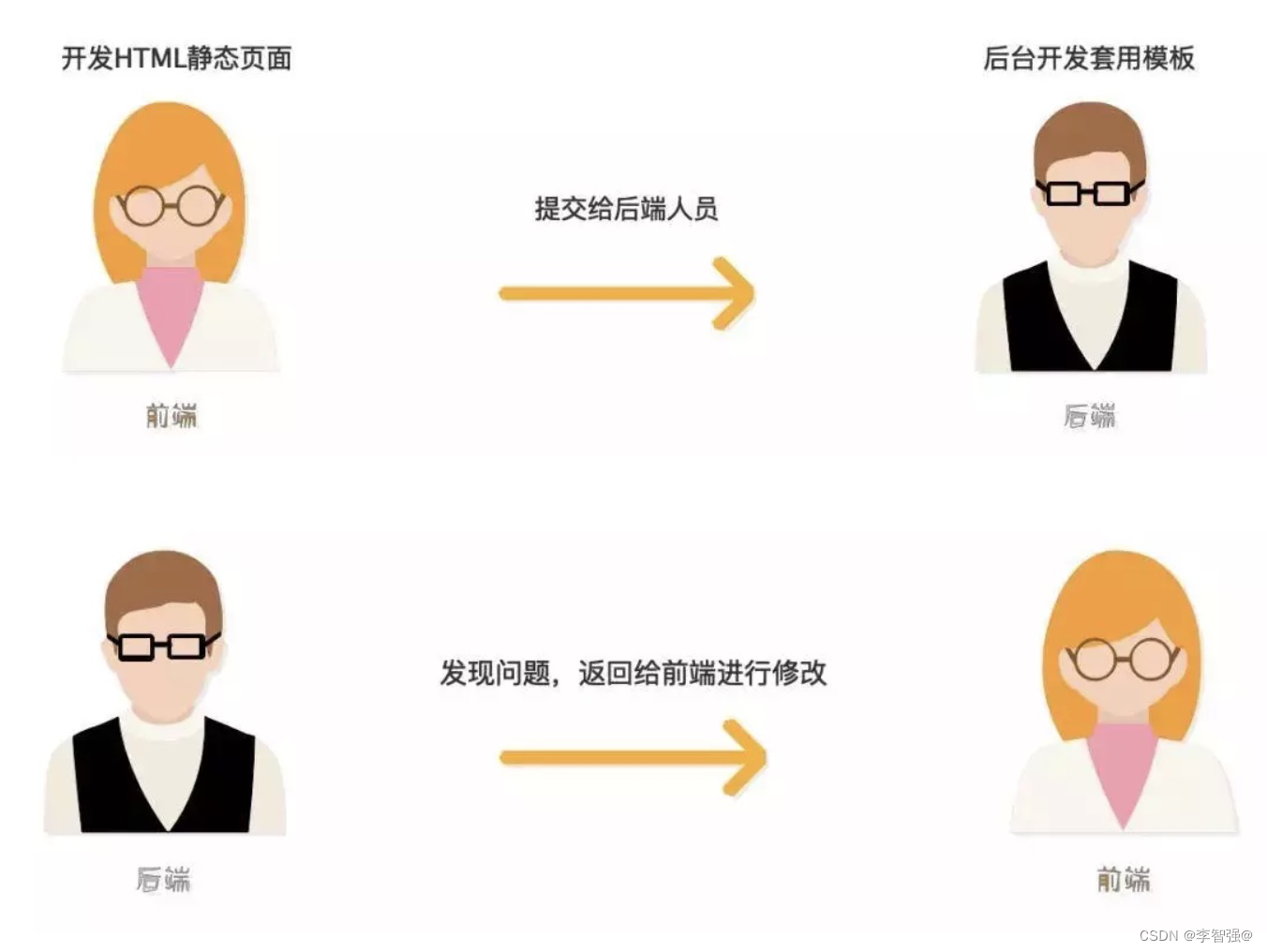
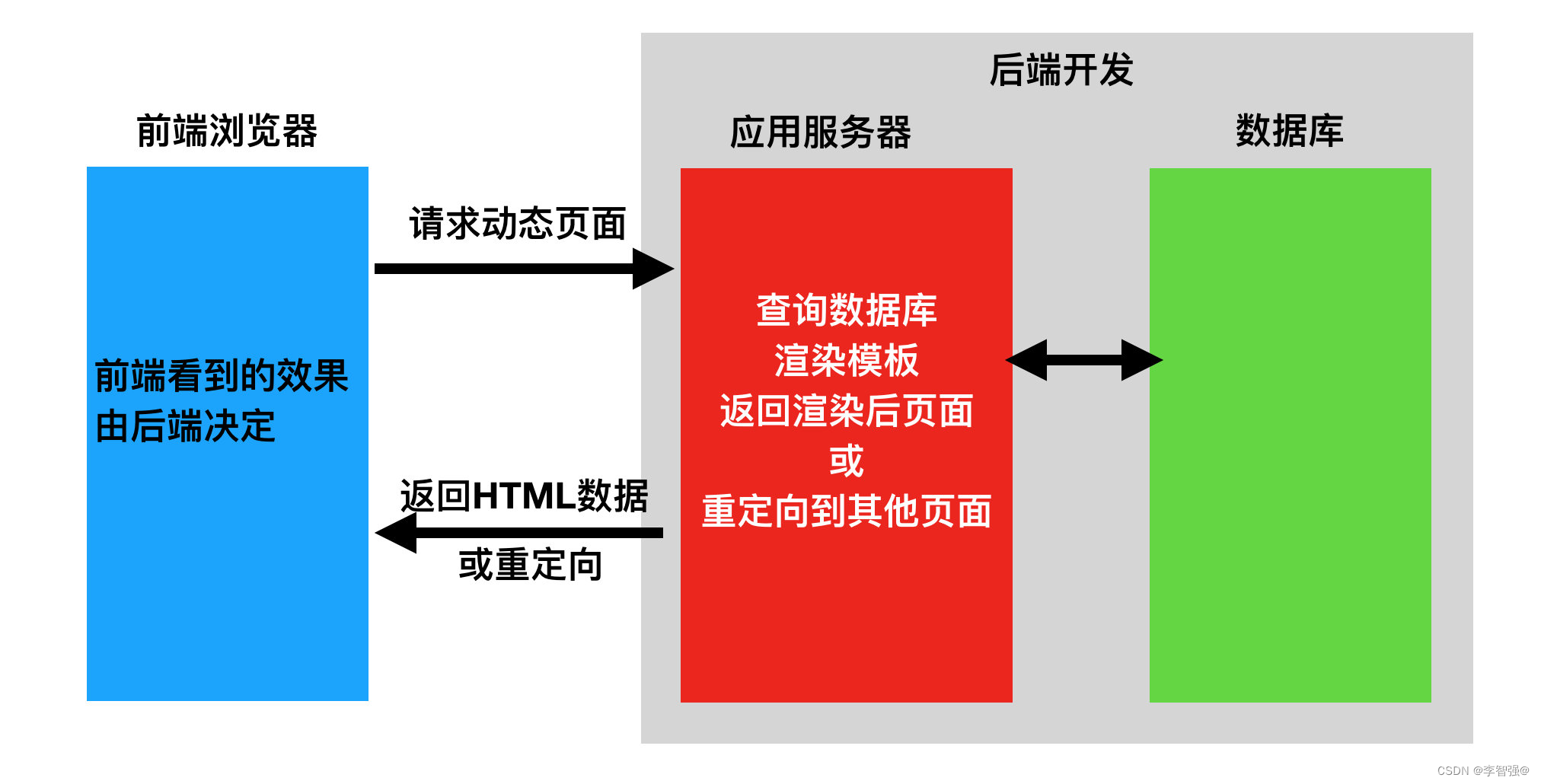
前后端混合开发(通过模板语法渲染)- 前端写好静态的html页面交付给后端开发。静态页面可以本地开发,也无需考虑业务逻辑只需要实现View即可。
- 后端使用模板引擎去套模板,同时内嵌一些后端提供的模板变量和一些逻辑操作
- 然后前后端集成对接,遇到问题,前端返工,后端返工
- 然后在集成,直至集成成功
这种模式的劣势:
在前端调试的时候要安装完整的一套后端开发工具,要把后端程序完全启动起来。遇到问题需要后端开发来帮忙调试。我们发现前后端严重耦合,还要要求后端人员会一些HTML,JS等前端语言。前端页面里还嵌入了很多后端的代码。一旦后端换了一种语言开发,简直就要重做。
像这种增加了大量的沟通成本,调试成本等,而且前后端的开发进度相互影响,从而大大降低了开发效率。
-
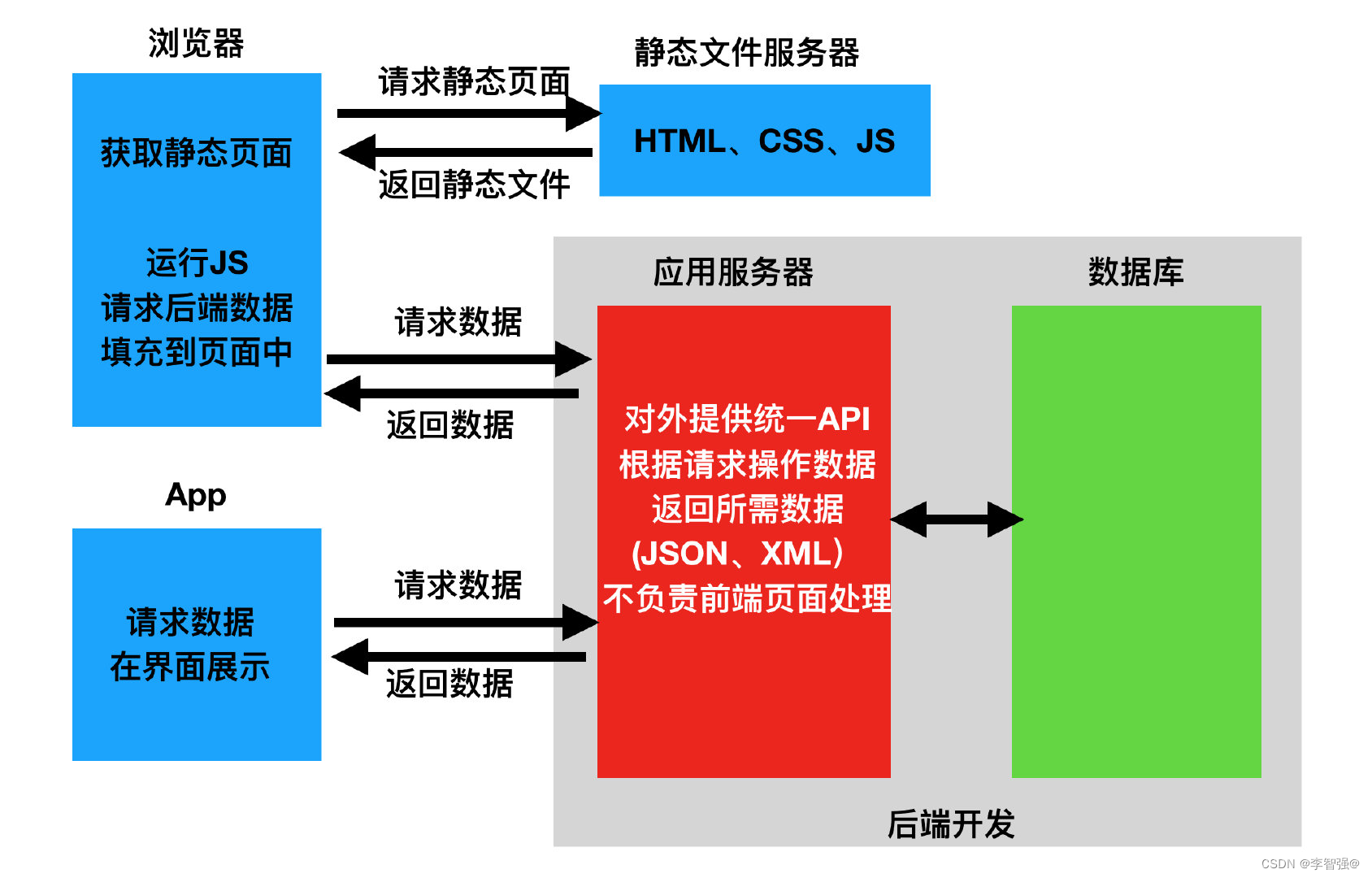
前后分离前后端分离并不是爱发模式,而是web应用的一种架构。在开发阶段,前后端工程师约定好交互的接口,实现并行开发和测试;在运行阶段前后端分离模式需要对web应用进行分离部署,前后端之前要使用HTTP协议或者其他协议进行交互请求。
- 后端人员只需要负责写接口(API接口),使用postman接口测试工具测试
- 前端人员负责写前端,写的过程中使用mock数据
- 最后:前后端联调项目
API接口
理解API
API(Application Programming Interface,应用程序编程接口)
是一些预先定义的函数,目的是提供应用程序与开发人员基于某软件或硬件的以访问一组例程的能力,而又无需访问源码,或理解内部工作机制的细节。API除了有应用“应用程序接口”的意思外,还特指 API的说明文档,也称为帮助文档。
通过网络,规定前后台信息的交互规则的url链接,,也就是实现前后端信息交互的媒介
作用
应用程序接口是一组定义,程序及协议的集合,通过API接口实现计算机软件之间的相互通信,API主要的一个功能是提供通用功能集。程序员通过调用API接口函数对应用程序进行开发,可以减轻编程的任务。API同时也是一种中间件,为不同的平台提供数据共享。
API接口的格式
-
url:长的像返回数据的url链接
eg:https://api.map.baidu.com/place/v2/search(一般都会带有api的标识,还有可能会带有版本标识) -
请求方式:get,post,put,patch,delete
采用get方式请求上方接口 -
请求参数:json或xml格式的key-value类型数据
ak:6E823f587c95f0148c19993539b99295
region:上海
query:肯德基
output:json -
响应结果:json或xml格式的数据
接口测试工具postman
API接口写好,后端人员需要自己先测试一下,但是我们又不可能在浏览器中去测试
使用postman软件,来做接口测试(本质就是:模拟发送http请求)
接口测试软件有很多:eg:postwoman(根据postman修改的)
官方下载:https://www.postman.com/downloads/
直接双击即可安装
restful规范
简介
REST全称是Representational State Transfer,中文意思是表述:表征性状态转移, 它首次出现在2000年Roy Fielding的博士论文中
RESTful是一种定义Web API接口的设计风格,尤其适用于前后端分离的应用模式中
restful规范有10点规范,公司有自己的风格规范
-
数据的安全保障:url链接一般都是采用https协议进行数据传输(更加安全)
https就是http+ssl/tsl -
接口中带有api关键词 -
多数据版本共存:一个接口可能有多个版本(url链接中带有版本标识) -
数据即是资源,均使用名词(可用复数)——接口尽量使用名字
存在一个问题:如果都是用名词,就没法区分是增加,删除,修改,查询 -
资源操作由请求方式决定- 获取数据:get请求
- 删除数据:delete请求
- 新增数据:post请求
- 修改数据:put/patch请求
- 请求的地址一样,通过请求方式决定对资源进行什么操作
-
url地址中带过滤参数
- 获取动物园中所有的动物:127.0.0.1/api/v1/animals——get请求方式
- 获取动物园所有哺乳类动物:127.0.0.1/v1/animals/?type=哺乳类——get请求
-
响应带状态码
- http状态码:http://tools.jb51.net/table/http_status_code
- 1xx:表示请求正在处理,但是我们一般是看不到得
- 2xx:表示请求处理成功(200, 201)
- 3xx:重定向(301, 302)
- 4xx:客户端出现错误(403, 404)
- 5xx:服务端出现错误
- 响应体中写状态码:公司里都是有自己得规范,在响应体中写状态码({‘code’:100})
- http状态码:http://tools.jb51.net/table/http_status_code
-
返回错误信息(响应体中带错误信息)
{‘code’:101, ‘msg’:‘错误’} -
返回结果,针对不同操作,服务器向用户返回得结果应该符合以下格式:
- GET /collection:返回资源对象得列表
- GET /collection/resource:返回单个资源对象
- POST /collection:返回新生成得资源对象
- PUT /collection/resource:返回完整得资源对象
- PATCH /collection/resource:返回完整的资源对象
- DELETE /collection/resource:返回一个空文档
eg:
1.获取所有:{code:100,msg:成功,data:[{name:金瓶梅,price:99},{name:西游记,price:88}]}
2.获取单条:{code:100,msg:成功,data:{name:金瓶梅,price:99}}
3.新增数据:{code:100,msg:新增成功,data:{name:西游记,price:99}}
4.修改数据:{code:100,msg:修改成功,data:{name:西游记v2版本,price:99}}
5.删除数据:{code:100,msg:删除成功} -
响应中带链接
序列化和反序列化
API接口开发最核心的最常见额一个过程就是序列化,所谓序列化就是将数据转化格式,反序列化分为两个阶段:
序列化:就是将我们的格式转换为别人的数据格式
例如:我们在django中获取到的数据默认是模型对象(queryset),但是模型对象数据无法直接提供给前端或别的平台使用,所以我们需要把数据进行序列化,变成字符串或者json数据,提供给别人。反序列化:把别人提供的数据转换/还原成我们需要的格式
djangorestframework快速使用
下载模块:安装drf:pip3 install djangorestframework
使用django这个web框架,开发前后端分离项目(模板渲染),只写接口
使用JsonResponse返回即可---》原生django
djangorestframework方便咱们快速写出符合restful规范的接口
写接口:总共就5个以及这5个的变形
- 获取所有:get
- 获取单个:get
- 新增一条:post
- 修改一条:put/patch
- 删除一条:delete

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









