







上一篇有很多啰嗦,这篇做一些补充:
所有语言的字符都用同一种字符集来表示,这就是Unicode。
最初的Unicode标准UCS-2使用两个字节表示一个字符,所以你常常可以听到Unicode使用两个字节表示一个字符的说法。但过了不久有人觉得256*256太少了,还是不够用,于是出现了UCS-4标准,它使用4个字节表示一个字符,不过我们用的最多的仍然是UCS-2。
UCS(Unicode Character Set)还仅仅是字符对应码位的一张表而已,比如”汉”这个字的码位是6C49。字符具体如何传输和储存则是由UTF(UCS Transformation Format)来负责。
一开始这事很简单,直接使用UCS的码位来保存,这就是UTF-16,比如,”汉”直接使用\x6C\x49保存(UTF-16-BE),或是倒过来使用\x49\x6C保存(UTF-16-LE)。但用着用着美国人觉得自己吃了大亏,以前英文字母只需要一个字节就能保存了,现在大锅饭一吃变成了两个字节,空间消耗大了一倍……于是UTF-8横空出世。
UTF-8是一种很别扭的编码,具体表现在他是变长的,并且兼容ASCII,ASCII字符使用1字节表示。然而这里省了的必定是从别的地方抠出来的,你肯定也听说过UTF-8里中文字符使用3个字节来保存吧?4个字节保存的字符更是在泪奔……(具体UCS-2是怎么变成UTF-8的请自行搜索)
新的问题又出现了:如果统一成Unicode编码,乱码问题从此消失了。但是,如果你写的文本基本上全部是英文的话,用Unicode编码比ASCII编码需要多一倍的存储空间,在存储和传输上就十分不划算。所以,本着节约的精神,又出现了把Unicode编码转化为“可变长编码”的UTF-8编码。UTF-8编码把一个Unicode字符根
据不同的数字大小编码成1-6个字节,常用的英文字母被编码成1个字节,汉字通常是3个字节,只有很生僻的字符才会被编码成4-6个字节。如果你要传输的文本包含大量英文字符,用UTF-8编码就能节省空间。
总结一下现在计算机系统通用的字符编码工作方式:
在计算机内存中,统一使用Unicode编码,当需要保存到硬盘或者需要传输的时候,就转换为UTF-8编码。
记事本编辑的时候,从文件读取的UTF-8字符被转换为Unicode字符到内存里,编辑完成后,保存的时候再把Unicode转换为UTF-8保存到文件:
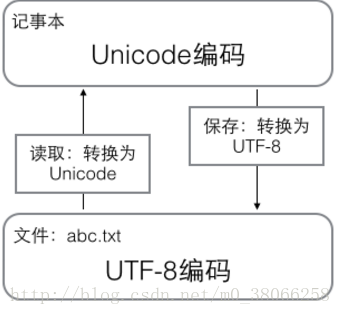
浏览网页的时候,服务器会把动态生成的Unicode内容转换为UTF-8再传输到浏览器:
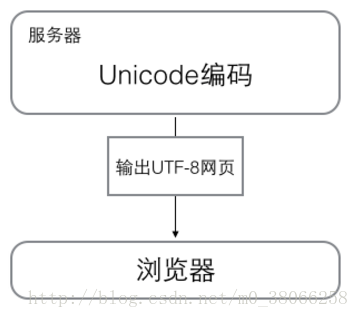
所以你看到很多网页的源码上会有类似的信息,表示该网页正是用的UTF-8编码。














 3408
3408











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









