






字符的表示原理
计算机内所有信息都是使用0和1进行表示的。
对于一个短路来说,0代表关,1代表开。那把这些电路组合起来就可以有长串0和1组成的二进制数字,我们对这些数字进行编码和解码,我们就能用它来表示我们想要表示的东西了。
比如:文字、图像、视频等等,就是一组0和1的二进制序列

知识点
8位二进制表示1字节
二进制太长,一般转换为16进制表示。可以使用“8421法”,进行转换。
4位二进制可以转为1位十六进制(1111=>F),2位十六进制表示一字节
字符不同的编码
1,在 ASCII 阶段,单字节字符串使用一个字节存放一个字符(SBCS)。比如,"Bob123" 在内存中为:
42 6F 62 31 32 33 21 //ascii编码
B o b 1 2 3 ! //字符
2,在使用 ANSI 编码支持多种语言阶段,每个字符使用一个字节或多个字节来表示(MBCS),因此, 这种方式存放的字符也被称作多字节字符。每个汉字占2个字节,每个英文和数字字符占1个字节:
D6 D0 CE C4 31 32 33 00
中 文 1 2 3 \0
复制代码3, 在 UNICODE 被采用之后,计算机存放字符串时,改为存放每个字符在 UNICODE 字符集中的序号。 目前计算机一般使用 2 个字节(16 位)来存放一个序号(DBCS),因此,这种方式存放的字符也被称作宽字节字符。比如,字符串 "中文123" 在 Windows 下,内存中实际存放的是 5 个序号:
\u4e2d \u6587 \u0031 \u0032 \u0033 (x64 大端序)
\u2d4e \u8765 \u3100 \u3200 \u3300 (x86 小端序)
中 文 1 2 3
汉子 ‘中’ \u4e2d 11101001 10110001 1001101
第一阶段(美国)
ASCII 码使用指定的7 位或8 位二进制数组合来表示128 或256 种可能的字符。标准ASCII 码也叫基础ASCII码,使用7 位二进制数(剩下的1位二进制为0)来表示所有的大写和小写字母,数字0 到9、标点符号, 以及在美式英语中使用的特殊控制字符。
其中: 1, 0~31及127(共33个)是控制字符或通信专用字符(其余为可显示字符),如控制符:LF(换行)、CR(回车)等
2, 32~126(共95个)是字符(32是空格),其中48~57为0到9十个阿拉伯数字。 65~90为26个大写英文字母,97~122号为26个小写英文字母,其余为一些标点符号、运算符号等。
3 , 在标准ASCII中,其最高位(b7)用作奇偶校验位。所谓奇偶校验,是指在代码传送过程中用来检验是否出现错误的一种方法,一般分奇校验和偶校验两种。奇校验规定:正确的代码一个字节中1的个数必须是奇数,若非奇数,则在最高位b7添1;偶校验规定:正确的代码一个字节中1的个数必须是偶数,若非偶数,则在最高位b7添1。
4, 后128个称为扩展ASCII码。许多基于x86的系统都支持使用扩展(或“高”)ASCII。扩展ASCII 码允许将每个字符的第8 位用于确定附加的128 个特殊符号字符、外来语字母和图形符号。[4]
第二阶段(百花齐放)
计算机技术到了欧洲,欧洲人发现怎么我们的那么多符号没有编进去啊!所以欧洲"砖家"坐到了一起,开始讨论。发现既然美国人把第一位流出来了,那么我们就用128-255的位置好了。 规则:128-159之间为控制字符,160-255位文字符号,其中包括了西欧语言、希腊语、泰语、阿拉伯语、希伯来语。刚好把美国人给的空间全部用完,世界真美好,谢谢美利坚预留的每一个位置。砖家们决定把他们的编码名称叫做Latin1,后面由于欧洲统一制定ISO标准,所以又有了一个ISO的名称,即ISO-8859-1。 实现方式 • 0-127的所有位置不动,那么可以兼容ASCII,二进制位0xxx xxxx • 128-255位置全部用完,二进制位1xxx xxxx 由于所有的位置全部用完,而欧元符号是在指定标准之后才出现的,所以在这个码表中连欧洲人自己的货币符号都没有办法放进去。
计算机技术当然也传到了亚洲大地,比如中国。 中国砖家们坐在一起发现,美国人搞的这个东西真的有问题,预留才128-255的空间,可是我们的汉字个数远远超出了这个数目啊,怎么办??后面聪明的中国砖家们发现,只能使用2个字节了,否则真的搞不定。由于必须和美国原来制定的ASCII不冲突,所以指定了如下规则:
• 如果一个字节中第一位为0,那么这就是一个ASCII字符。
• 如果一个字节中第一位为1,那么这个是汉字,认定需要2个字节才表示一个编码的文字。
复制代码把这个码表叫GB2312这个码表中包含汉字6763个和非汉字图形字符682个。还有很多的空间没有用到,索性全部预留了吧。实现方式 • 0xxxxxxx:表示为ASCII字符 • 1xxxxxxx 1xxxxxxx:表示为汉字
后来,中国砖家们发现,很多的不常用汉字没有在码表中,于是添加了很多的汉字进去,这个编码叫做GBK,实现方式和GB2312是完全一样的,兼容GB2312,当然也兼容ASCII。实现方式 • 0xxxxxxx:表示为ASCII字符 • 1xxxxxxx xxxxxxxx:表示为汉字
后面再次添加更多的字符进去,再次命名为GB18030,兼容GBK。由于汉字很多,2个字节并不能完全包括进去,所以GB18030采用2\4位混编的形式。 详细编码表可以参考这个列表。
当然计算机也传到了日本(JIS)、韩国、台湾(BIG5)等等地方,大家全部发挥自己的聪明才智,各自实现了自己的编码。这些编码都与ASCII兼容,但是相互之间不兼容。 使用 2 个字节来代表一个字符的各种汉字延伸编码方式,称为 ANSI 编码,又称为"MBCS(Muilti-Bytes Charecter Set,多字节字符集)”。
在简体中文系统下,ANSI 编码代表 GB2312 编码,在日文操作系统下,ANSI 编码代表 JIS 编码,所以在中文 windows下要转码成gb2312,gbk只需要把文本保存为ANSI编码即可。 不同ANSI编码之间互不兼容
GB2312
GB2312标准共收录6763个汉字,其中一级汉字3755个,二级汉字3008个;同时,GB 2312收录了包括拉丁字母、希腊字母、日文平假名及片假名字母、俄语西里尔字母在内的682个全角字符。
GB 2312的出现,基本满足了汉字的计算机处理需要,它所收录的汉字已经覆盖中国大陆99.75%的使用频率。
对于人名、古汉语等方面出现的罕用字,GB 2312不能处理,这导致了后来GBK及GB 18030汉字字符集的出现。
GB2312编码就是基于区位码的,用双字节编码表示中文和中文符号。
一般编码方式是:0xA0+区号,0xA0+位号。
如下表中的 “啊”,区位号是1601(十进制),那么“啊”字的GB2312编码就是 0xA0+16 0xA0+01 也就是 0xB0 0xA1 。根据区位码表,GB2312的汉字编码范围是0xB0A1~0xF7FE
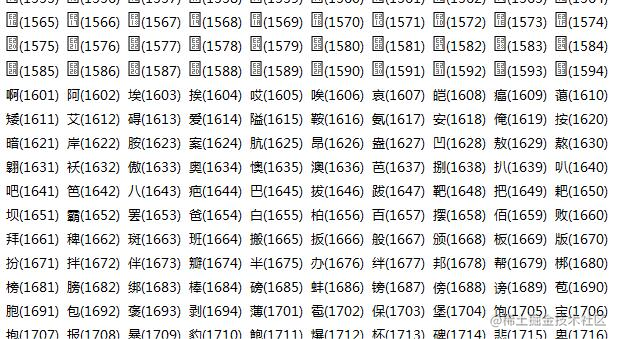
全角半角
区位码里有英文和数字,按道理说是不是也应该是双字节的呢。而一般情况下,我们见到的英文和数字是单字节的,以ASCII编码,也就是说现代的GBK编码是兼容ASCII编码的。
比如一个数字2,对应的二进制是0x32,(00110010),ASCII的2是半角的二
2(区位码:0318) 0xA3 0xB2。(10100011 10110010)这里的双字节2是全角的二,
同一个编码文件里,怎么区分ASCII和中文编码呢?从ASCII表我们知道标准ASCII只有128个字符,0~127即0x00~0x7F(0111 1111)。所以区分的方法就是,高字节的最高位为0则为ASCII,为1则为中文。
第三阶段(统一)
Unicode(统一码、万国码、单一码)是计算机科学领域里的一项业界标准,包括字符集、编码方案等。
Unicode 是为了解决传统的字符编码方案的局限而产生的
它为每种语言中的每个字符设定了统一并且唯一的二进制编码,以满足跨语言、跨平台进行文本转换、处理的要求。
1990年开始研发,1994年正式公布
知识点
字节序
字节序是指多字节数据在计算机内存中存储或者网络 传输时各字节的存储顺序。 字节序有两种,分别是“大端”(Big Endian, BE)和“ 小端”(Little Endian, LE)。
CPU处理多字节数的不同方式。例如“汉”字的Unicode编码是6C49。 大端 6C49 (将高序字节存储在起始地址) 小段 496C (将低序字节存储在起始地址)
Unicode标准建议用BOM(Byte Order Mark)来区分字节序,即在传输字节流前,先传输被作为BOM的字符“零宽无中断空格”。这个字符的编码是FEFF,而反过来的FFFE(UTF-16)和FFFE0000(UTF-32)在Unicode中都是未定义的码位,不应该出现在实际传输中。
BOM
UTF-8以字节为编码单元,没有字节序的问题。 UTF-16以两个字节为编码单元,在解释一个UTF-16文本前,首先要弄清楚每个编码单元的字节序。 例如收到一个“奎”的Unicode编码是594E,“乙”的Unicode编码是4E59。 如果我们收到UTF-16字节流“594E”,那么这是“奎”还是“乙”? Unicode规范中推荐的标记字节顺序的方法是BOM,即Byte Order Mark。

###UTF-8
UTF-8是UNICODE的一种变长度的编码表达方式,
UTF-8就是以8位为单元对UCS(Unicode Character Set)进行编码,而UTF-8不使用大尾序和小尾序的形式,每个使用UTF-8存储的字符,除了第一个字节外,其余字节的头两个比特都是以”10”开始,使文字处理器能够较快地找出每个字符的开始位置。

第一种:Unicode从 0x0000 到 0x007F 范围的,是不是有点熟悉?对,其实就是标准ASCII码里面的内容,所以直接去掉前面那个字节 0x00,使用其第二个字节(与ASCII码相同)作为其编码,即为单字节UTF8。
第二种:Unicode从 0x0080 到 0x07FF 范围的,转换成双字节UTF8。
第三种:Unicode从 0x8000 到 0xFFFF 范围的,转换成三字节UTF8,一般中文都是在这个范围里。
例如“博”字的Unicode编码是\u535a。0x535A在0x0800~0xFFFF之间,所以用3字节模板 1110yyyy 10yyyyxx 10xxxxxx。将535A写成二进制是:0101 0011 0101 1010,高八位分别代替y,低八位分别代替x,得到 11100101 10001101 10011010,也就是 0xE58D9A ,这就是博字的UTF8编码。
第四种:超过双字节的Unicode目前还没有广泛支持,仅见emoji表情在此范围。
base64编码
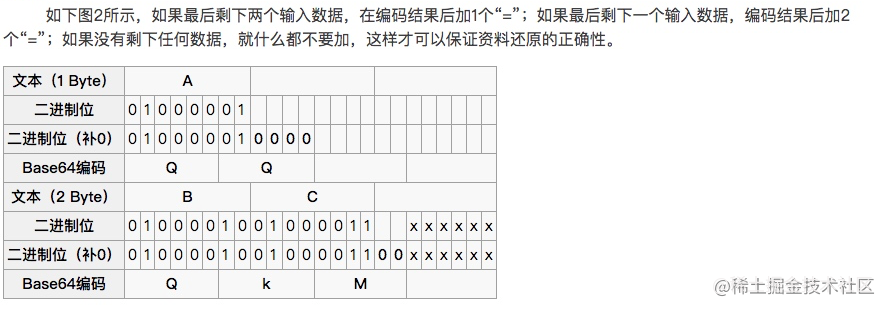
转换的时候,将三个byte的数据,先后放入一个24bit的缓冲区中,先来的byte占高位。数据不足3byte的话,于缓冲区中剩下的bit用0补足。然后,每次取出6(因为2^6=64)个bit,按照其值选择ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/中的字符作为编码后的输出。不断进行,直到全部输入数据转换完成。这么看来,跟URLEncode也很有相似之处啊。















 2430
2430











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









