







Topic 1:元学习
一、概念:learn to learn
区分少样本学习与元学习
少样本学习(Few-shot learning)是元学习的一个重要应用,它指的是机器能够在仅有少量样本的情况下,成功地学习和泛化到新任务上。在许多现实应用中,数据稀缺或新任务的出现意味着我们无法依赖大量的标注数据进行训练,这时候,元学习的能力就显得尤为重要。通过少样本学习,模型能够快速适应新任务,并且能够在极少的训练样本上做到较好的预测。
二、 常见训练方法
- 基于优化的元学习方法:
- 主要通过设计一种特殊的优化方法,使得模型能够在少量的样本上快速收敛。最著名的基于优化的元学习算法是Model-Agnostic Meta-Learning(MAML)。
- 基于记忆的元学习
- **Memory-Augmented Neural Networks(MANNs)**就是这样的一类模型。
- 基于度量学习的元学习
- 方法侧重于通过学习一个度量空间,使得在该空间内,类似的任务或样本距离更近,而不同的任务或样本距离更远。这样,模型可以通过比较新的任务与已学任务之间的距离来做出快速预测。
关于元学习,这里不做更深入的展开,详细可以参考这篇博文:
【机器学习】元学习(Meta-learning)-CSDN博客
Topic 2:Training
概念:本质上寻找一种函数
一、Training Detail
- Epoch(时期/回合):当一个完整的数据集通过了神经网络一次并且返回了一次,这个过程称为一次 epoch。也就是说,所有训练样本在神经网络中都进行了一次正向传播和一次反向传播。一个 epoch 是将所有训练样本训练一次的过程。
- Batch(批 / 一批样本):将整个训练样本分成若干个 batch。每个 batch 中包含一部分训练样本,每次送入网络中进行训练的是一个 batch。
- Batch size(批大小):每个 batch 中训练样本的数量。Batch size 的大小影响模型的优化程度和速度,以及内存的利用率和容量。
- Iteration(迭代):训练一个 batch 就是一次 iteration,每次迭代会更新模型的参数。
有多个 epoch 的原因是,单次训练数据集是不够的,需要反复多次才能拟合收敛。因为我们使用的是有限的数据集,并且我们使用一个迭代过程即梯度下降来优化学习过程。随着 epoch 数量增加,神经网络中的权重的更新次数也在增加,曲线从欠拟合变得过拟合。epoch 的个数是非常重要的,如果 epoch 太少,模型可能无法收敛到最优解;如果 epoch 太多,模型可能会过拟合,导致泛化能力下降。对于不同的数据集,合适的 epoch 数量是不同的,需要通过验证集或交叉验证来选择。
这些概念之间的关系可以用下面的公式表示:
- 一个 epoch 中,batch 总数 = 训练样本数 / batch_size;
- iteration总数 = batch总数 * epoch总数;
如果训练样本数不能被 batch_size 整除,那么有几种处理方法:
- 调整 batch_size,使其能够整除训练样本数。比如,如果训练样本数是1000,可以选择 batch_size 为50,20,10等。
- 调整训练样本数,使其能够被 batch_size 整除。比如,如果 batch_size 是35,可以选择训练样本数为700,1050,1400等。
- 检查输入数据的 batch_size,当它和预设的 batch_size 不匹配时强行补齐。比如,如果 batch_size 是35,最后一个 batch 只有25个样本,可以用零或其他值填充剩余的10个位置。
- 使用 drop_last 参数,舍弃最后一个不足 batch_size 的 batch。比如,如果 batch_size 是35,最后一个 batch 只有25个样本,可以直接忽略这个 batch,不参与训练。
具体例子如下所示,其中训练样本数为2922,batch_size = 16,epoch 总数为100。这意味着:
- 需要把训练样本分成182(2922/16)个 batch,每个 batch 包含16个样本。
- 每次训练一个 batch,就是一次 iteration。
- 每次训练完所有的 batch,就是一次 epoch。
- 需要训练100个 epoch,也就是18200个 iteration。
- 每次 iteration,模型的参数都会更新一次。
一些理解和比喻:
- learing rate 可以从大到小,类似于一个人爬山,在山底的时候可以步长大一些的往山顶走;如果离山顶越来越近之后就把步长调整的小一些,过大的步长可能会越过山顶。一般学习率设置在0.001甚至0.0001
- Training epochs 的具体数量可以使用验证集进行判断,若已经收敛即可停止训练。训练轮次过多可能出现已经收敛的情况,那么继续训练就是浪费时间;还可能出现过拟合的状态,使得模型在训练集上表现良好但是在验证集和测试集上表现效果差。
二、Curriculum Learning 课程学习
课程学习(CL)是一种从简单的数据向困难的数据训练机器学习模型的训练策略。
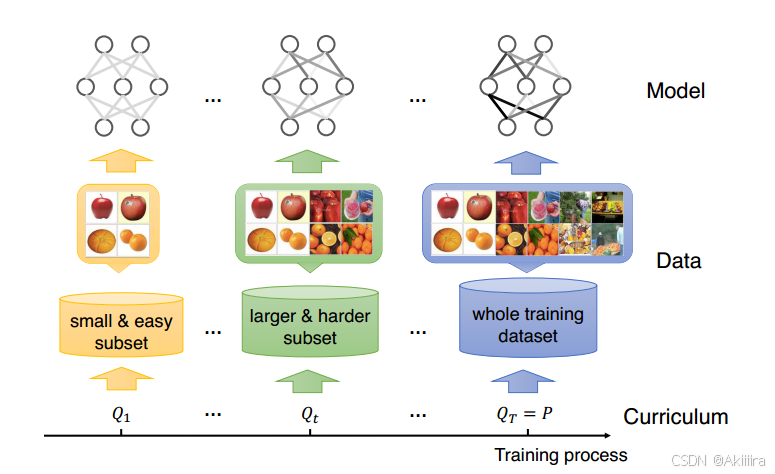
随着训练的进行,CL逐渐将更难的样例引入子集,最终在整个训练数据集上训练模型。与在整个训练数据集上直接训练相比,这种CL策略可以提高模型性能和收敛速度。例如,苹果和橙子的图像是清晰、典型且易于识别的。随着模型训练的进展,CL在当前子集中添加了更多“更难”的图像(即更难识别),这类似于人类课程中学习材料的难度增加。
解决什么问题?
传统模型所有的训练样例都是随机呈现给模型的,忽略了数据样本的各种复杂性和当前模型的学习状态。
更深的知识点参考这一篇论文:
课程学习 Curriculum Learning-CSDN博客
三、Transfer Learning 迁移学习
迁移学习(Transfer Learning)是一种机器学习方法,就是把为任务 A 开发的模型作为初始点,重新使用在为任务 B 开发模型的过程中。
为什么需要迁移学习?
- 大数据与少标注的矛盾:虽然有大量的数据,但往往都是没有标注的,无法训练机器学习模型。人工进行数据标定太耗时。
- 大数据与弱计算的矛盾:普通人无法拥有庞大的数据量与计算资源。因此需要借助于模型的迁移。
- 普适化模型与个性化需求的矛盾:即使是在同一个任务上,一个模型也往往难以满足每个人的个性化需求,比如特定的隐私设置。这就需要在不同人之间做模型的适配。
- 特定应用(如冷启动)的需求。
具体参考如下:
迁移学习(Transfer)-CSDN博客
【机器学习】机器学习重要方法——迁移学习:理论、方法与实践_迁移学习方法-CSDN博客
深度学习之---迁移学习-CSDN博客
关于迁移学习的一些个人理解:
实际上,从DL-FWI的角度来讲,传统图像处理方式在一定程度上都可以迁移到对地震波图和速度模型的处理中。
- 从数据驱动的角度:最为简单粗暴的方式就是直接更换数据集。当然这样的方法效果并不一定好,因为源域和目标域之间的差距是不能够忽视的,需要针对性的做出改变才能更加出色的完成任务。
- 从网络结构的角度:实际上,例如边界检测,图像融合等方法,在传统CV领域已经十分发达。其中有很多处理方式是可以供我们举一反三的。
域适应
在迁移学习中, 当源域和目标的数据分布不同 ,但两个任务相同时,这种特殊的迁移学习叫做域适应 (Domain Adaptation,DA )。
历史背景:传统上,机器学习模型主要在特定数据集上训练和测试。当模型应用于数据分布不同的新领域时,会出现性能下降的域偏移问题。为了解决这一问题,域适应技术应运而生,目的是让在源域训练的模型能够适应目标域,即使两者的数据分布存在显著差异。
当前进展:近年来,域适应技术取得了显著进展,提出了多种方法,如特征空间转换、对抗性训练和自监督学习等。这些技术有效减少了源域和目标域之间的差异,提升了模型在目标域的性能。域适应技术现已广泛应用于图像识别、自然语言处理和语音识别等多个领域。
其中常用的技术有主动域适应ADA、无监督域适应UDA、无源域适应SFDA。
具体的实现方法可以学习以下博文:
域适应(domain adaptation)-CSDN博客
详解域适应-CSDN博客
Topic 3:Observation system 地震观测系统
这一部分相关理论更偏向传统地震勘探,在以往的学习中已经有初步认识,这里做一个简单总结:
【学习笔记】Day 10_地震观测系统图-CSDN博客
震源:产生地震波的源头,通常采用炸药震源、可控震源等。通常称为炮点。
接收系统:由多个地震检波器组成,用于接收地震波传播到地面或地下不同位置的信号。
常见的观测系统分类如下:
1. 正常的陆地观测系统
通常来说一个炮点会在其两侧分布均匀的检波器,当炮点产生地震波之后,激发器位置会首先接收到信号,之后是两侧的检波器。距离激发器越远的检波器接收信号越晚。
2. OpenFWI的观测系统
这种观测系统与正常的陆地观测系统的区别就是它不再以滑动窗口的方式进行数据的收集,而是具备多个不同的炮点,但检测点却是固定不变的。每一次激发器产生地震波时,检波器都会进行接收信号。
3. 海上观测系统
需要注意的是,扎实的地震勘探原理知识是有助于开展相关实验的,所以力所能及的情况下,主动进一步的去学习《地震勘探原理》是一个不错的选择


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









