






1、域适应的背景
历史背景:传统上,机器学习模型主要在特定数据集上训练和测试。当模型应用于数据分布不同的新领域时,会出现性能下降的域偏移问题。为了解决这一问题,域适应技术应运而生,目的是让在源域训练的模型能够适应目标域,即使两者的数据分布存在显著差异。
当前进展:近年来,域适应技术取得了显著进展,提出了多种方法,如特征空间转换、对抗性训练和自监督学习等。这些技术有效减少了源域和目标域之间的差异,提升了模型在目标域的性能。域适应技术现已广泛应用于图像识别、自然语言处理和语音识别等多个领域。
其中常用的技术有主动域适应ADA、无监督域适应UDA、无源域适应SFDA。
2、主动域适应(Active Domain Adaptation,ADA)
2.1、目标
在有限的标注预算下,最大化域自适应模型的泛化能力。关键在于如何选择对模型最有帮助的目标样本进行标注。
2.2、方法分类
ADA方法可分为基于样本选择标准的策略和基于聚类的策略。前者侧重于样本的不确定性和代表性,后者则利用聚类算法确定类的质心。
2.3、主动域适应的步骤
- 初始模型训练:首先在源域(source domain)上训练一个初始模型。
- 选择目标样本:模型需要查询并标注一些目标域(target domain)的样本。这些样本的选择通常基于一定的策略,比如选择模型预测结果不确定性和代表性高的样本,或者是进行聚类之后选择类的质心以及质心附近的样本。
- 标注目标样本:对于选定的目标样本,需要人工或者自动的方式进行标注。标注的结果将用于更新模型,帮助模型更好地适应目标域。
- 模型更新:使用标注过的目标样本对模型进行微调(fine-tuning),使模型在目标域上的性能得到提升。
- 迭代优化:重复步骤2到步骤4,直到达到预设的迭代次数或者模型在目标域上的性能达到预设的阈值。
2.4、主动预适应主要算法
2.4.1、重加权算法
重加权算法是一种在机器学习和数据处理领域中用于处理领域适应问题的技术。其核心思想是在源领域(source domain)和目标领域(target domain)之间,通过重新加权源领域的数据,来使源领域和目标领域的分布更加接近,从而提高在目标领域上的模型性能。
主动域适应重加权算法的工作原理是通过重新加权源领域的数据,然后在重新加权的源数据上训练模型,以最小化源领域和目标领域之间的分布差异。这可以通过多种方法实现,例如通过对抗性训练、核均值匹配等技术来训练特征提取器,使源领域和目标领域的特征分布更加接近。
在主动域适应重加权算法中,权重的调整是关键步骤。权重的确定通常基于源领域和目标领域之间的某种度量,例如数据分布的差异、特征的重要性等。通过调整权重,可以使源领域的数据更加符合目标领域的特点,从而提高在目标领域上的模型表现。
# 定义一个简单的加权函数
def apply_weights(scores, weights):
# 确保评分和权重的长度相同
assert len(scores) == len(weights), "Scores and weights must have the same length."
# 使用列表推导式来计算加权得分
weighted_scores = [score * weight for score, weight in zip(scores, weights)]
# 返回加权得分列表
return weighted_scores
# 示例数据:基础评分和权重
base_scores = [85, 90, 78, 88, 92]
weights = [0.8, 1.0, 1.2, 0.9, 1.1]
# 应用加权算法
weighted_scores = apply_weights(base_scores, weights)
# 打印结果
for i, (score, weight, weighted_score) in enumerate(zip(base_scores, weights, weighted_scores)):
print(f"Item {i + 1}: Base Score = {score}, Weight = {weight}, Weighted Score = {weighted_score}")
# 也可以计算加权得分的总和
total_weighted_score = sum(weighted_scores)
print(f"Total Weighted Score: {total_weighted_score}")2.4.2、聚类K-Means算法
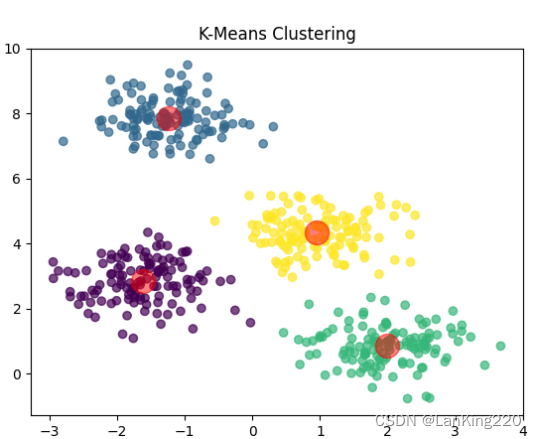
在主动域适应聚类K-Means算法中,主要目标是解决源领域和目标领域之间数据分布的差异问题。由于源领域和目标领域的数据可能来自不同的分布,直接应用K-Means算法可能会导致在目标领域上聚类效果不佳。因此,主动域适应聚类K-Means算法通过结合主动学习和K-Means聚类算法的思想,来优化目标领域的聚类结果。
主动域适应聚类K-Means算法会首先使用源领域的数据进行初始的K-Means聚类,得到初始的簇中心和聚类结果。然后,算法会利用主动学习的方法,从目标领域中选择一些具有代表性的样本,并获取这些样本的真实标签或专家标注。这些查询样本的选择通常基于一定的策略,如不确定性采样、多样性采样等,以确保所选样本能够覆盖目标领域数据的重要特征。
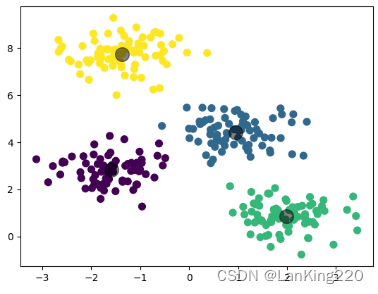
from sklearn.cluster import KMeans
from sklearn.datasets import make_blobs
import matplotlib.pyplot as plt
# 生成模拟数据
X, y = make_blobs(n_samples=300, centers=4, cluster_std=0.60, random_state=0)
# 定义KMeans模型
kmeans = KMeans(n_clusters=4)
# 对数据进行聚类
kmeans.fit(X)
# 预测数据所属类别
labels = kmeans.predict(X)
# 绘制结果
plt.scatter(X[:, 0], X[:, 1], c=labels, s=50, cmap='viridis')
# 绘制聚类中心
centers = kmeans.cluster_centers_
plt.scatter(centers[:, 0], centers[:, 1], c='black', s=200, alpha=0.5);
plt.show()3、无监督域适应(Unsupervised_Domain_Adaptation,UDA)
3.1、目的
无监督域适应(UDA)旨在提高模型在目标域的性能,特别是在目标域数据难以标注或标注成本高的情况下。它通过减少源域和目标域之间的数据分布差异,增强模型的泛化能力,降低标注成本,并使模型能够适应动态变化的环境。此外,UDA有助于提升模型鲁棒性,保护数据隐私,并推动机器学习领域的发展。
3.2、方法分类
UDA方法可分为显式对齐和隐式对齐。显式对齐通过度量或相似度计算指导对齐过程,如子空间对齐和MMD。隐式对齐通过模型结构或训练过程实现,如域混淆损失和对抗性域适应。
3.3、无监督域适应的步骤
- 数据准备:收集源领域和目标领域的数据集。源领域的数据集通常包含有标签的数据,而目标领域的数据集则没有标签。
- 特征提取:训练一个共享的特征提取器(如卷积神经网络CNN),用于从源领域和目标领域的数据中提取特征。
- 特征对齐:在特征空间上,对源领域和目标领域的特征进行对齐,以减小它们之间的差异。这可以通过各种方法实现,如特征转换(如使用PCA或自动编码器将特征转换到同一空间)或特征选择(选择对目标域最相关的特征)。
- 领域适应:在目标领域上进行领域适应,使模型能够适应目标领域的数据分布。这可以通过最小化源领域和目标领域特征分布之间的差异来实现,例如使用最大均值差异(MMD)等方法。
- 模型微调:使用无标签的目标领域数据对模型进行微调,进一步提高模型在目标领域上的性能。这通常涉及到在目标领域数据上迭代训练模型,并监控模型在验证集上的性能。
- 测试与评估:在目标领域的数据集上测试模型的性能,并根据评估结果进行调整和优化。
无监督域适应的具体步骤可能因应用场景、数据特点和模型需求的不同而有所差异。此外,随着技术的不断发展,新的方法和技术也不断涌现,为无监督域适应提供了更多的可能性。
3.4、显式对齐方法和隐式对齐方法的实现
3.4.1、显式对齐方法(Explicit Alignment Methods)的实现
显式对齐方法明确地通过某种方式将源领域和目标领域的特征或表示进行对齐。这些方法通常依赖于某种形式的度量或相似度计算来指导对齐过程。
- 子空间对齐(Subspace Alignment, SA):子空间对齐是一种将源领域和目标领域的子空间进行显式对齐的方法。它通过变换源领域的子空间以匹配目标领域的子空间,从而减小领域间的差异。
- 基于最大均值差异(Maximum Mean Discrepancy, MMD):MMD是一种度量两个分布之间差异的指标。在无监督预适应中,可以使用MMD作为损失函数来训练一个模型,使得源领域和目标领域的特征分布在MMD度量下尽可能接近。
- 基于伪标签的方法:尽管这种方法本身可能不完全是无监督的(因为它涉及到伪标签的生成),但在某些情况下,可以通过在源领域上训练一个模型来生成目标领域的伪标签,并使用这些伪标签来指导源领域和目标领域的对齐。
3.4.2、隐式对齐方法(Implicit Alignment Methods)的实现
隐式对齐方法不直接计算或优化源领域和目标领域之间的对齐,而是通过训练一个模型来隐式地减小领域间的差异。这些方法通常依赖于模型的结构或训练过程来实现领域对齐。
- 域混淆损失(Domain Confusion Loss):在训练一个领域适应模型时,可以添加一个额外的损失项来鼓励模型无法区分输入数据来自源领域还是目标领域。这可以通过在模型的某个中间层上添加一个领域分类器,并训练模型以最小化该分类器的准确性来实现。
- 对抗性域适应(Adversarial Domain Adaptation):这种方法使用生成对抗网络(GAN)的思想,在模型中添加一个域判别器(Domain Discriminator),同时训练一个特征提取器来混淆域判别器。通过这种方式,特征提取器被训练成产生无法区分领域的特征表示,从而实现领域对齐。
- 自编码器(Autoencoders):自编码器可以通过学习数据的压缩表示来隐式地实现领域对齐。在训练过程中,自编码器被训练成在重构输入数据时保留重要信息,同时去除与领域相关的噪声。通过这种方式,自编码器学习到的表示可能更适用于跨领域的任务。
需要注意的是,显式对齐方法和隐式对齐方法并不是完全独立的,它们可以相互结合使用以提高领域适应的效果。
4、无源域适应(Source-free Domain Adaptation,FSDA)
4.1、目的
SFDA旨在仅依靠源域模型实现域自适应。由于只有源域模型可用SFDA通常倾向于探索模型中包含的信息。它主要针对隐私保护、数据敏感性(比如医院的医疗数据)限制或成本效益考量,通过利用目标域的无标签数据和预训练模型来实现。SFDA的关键优势在于保护隐私、降低成本、适应性强,并推动了无监督学习和迁移学习技术的发展,增强了模型在新领域的泛化能力。
4.2、无源域适应的步骤
- 获取预训练模型:在有标签的源域数据上进行预训练,得到一个预训练好的模型。由于是无源域适应,因此在后续过程中将无法直接访问源域数据。
- 初始化目标域模型:使用预训练好的源域模型作为起点,初始化目标域模型。这通常意味着目标域模型将继承源域模型的部分或全部参数。
- 特征提取与重构:利用目标域的无标签数据,通过目标域模型进行特征提取。由于无法直接访问源域数据,因此需要利用目标域数据来重构或模拟源域数据的特征空间。
- 无监督领域适应:在没有源域数据的情况下,利用目标域的无标签数据进行无监督领域适应。这通常涉及到最小化源域和目标域特征分布之间的差异,以减小领域偏移。
- 可靠性评估与过滤(可选):为了进一步提高模型的性能,可以对目标域数据进行可靠性评估,并过滤出可靠的样本进行训练。这通常基于某些度量(如自熵的阈值、Hausdorff距离等)来判断样本的可靠性。
- 模型训练与迭代:使用目标域数据(包括可靠的样本)对目标域模型进行训练。在训练过程中,可以根据模型的性能进行迭代和优化,以进一步提高模型的泛化能力。
- 模型评估:在目标域测试集上对训练好的模型进行评估,以验证其性能。如果性能不满足要求,可以返回步骤4进行更多的无监督领域适应迭代。
4.3、特征混合方法
- 特征空间插值(Feature Space Interpolation):在SFDA中,由于无法直接访问源域数据,特征空间插值可以通过对目标域数据的特征表示进行插值来模拟源域数据的特征分布。这种方法的基本思想是在特征空间中选取两个或多个目标域样本的特征表示,然后按照某种方式进行组合或混合,以生成新的特征表示。特征空间插值的一个关键优势是它可以生成大量的新特征表示,从而增加模型的泛化能力。然而,插值方法的选择和插值参数的设置可能会影响到最终的性能。
- 特征融合(Feature Fusion):在SFDA中,特征融合可以用于将多个目标域模型或源域模型的特征表示进行融合,以创建一个更加全面和鲁棒的特征表示。这种融合可以通过简单的拼接、加权求和、或更复杂的融合方法(如注意力机制)来实现。特征融合的一个主要优势是它可以整合来自不同模型或不同来源的特征信息,从而提高模型的适应性和性能。此外,通过精心设计的融合策略,还可以减轻过拟合和提高泛化能力。
5、域适应的重要性:
域适应在机器学习和深度学习的应用中具有重要性,主要体现在以下几个方面:
- 提升泛化能力:在现实世界中,模型往往需要面对各种新的、未知的环境或领域。这些新环境可能与模型训练时使用的环境存在显著差异,导致模型的性能急剧下降。域适应通过允许模型选择性地标注和学习新领域的数据,可以帮助模型学习更加泛化的特征表示,从而提升模型在新环境或领域中的性能。
- 减少标注成本:在机器学习中,数据的标注通常需要大量的人力、物力和时间。特别是在新领域中,由于缺乏标注数据,模型的性能往往受到限制。域适应通过选择性地标注那些对模型性能提升帮助最大的样本,可以显著降低标注成本,同时保持模型在新领域中的性能。
- 适应动态环境:在许多实际应用中,环境或领域可能会随着时间或空间的改变而发生变化。例如,在自动驾驶中,车辆需要适应不同的天气、路况和交通规则。域适应允许模型在运行时动态地选择并学习新领域的数据,从而适应这些变化,尽可能的保持模型的性能。

- 增强模型鲁棒性:由于域适应关注于提升模型在新领域中的性能,因此它也可以帮助模型增强鲁棒性。通过学习和适应不同的领域,模型可以更加稳健地应对各种输入和数据分布的变化,从而提高整体的性能稳定性。
- 推动领域发展:域适应作为一种新兴的机器学习方法,对于推动机器学习领域的发展具有重要意义。通过研究和实践主动域适应技术,可以推动相关领域如迁移学习、无监督学习、强化学习等的发展,进一步拓展机器学习的应用范围和能力。
6、对论文的解读
6.1、论文以其代码地址
论文题目:Active Domain Adaptation via Clustering Uncertainty-weighted Embeddings
论文地址:https://ieeexplore.ieee.org/stamp/stamp.jsp?tp=&arnumber=9710350
6.2、论文的引出
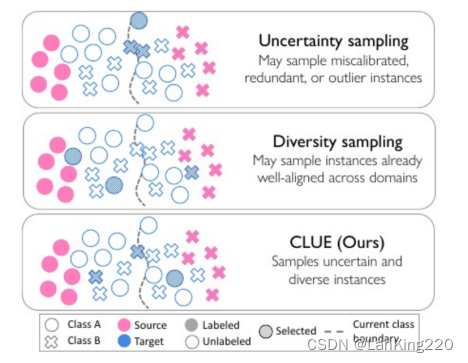
基于多样性采样的并行工作在学习的嵌入空间中选择彼此不相似的实例。在主动DA中,这可能导致从已经跨域对齐的特征空间区域中采样无信息实例。因此,仅使用不确定性或多样性采样对于主动DA是次优的。
从而该篇论文提出了一种新的主动数据分析标签获取策略,该策略以原则性的方式结合了不确定性和多样性采样,而不需要复杂的梯度或基于域鉴别器的多样性度量。从特征空间的密集区域识别信息和代表性的目标实例,对目标实例的深度嵌入进行聚类,这些嵌入由目标模型的相应不确定性加权。加权方案有效地增加了与实例的不确定性成比例的密度。为了构建非几余批次,CLUE然后选择离推断的聚类质心最近的邻居进行标记。算法利用获得的目标标签和可选的已标记源和未标记目标数据来更新模型,始终导致比竞争(且往往更复杂)的替代方案更具有成本效益的域对齐。
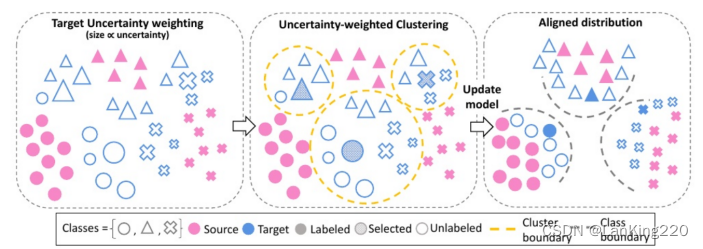
聚类不确定加权嵌入CLUE,这是一种用于主动DA的新型标签获取策略,它可以识别"组具有信息量和代表性的不同目标实例。首先,基于模型熵对目标实例的深度嵌入进行重新加权,以强调特征空间的不确定区域(左)。接下来,为了选择多样化的实例,对这些不确定性加权的嵌入进行聚类,并获取最接近每个簇质心的实例进行标记(中间)。最后,使用获得的目标标签(以及可选的,标记的源和未标记的目标数据)来更新模型,从而得到分类良好的目标数据(右)。
6.3、不确定加权的嵌入
6.3.1、核心思想
不确定性与多样性的结合:选择那些在模型预测下不确定性高且在特征空间中分布多样化的实例。
加权聚类:在聚类过程中考虑实例的不确定性,以更有效地识别信息量大的目标实例。
6.3.2、实现过程
计算预测熵:为测量信息而引入了预测熵H(Y|x;Θ)(H(Y|x) for brevity),对于c路分类,其定义为
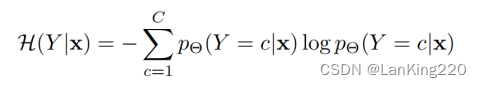
其中Y是类别标签,x是实例,Θ是模型参数。
在域移位下,熵被视为同时捕获不确定性和域性。与其训练一个显式域判别器,不如考虑一个基于熵阈值化的隐式域分类器d(x)。
隐式域分类器:基于预测熵构建一个隐式域分类器d(x),用于区分实例是否属于目标域。
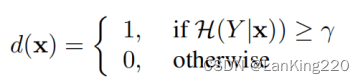
其中,1和0表示目标域标签和源域标签,γ为阈值。因此,一个属于目标域的实例的概率为:
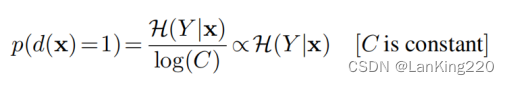
加权聚类:为了共同捕获多样性和不确定性,提出了基于样本的不确定性(由等式给出1),并计算加权总体方差。
数据集的总体划分目标是:
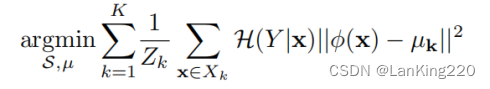
其中归一化因子:Zk = ∑x∈Xk H(Y|x)。加权集合划分也可以看作是标准在交替特征空间中的集合划分,通过加权K均值算法对目标实例的特征嵌入进行聚类,其中权重是实例的预测熵。这有助于从特征空间中的不确定区域选择代表性实例。
权衡不确定性和多样性。CLUE捕获了模型不确定性(通过熵加权)和特征空间覆盖(通过聚类)之间的隐式权衡。考虑例如x的预测概率分布。
选择代表性实例:在每个聚类中,选择与聚类中心最近的实例进行标注,以确保所选实例的多样性。
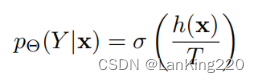
其中σ表示softmax函数,T表示其温度。我们观察到,通过调制T,可以控制不确定性多样性的权衡。
通过对T的调参可以实现对softmax分布的扩散度的调整。T越大扩散度越高,多样性发挥更大的作用。
6.4、结论
CLUE方法通过结合不确定性和多样性采样,提供了一种在域偏移情况下进行有效主动学习的新策略。这种方法特别适用于目标域标注资源有限的情况,能够最大化每一轮主动学习的信息量,从而提高模型在目标域上的性能
7、总结
本文档详细介绍了域适应的背景、技术、以及在机器学习中的重要性。特别地,文档深入探讨了主动域适应(Active Domain Adaptation, ADA)的策略和算法,包括重加权算法和聚类K-Means算法,并提供了相应的Python代码示例。此外,文档还涉及了无监督域适应(Unsupervised Domain Adaptation, UDA)和无源域适应(Source-free Domain Adaptation, SFDA),讨论了它们的步骤、方法和重要性。 最重要的是,文档对论文《Active Domain Adaptation via Clustering Uncertainty-weighted Embeddings》进行了解读,阐释了CLUE(Clustering Uncertainty-weighted Embeddings)方法的核心思想和实现过程。CLUE方法通过结合不确定性和多样性采样,为域适应问题提供了一种新的视角和解决方案,特别适用于目标域标注资源受限的情况。
8、展望
域适应技术仍然在不断发展中,未来的研究方向可能包括:
- 算法优化:进一步提升域适应算法的性能和适用性,以适应更广泛的应用场景。
- 理论深化:深入研究域适应的理论基础,探索域偏移和领域对齐的深层次机制。
- 跨域泛化:研究模型在多个领域间的泛化能力,而不仅是单一对迁移。
- 标注效率:开发更高效的标注方法,减少域适应过程中的成本和时间。
- 隐私保护:设计隐私保护的域适应方法,确保数据安全和隐私。
- 多任务学习:将域适应应用于多任务学习,提升模型在多个任务上的性能。
- 强化学习结合:利用强化学习使模型在动态环境中自我适应和学习。
- 实际应用推广:将域适应技术应用于现实世界问题,如医疗、自动驾驶等。
- 开源工具开发:创建易于使用的开源工具和平台,促进域适应技术的普及和应用。
- 鲁棒性与安全性:提高域适应模型的鲁棒性和安全性,抵御潜在的攻击和风险。准确衡量域适应技术在不同场景下的效果。
通过这些研究方向,域适应技术有望在未来取得更大的进展,并在更多的应用场景中发挥重要作用。















 4194
4194

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









