







Lucene+hibernate 开发:
这里主要是巩固写代码。没有新增技术知识, luncene跟数据库结合是我们开发中常用的。但实际上,都是一样的。 本篇主要使用的是 lucene+hibernate 编写代码;其他的操作数据库,都一样的。 数据库储存内容:
只要能实现场景需求一,那么这个也很简单
数据库储存内容:

需求:找出哪个东西,属性中有“容量”的词语,
分析:就是通过“容量”搜索出对应的数据库中的记录
1:导包:
Lucene的jar:
Hibernate的jar:(required)
数据库jar:
分词器 jar:
2:2:hibernate 配置文件:
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE hibernate-configuration PUBLIC
"-//Hibernate/Hibernate Configuration DTD 3.0//EN"
"http://www.hibernate.org/dtd/hibernate-configuration-3.0.dtd">
<hibernate-configuration>
<session-factory>
<property name="hibernate.connection.driver_class">com.mysql.jdbc.Driver</property>
<property name="hibernate.connection.url">jdbc:mysql:///crm</property>
<property name="hibernate.connection.username">root</property>
<property name="hibernate.connection.password">root</property>
<property name="hibernate.dialect">org.hibernate.dialect.MySQLDialect</property>
<property name="hibernate.show_sql">true</property>
<property name="hibernate.format_sql">true</property>
<property name="hibernate.hbm2ddl.auto">update</property>
<property
<mapping resource="cn/items.xml" />
</session-factory>
</hibernate-configuration>3:实体类和映射文件:
//省略了getter setter方法
public class Items {
private Integer id;
private String name;
private Float price;
private String pic;
private Date createtime;
private String detail;<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE hibernate-mapping PUBLIC
"-//Hibernate/Hibernate Mapping DTD 3.0//EN"
"http://www.hibernate.org/dtd/hibernate-mapping-3.0.dtd">
<hibernate-mapping package="cn" >
<class name="Items" table="items" >
<id name="id" >
<generator class="native">
</generator>
</id>
<property name="name" ></property>
<property name="price" ></property>
<property name="pic" ></property>
<property name="createtime" ></property>
<property name="detail" ></property>
</class>
</hibernate-mapping>4:代码:
public class luceneTest {
private static SessionFactory sessionFactory;
//加载配置文件
static{
sessionFactory = new Configuration().configure("hibernate.cfg.xml").buildSessionFactory();
}
//获取原始数据
public List<Items> getItems(){
Session session = sessionFactory.openSession();
Query query = session.createQuery("FROM cn.Items ");
List<Items> list = query.list();
return list;
}
//测试hibernate
@Test
public void test(){
List<Items> items = getItems();
System.out.println(items);
}
//获取indexwriter对象
public IndexWriter getIndexwriter() throws IOException{
Directory directory = FSDirectory.open(new File("G:\\a\\v"));
//获取分词器
Analyzer analyzer = new IKAnalyzer();
//获取indexwriterconfig对象
IndexWriterConfig indexWriterConfig = new IndexWriterConfig(Version.LUCENE_4_10_3, analyzer);
return new IndexWriter(directory,indexWriterConfig);
}
@Test
public void creatIndex() throws IOException{
IndexWriter indexwriter = getIndexwriter();
List<Items>items = getItems();
for (Items item : items) {
Document document = new Document();
String name = item.getName();
Date createtime = item.getCreatetime();
String detail = item.getDetail();
Float price = item.getPrice();
Field Itemname = new TextField("name",name,Store.YES);
Field Itemcreatetime = new TextField("createtime",String.valueOf(createtime),Store.YES);
Field Itemdetail = new TextField("detail",String.valueOf(detail),Store.YES);
Field Itemprice = new TextField("price",String.valueOf(price),Store.YES);
document.add(Itemname);
document.add(Itemcreatetime);
document.add(Itemdetail);
document.add(Itemprice);
indexwriter.addDocument(document);
}
indexwriter.close();
}
@Test
public void search() throws IOException{
//获得directory对象
FSDirectory directory = FSDirectory.open(new File("G:\\a\\v"));
//获得indexreader对象
IndexReader reader =DirectoryReader.open(directory);
//获得查询对象
IndexSearcher indexSearcher = new IndexSearcher(reader);
//获取要查询的语汇单元
Term term = new Term("detail","容量");
TermQuery query = new TermQuery(term);
//进行查询
TopDocs topDocs = indexSearcher.search(query, 2);
// 取得结果集
ScoreDoc[] scoreDocs = topDocs.scoreDocs;
for (ScoreDoc scoreDoc : scoreDocs) {
// 根据文档对象ID取得文档对象
Document document = indexSearcher.doc(scoreDoc.doc);
System.out.println();
IndexableField field = document.getField("name");
String stringValue = field.stringValue();
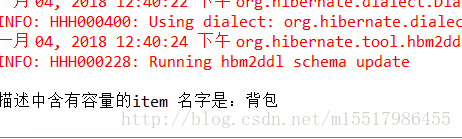
System.out.println("描述中含有容量的item 名字是:"+stringValue);
}
}
}//=========================================================================
依次执行 :创建索引方法,和查询方法:
运行结果:
注:我这里使用的是在静态代码块获取的session的工厂,使用的是opensession方法,这样每次都是新的session,如果大家使用session过多,要使用getcurrentSsssion方法,可以自己写一个获取session的工具类,
使用单例的设计模式,与线程绑定,或者在配置文件中配置,session与本地线程绑定name="hibernate.cureent_session_context_class">Thread</property>来实现获取当前session
简单的luncene与数据库结合,就实现了。其他的索引增删改查就就跟前面一样了。













 2541
2541











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









