







facet搜索,方面搜索,电商中使用的非常多.例如

统计field中值的分组分布情况, 只是每个域值中的命中数量.
facet搜索主要用于:
1.Facet Counting facet域值统计
2.Facet Associations facet域值分类匹配度.描述一个doc属于某一个category的程度.
3.Multiple Facet Requests 了解多个fecet的结果分布情况
4.Facet Labels at Search Time 请求数据category,facet标签搜索.
用DirectoryTaxonomyWriter对索引封装
IndexWriter indexWriter = new IndexWriter(indexDir, new IndexWriterConfig(Version.LUCENE_4_10_0,
new WhitespaceAnalyzer()));
// Writes facet ords to a separate directory from the main index
DirectoryTaxonomyWriter taxoWriter = new DirectoryTaxonomyWriter(taxoDir);
facet实现原理
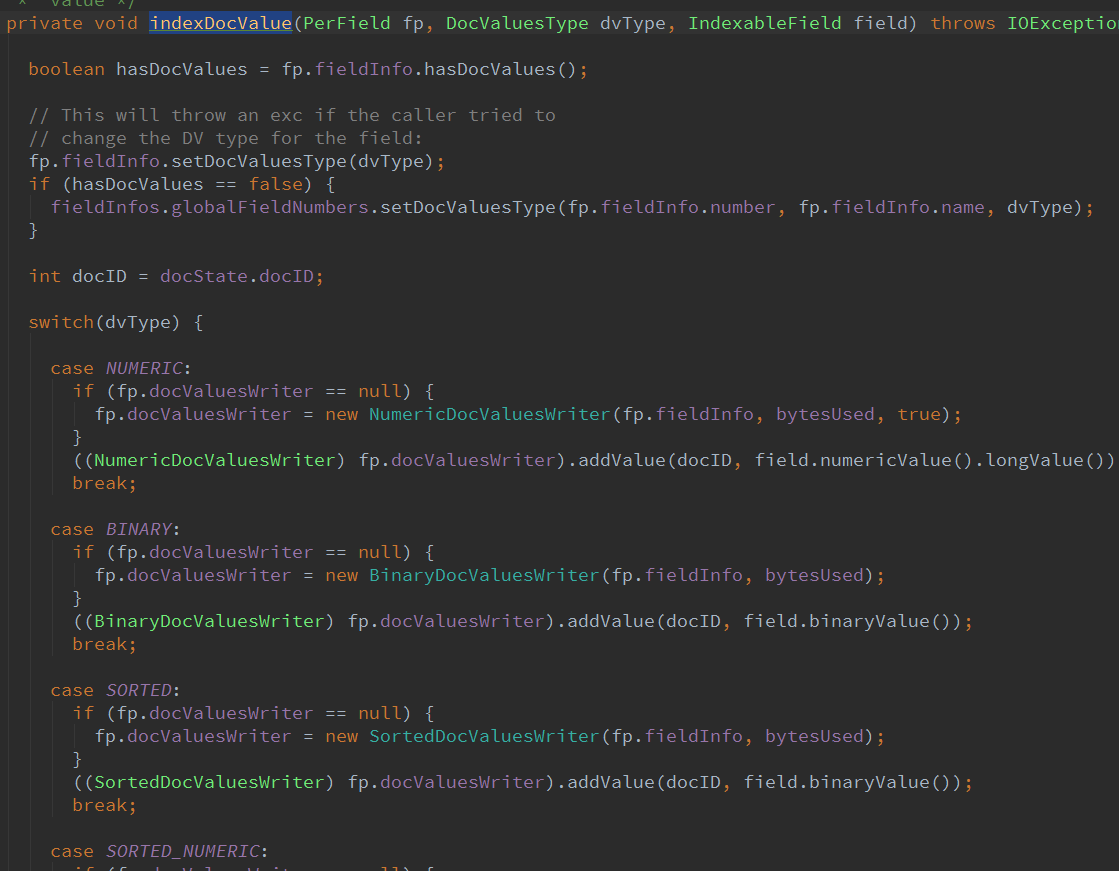
facet数据底层实现是利用DocValues中的SortedSetDocValuesFacetField, 当doc的某些field需要切面搜索的时候,lucene建索引的过程中建立docid->field tokens的正向映射.
index:
IndexWriter writer = ...
TaxonomyWriter taxo = new DirectoryTaxonomyWriter(taxoDir, OpenMode.CREATE);
...
Document doc = new Document();
doc.add(new Field("title", titleText, Store.YES, Index.ANALYZED));
...
List<CategoryPath> categories = new ArrayList<CategoryPath>();
categories.add(new CategoryPath("author", "Mark Twain"));
categories.add(new CategoryPath("year", "2010"));
...
DocumentBuilder categoryDocBuilder = new CategoryDocumentBuilder(taxo);
categoryDocBuilder.setCategoryPaths(categories);
categoryDocBuilder.build(doc);
writer.addDocument(doc);addDocument到updateDocument之后 lucene底层实现数据的存储.利用**DocValuesWriter写入disk中
facet搜索demo
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
import org.apache.lucene.analysis.core.WhitespaceAnalyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.facet.DrillDownQuery;
import org.apache.lucene.facet.DrillSideways;
import org.apache.lucene.facet.DrillSideways.DrillSidewaysResult;
import org.apache.lucene.facet.FacetField;
import org.apache.lucene.facet.FacetResult;
import org.apache.lucene.facet.Facets;
import org.apache.lucene.facet.FacetsCollector;
import org.apache.lucene.facet.FacetsConfig;
import org.apache.lucene.facet.taxonomy.FastTaxonomyFacetCounts;
import org.apache.lucene.facet.taxonomy.TaxonomyReader;
import org.apache.lucene.facet.taxonomy.directory.DirectoryTaxonomyReader;
import org.apache.lucene.facet.taxonomy.directory.DirectoryTaxonomyWriter;
import org.apache.lucene.index.DirectoryReader;
import org.apache.lucene.index.IndexWriter;
import org.apache.lucene.index.IndexWriterConfig;
import org.apache.lucene.search.IndexSearcher;
import org.apache.lucene.search.MatchAllDocsQuery;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.RAMDirectory;
import org.apache.lucene.util.Version;
/** Shows simple usage of faceted indexing and search. */
public class FacetDemo {
private final Directory indexDir = new RAMDirectory();
private final Directory taxoDir = new RAMDirectory();
private final FacetsConfig config = new FacetsConfig();
/** Empty constructor */
public FacetDemo() {
config.setHierarchical("Publish Date", true);
}
/** Build the example index. */
private void index() throws IOException {
IndexWriter indexWriter = new IndexWriter(indexDir, new IndexWriterConfig(Version.LUCENE_48, new WhitespaceAnalyzer(
Version.LUCENE_48)));
// Writes facet ords to a separate directory from the main index
DirectoryTaxonomyWriter taxoWriter = new DirectoryTaxonomyWriter(taxoDir);
Document doc = new Document();
doc.add(new FacetField("Author", "Bob"));
doc.add(new FacetField("Publish Date", "2010", "10", "15"));
indexWriter.addDocument(config.build(taxoWriter, doc));
doc = new Document();
doc.add(new FacetField("Author", "Lisa"));
doc.add(new FacetField("Publish Date", "2010", "10", "20"));
indexWriter.addDocument(config.build(taxoWriter, doc));
doc = new Document();
doc.add(new FacetField("Author", "Lisa"));
doc.add(new FacetField("Publish Date", "2012", "1", "1"));
indexWriter.addDocument(config.build(taxoWriter, doc));
doc = new Document();
doc.add(new FacetField("Author", "Susan"));
doc.add(new FacetField("Publish Date", "2012", "1", "7"));
indexWriter.addDocument(config.build(taxoWriter, doc));
doc = new Document();
doc.add(new FacetField("Author", "Frank"));
doc.add(new FacetField("Publish Date", "1999", "5", "5"));
indexWriter.addDocument(config.build(taxoWriter, doc));
indexWriter.close();
taxoWriter.close();
}
/** User runs a query and counts facets. */
private List<FacetResult> facetsWithSearch() throws IOException {
DirectoryReader indexReader = DirectoryReader.open(indexDir);
IndexSearcher searcher = new IndexSearcher(indexReader);
TaxonomyReader taxoReader = new DirectoryTaxonomyReader(taxoDir);
FacetsCollector fc = new FacetsCollector();
// MatchAllDocsQuery is for "browsing" (counts facets
// for all non-deleted docs in the index); normally
// you'd use a "normal" query:
FacetsCollector.search(searcher, new MatchAllDocsQuery(), 10, fc);
// Retrieve results
List<FacetResult> results = new ArrayList<FacetResult>();
// Count both "Publish Date" and "Author" dimensions
Facets facets = new FastTaxonomyFacetCounts(taxoReader, config, fc);
results.add(facets.getTopChildren(10, "Author"));
results.add(facets.getTopChildren(10, "Publish Date"));
indexReader.close();
taxoReader.close();
return results;
}
/**
* User runs a query and counts facets only without collecting the matching
* documents.
*/
private List<FacetResult> facetsOnly() throws IOException {
DirectoryReader indexReader = DirectoryReader.open(indexDir);
IndexSearcher searcher = new IndexSearcher(indexReader);
TaxonomyReader taxoReader = new DirectoryTaxonomyReader(taxoDir);
FacetsCollector fc = new FacetsCollector();
// MatchAllDocsQuery is for "browsing" (counts facets
// for all non-deleted docs in the index); normally
// you'd use a "normal" query:
searcher.search(new MatchAllDocsQuery(), null /* Filter */, fc);
// Retrieve results
List<FacetResult> results = new ArrayList<FacetResult>();
// Count both "Publish Date" and "Author" dimensions
Facets facets = new FastTaxonomyFacetCounts(taxoReader, config, fc);
results.add(facets.getTopChildren(10, "Author"));
results.add(facets.getTopChildren(10, "Publish Date"));
indexReader.close();
taxoReader.close();
return results;
}
/**
* User drills down on 'Publish Date/2010', and we return facets for
* 'Author'
*/
private FacetResult drillDown() throws IOException {
DirectoryReader indexReader = DirectoryReader.open(indexDir);
IndexSearcher searcher = new IndexSearcher(indexReader);
TaxonomyReader taxoReader = new DirectoryTaxonomyReader(taxoDir);
// Passing no baseQuery means we drill down on all
// documents ("browse only"):
DrillDownQuery q = new DrillDownQuery(config);
// Now user drills down on Publish Date/2010:
q.add("Publish Date", "2010");
FacetsCollector fc = new FacetsCollector();
FacetsCollector.search(searcher, q, 10, fc);
// Retrieve results
Facets facets = new FastTaxonomyFacetCounts(taxoReader, config, fc);
FacetResult result = facets.getTopChildren(10, "Author");
indexReader.close();
taxoReader.close();
return result;
}
/**
* User drills down on 'Publish Date/2010', and we return facets for both
* 'Publish Date' and 'Author', using DrillSideways.
*/
private List<FacetResult> drillSideways() throws IOException {
DirectoryReader indexReader = DirectoryReader.open(indexDir);
IndexSearcher searcher = new IndexSearcher(indexReader);
TaxonomyReader taxoReader = new DirectoryTaxonomyReader(taxoDir);
// Passing no baseQuery means we drill down on all
// documents ("browse only"):
DrillDownQuery q = new DrillDownQuery(config);
// Now user drills down on Publish Date/2010:
q.add("Publish Date", "2010");
DrillSideways ds = new DrillSideways(searcher, config, taxoReader);
DrillSidewaysResult result = ds.search(q, 10);
// Retrieve results
List<FacetResult> facets = result.facets.getAllDims(10);
indexReader.close();
taxoReader.close();
return facets;
}
/** Runs the search example. */
public List<FacetResult> runFacetOnly() throws IOException {
index();
return facetsOnly();
}
/** Runs the search example. */
public List<FacetResult> runSearch() throws IOException {
index();
return facetsWithSearch();
}
/** Runs the drill-down example. */
public FacetResult runDrillDown() throws IOException {
index();
return drillDown();
}
/** Runs the drill-sideways example. */
public List<FacetResult> runDrillSideways() throws IOException {
index();
return drillSideways();
}
/** Runs the search and drill-down examples and prints the results. */
public static void main(String[] args) throws Exception {
System.out.println("Facet counting example:");
System.out.println("-----------------------");
FacetDemo example1 = new FacetDemo();
List<FacetResult> results1 = example1.runFacetOnly();
System.out.println("Author: " + results1.get(0));
System.out.println("Publish Date: " + results1.get(1));
System.out.println("Facet counting example (combined facets and search):");
System.out.println("-----------------------");
FacetDemo example = new FacetDemo();
List<FacetResult> results = example.runSearch();
System.out.println("Author: " + results.get(0));
System.out.println("Publish Date: " + results.get(1));
System.out.println("\n");
System.out.println("Facet drill-down example (Publish Date/2010):");
System.out.println("---------------------------------------------");
System.out.println("Author: " + example.runDrillDown());
System.out.println("\n");
System.out.println("Facet drill-sideways example (Publish Date/2010):");
System.out.println("---------------------------------------------");
for (FacetResult result : example.runDrillSideways()) {
System.out.println(result);
}
}
}














 1713
1713

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









