







Lucene系列-index扩展
Shard与Replica
- Shard:index数据分片.当索引数据到达百亿级别的,单份数据索引读取和搜索都是非常耗时间的,即使在用earlytermination的情况下,latency也在100ms左右. 数据分片成shard,可以快速的提高搜索效率.
- Replica:shard的备份,在搜索QPS较高的时候,Replica可以提供搜索的吞吐量. 一般包含一个primary shard和多个replica shards.
Index扩展
index扩展一般包含横向扩展和纵向扩展,将大数据切分成小数据块,或者将数据分片复制copy到一台机器.
横向扩展策略:
考虑线上机器运行,此时要保证搜索正常的work,并向外提供搜索服务.
1.首先应该停掉index write操作, 即利用一些消息队列存储操作阶段的线上来的增量消息.
2.循环依次复制所有的消息分片.
3.打开之前的index服务接口和新的replica.
纵向扩展策略:
当索引量比较大,disk读写速度变慢,搜索latency变高.我们需要增加分片,从而改变单个shard index的大小
纵向扩展分两种:
(1)增加新的shard,之后所有的新增索引建到新的shard上,之前的删除操作要遍历所有的shard.
(2)增加新的shard,把所有数据在平均分配一下.例如之前有2个shard,现在将2个shard的数据平均分配到3个shard上.新增的数据还是按路由规则(hash规则)写入到某一个特定的shard中.
以下策略是主要是针对无原始数据或者重建索引时间代价比较大的,这种情况下,即使在hadoop index 离线索引也不可抵消.我们实现了以下方案.具体实现:
以2个shard扩展成3个shard为例,如图:
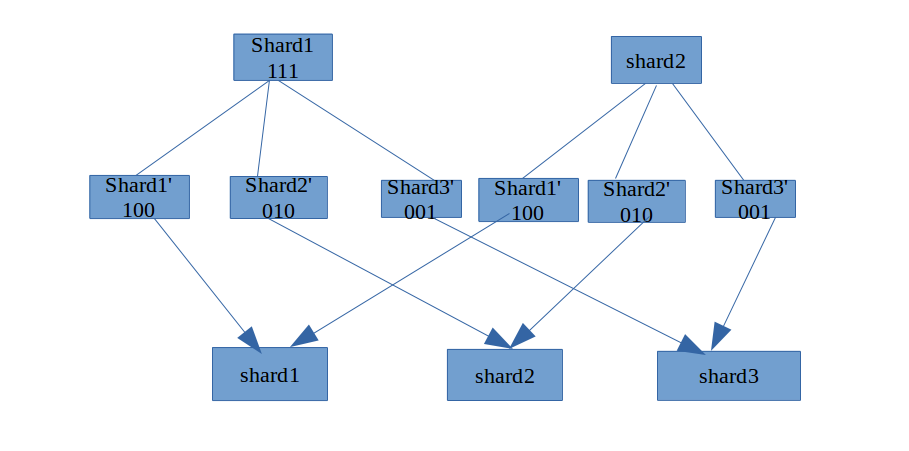
我们定义document文档路由规则, hash函数: routeId = documentId % shardSize;
根据hash函数我们可以知道,shard1上的数据需要分裂数据到shard1’, shard2’, shard3’上.我们知道lucene底层数据的删除是先将要删除的doc设置标识位delete标识, 在index merge的时候进行删除.我们可以利用这个规律来进行. 假设shard1有三个文档.原始标识位是111,然后复制2份, 这时候就有三份shard1.通过设置标识位100,010,001,这样就shard1的数据根据我们之前定义的规则hash出来了.同理shard2也是这样.
如此进行之后,将分配到同一个node上的两个segment数据合并成统一的一份索引.
上面要注意的问题:
1.上线服务一致性问题,即在shard1,shard2分裂的过程中,这个时间段如果还继续向外提供服务,可能不稳定.因此如果有多个replica服务就可以停掉此服务.
2.线上数据的copy是比较费时间的,即相对于数据重建索引的代价而言,一般较小















 388
388

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









