







1、什么是分区
2、为什么要把表进行分区
3、怎么把表进行分区
1、什么是分区
简单的理解就是把一个数据库表分成若干个小的数据库表。
举个例子:一个进货表中有10条数据(主键ID自增长),我们可以按照个数进行分区,把ID 1-3的放一个表中,4-6的放一个表中,7-10的放一个表中;这样,我们就相当于把这个进货表分成了3个小表(即3个区)。当我们在通过ID进行查询的时候,如查询ID=5,这样就会只查询ID为4-6所在的表,表中的数据量由原来的10个变成了现在的3个,数据量小了,查询速度自然也就快了。
有人会说,我可以直接建立3张表(即进货表a、进货表b、进货表c),也能达到上面的效果。
这就是我要说的把表进行分区和建立真实表的区别,如果按照上面所说,建立了3张进货表,当我们在使用和查询的时候就需要操作三张表,对于程序员来说是件很麻烦的事儿,而且极易出现错误。
用分区就完全解决了上面的问题,表面上我们把进货表分成了3部分,但从逻辑上看他依然是一张表,对于程序员使用上来说就是一张表。
2、为什么要把表进行分区
当数据量超大、且查询起来很慢的时候,我们就要考虑优化了;把表进行分区就是优化的一种。通过对表进行分区,可以大大的节省时间,当然也并不是所有的表进行分区之后都能达到优化的作用,反之还会使速度变慢,开销变大。下面会举例说明。
那么,什么样的表适合分区呢?
1、数据量超级大,大到个人感觉查询起来较慢的数据量。(没有具体数字,个人感觉百万级数据的表算是大的了)
2、一部分数据不经常使用,例如几十年的历史数据,在查询的时候只需要查询进一两年的数据;即数据库表中有经常不用的数据。(要是一直不用,建议对数据进行封存),要是这个表中的数据经常使用,即使有千万或是过亿的数据,也不要进行表分区,不然会更慢的。
3、表分区和一些索引是有冲突的,对于表来说,分区要是优于索引的话,可以进行分区。(下面会有具体例子证明)
3、怎么把表进行分区
①、创建分区函数
②、创建分区方案
③、创建数据库表使用分区方案
①、创建分区函数
创建分区函数,是为了告诉SQL Server我们以什么样的条件对表进行分区的。
还是以上面进货表(a表)为例,把ID 1-3的放一个表中,4-6的放一个表中,7-10的放一个表中。代码如下:
- --创建分区函数(分成三个区,1区小于等于3的、2区大于3小于等于6的、3区大于6的)
- CREATE PARTITION FUNCTION partfunA (int)
- AS RANGE LEFT FOR VALUES (3,6)
1、CREATE PARTITION FUNCTION partfunA(int) 是创建分区函数名为partfunA的分区函数,分区的条件为(int)型
2、AS RANGE LEFT FOR VALUES(3,6)是将表按照条件(1区小于等于3的、2区大于3小于等于6的、3区大于6的)分成3个区;LEFT或RIGHT是条件(即3和6),放在左/右边的分区(这里用LEFT,id为3的数据就放在第一分区里,id为6的数据放在第二分区里)
如图1所示,创建后会在数据库存储下分区函数下出现 partfunA 分区函数
②、创建分区方案
创建分区方案,是将分区函数生成的分区映射到文件组中去。分区方案是为了告诉SQL Server将已分区的数据放在哪个文件组中。代码如下:
- --创建分区方案(将已分区的数据放在主文件里,三个区都放在主文件里)
- CREATE PARTITION SCHEME partschA
- AS PARTITION partfunA
- TO ([Primary],[Primary],[Primary])
注释:
1、CREATE PARTITION SCHEME partschA是创建一个名为partschA的分区方案。
2、AS PARTITION partfunA是使用partfunA分区函数。
3、TO ([Primary],[Primary],[Primary])把partfunA分区函数划分出来的数据存放在文件组中(这里都存放在主数据文件中)
如图2所示,创建后会在数据库存储下分区方案下出现 partschA 分区方案
③、创建数据库表使用分区方案
创建数据库表,并且使用分区方案。代码如下:
- --创建数据库表a,并使用分区方案partschA
- if object_id('[a]') is not null drop table [a]
- go
- create table [a]
- (
- [ID] int,
- [品名] varchar(6),
- [入库数量] int,
- [入库时间] datetime
- ) on partschA(ID)
注释:
1、on partschA(ID)对a表使用partschA分区方案
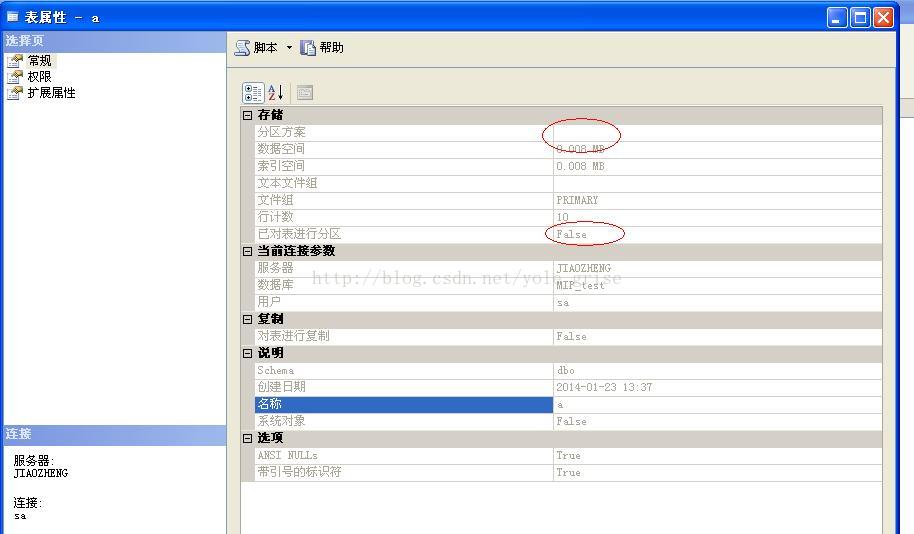
右键点击表a属性-常规,如下图:
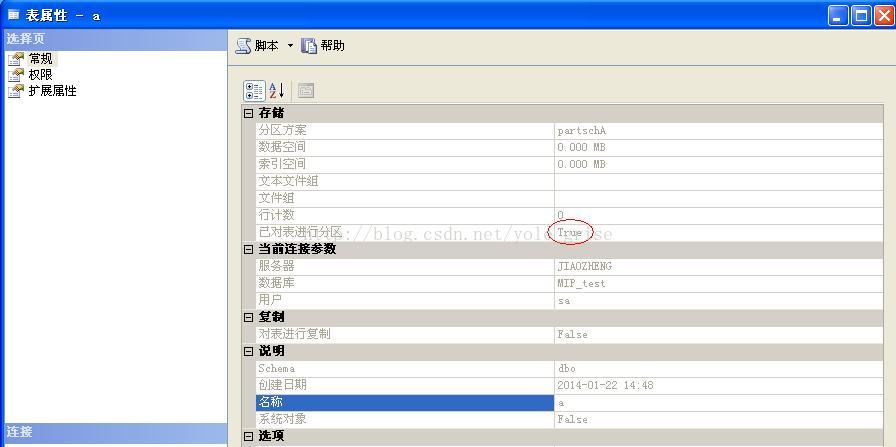
如图3所示,创建的表a已经进行了分区。
1、对现有普通表进行分区
2、对现有分区表进行添加一个分区
3、对现有分区表进行删除一个分区
4、对现有分区表进行修改分区
5、把现有分区表改回原普通表
1、对现有普通表表进行分区
创建普通表a,为表a添加数据,代码如下:
- --创建数据库表a
- if object_id('[a]') is not null drop table [a]
- go
- create table [a]
- (
- [ID] int,
- [品名] varchar(6),
- [入库数量] int,
- [入库时间] datetime
- CONSTRAINT [PK_a] PRIMARY KEY CLUSTERED --创建主键
- (
- [Id] ASC
- )
- )
- --为表a添加测试数据
- insert [a]
- select 1,'矿泉水',100,'2014-01-02' union all
- select 2,'方便面',60,'2014-01-03' union all
- select 3,'方便面',50,'2014-01-03' union all
- select 4,'矿泉水',80,'2014-01-04' union all
- select 5,'方便面',60,'2014-01-05' union all
- select 6,'方便面',50,'2014-01-06' union all
- select 7,'矿泉水',80,'2014-01-06' union all
- select 8,'方便面',60,'2014-01-07' union all
- select 9,'方便面',50,'2014-01-09' union all
- select 10,'矿泉水',80,'2014-01-11'
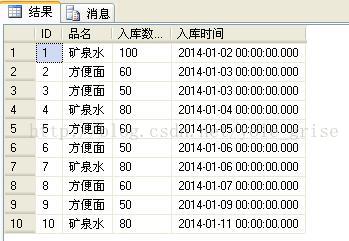
- select * from a
查询结果如图1所示
右键表a属性查看,如图2所示,表a为普通表,并未分区。
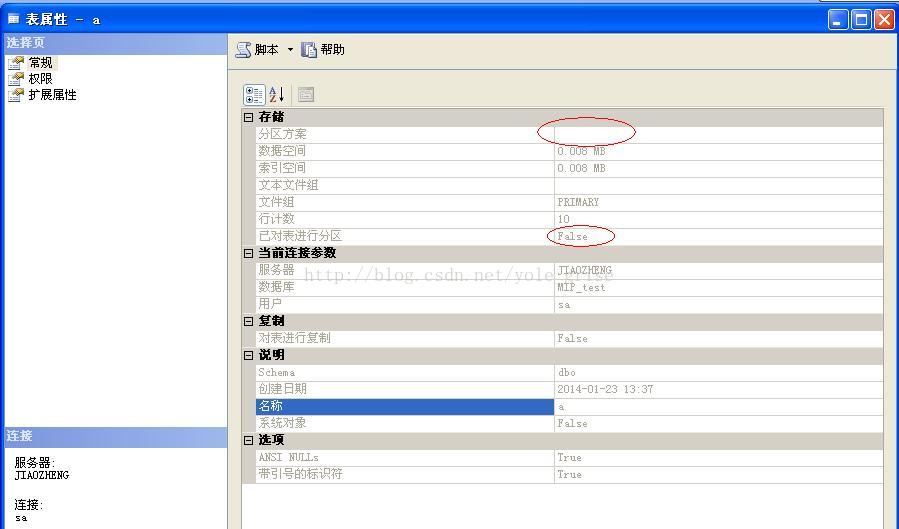
下面是为表a进行分区:
①、删除表a主键(聚集索引)
②、创建一个新的聚集索引,在此聚集索引中使用分区方案
③、创建主键,只能设定为非聚集索引
【这里是参考代码:第一章 分区函数 和 分区方案 代码】
代码如下:
- --删除主键(聚集索引)
- ALTER TABLE a DROP constraint PK_a
- --创建一个新的聚集索引,在该聚集索引中使用分区方案
- create CLUSTERED INDEX PK_a ON a([id])
- ON partschA([id])
- --创建主键,但不设为聚集索引
- ALTER TABLE a ADD CONSTRAINT PK_a1 PRIMARY KEY NONCLUSTERED
- (
- [ID] ASC
- ) ON [PRIMARY]
查看表a,如图3所示:
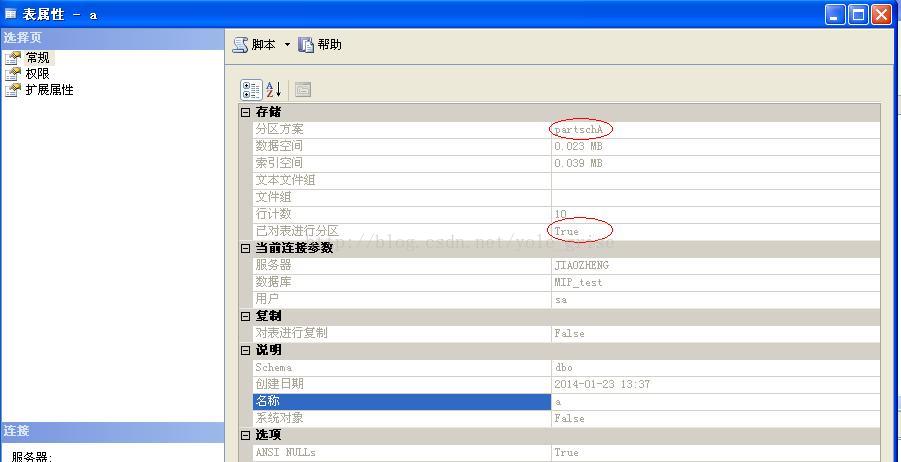
表a现在是分区表了。
首先来看一下分区表a的分区方案和分区函数,代码如下:
- --创建分区函数(分成三个区,1区小于等于3的、2区大于3小于等于6的、3区大于6的)
- CREATE PARTITION FUNCTION partfunA (int)
- AS RANGE LEFT FOR VALUES (3,6)
- --创建分区方案(将已分区的数据放在主文件里,三个区都放在主文件里)
- CREATE PARTITION SCHEME partschA
- AS PARTITION partfunA
- TO ([Primary],[Primary],[Primary])
①、修改分区方案,指定下一个分区的文件组
②、修改分区函数
代码如下:
- --修改分区方案,指定下一个分区的文件组为[Primary]
- ALTER PARTITION SCHEME partschA
- NEXT USED [Primary]
- --修改分区函数,修改后为4个区(1区小于等于3的、2区大于3小于等于6的、3区大于6小于等于8的、4区大于8的)
- ALTER PARTITION FUNCTION partfunA()
- SPLIT RANGE (8)
注释:
①、 NEXT USED [Primary]:指定下一个分区的文件组为[Primary]
②、SPLIT RANGE (8) :类似于开始创建时的
CREATE PARTITION FUNCTION partfunA (int)
AS RANGE LEFT FOR VALUES (3,6,8)
修改后为4个区(1区小于等于3的、2区大于3小于等于6的、3区大于6小于等于8的、4区大于8的)
查看分区及分区数据:
代码如下:
- --查看分区
- select $partition.partfunA(id) as '分区号',count(*) as '分区内数据个数'
- from a group by $partition.partfunA(id)
- --查看各分区数据
- select * from a where $partition.partfunA(id)=1
- select * from a where $partition.partfunA(id)=2
- select * from a where $partition.partfunA(id)=3
- select * from a where $partition.partfunA(id)=4
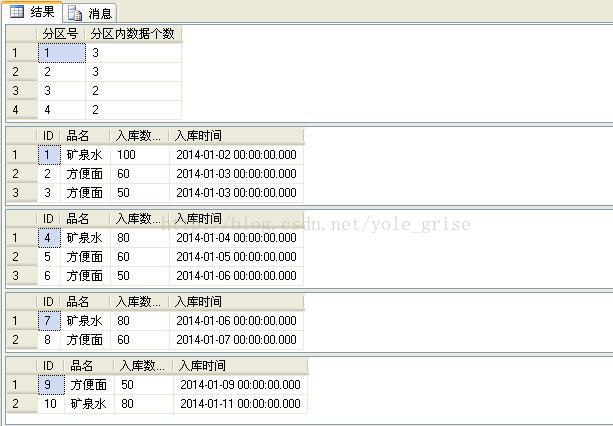
3、对现有分区表进行删除一个分区
修改分区函数,代码如下:
- --删除一个分区(即剩下3个分区,1区小于等于6的、2区大于6小于等于8的、3区大于8的)
- ALTER PARTITION FUNCTION partfunA()
- MERGE RANGE (3)
查看分区及分区数据:
代码如下:
- --查看分区
- select $partition.partfunA(id) as '分区号',count(*) as '分区内数据个数'
- from a group by $partition.partfunA(id)
- --查看各分区数据
- select * from a where $partition.partfunA(id)=1
- select * from a where $partition.partfunA(id)=2
- select * from a where $partition.partfunA(id)=3
- select * from a where $partition.partfunA(id)=4
如图5所示,表a只剩下3个分区。
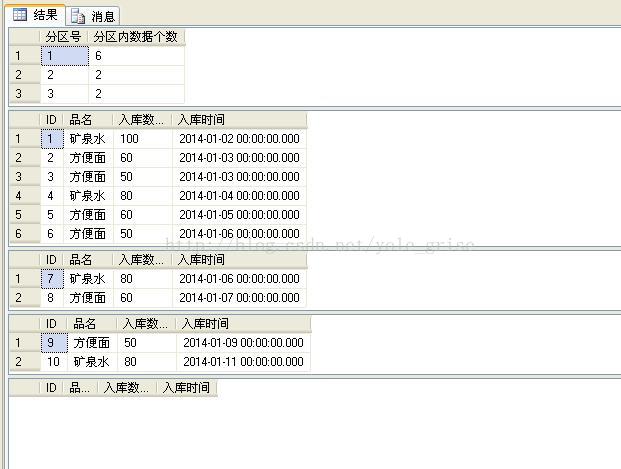
4、对现有分区表进行修改分区
修改分区,其实就是重复操作2和3,,即删除原有分区再添加新的分区。
5、把现有分区表改回原普通表
这里我利用的是聚集索引和表分区冲突的原理,进行的把分区表改成普通表。
①、删除分区索引(因为一个表只能有一个聚集索引,这里分区索引就是聚集索引;所以我们想新建一个聚集索引是做不到的,只能先把分区索引删掉)
②、删除主键(非聚集索引),之前我们在ID上设置了主键,但生成的是非聚集索引。这里我们要在这个主键ID上建立新的聚集索引,所以要先把之前的非聚集索引删掉。
③、重建聚集索引
代码如下:
- --删除分区索引
- drop index a.PK_a
- --删除主键(非聚集索引)
- ALTER TABLE a DROP constraint PK_a1
- --重建聚集索引
- ALTER TABLE a ADD CONSTRAINT PK_a PRIMARY KEY CLUSTERED
- (
- [ID] ASC
- ) ON [PRIMARY]
from :http://blog.csdn.net/yole_grise/article/details/18702843














 1694
1694











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









