






Even though with the .NET framework we don't have to actively worry about memory management and garbage collection (GC), we still have to keep memory management and GC in mind in order to optimize the performance of our applications. Also, having a basic understanding of how memory management works will help explain the behavior of the variables we work with in every program we write. In this article I'll cover the basics of the Stack and Heap, types of variables and why some variables work as they do.
There are two places the .NET framework stores items in memory as your code executes. If you haven't already met, let me introduce you to the Stack and the Heap. Both the stack and heap help us run our code. They reside in the operating memory on our machine and contain the pieces of information we need to make it all happen.
Stack vs. Heap: What's the difference?
The Stack is more or less responsible for keeping track of what's executing in our code (or what's been "called"). The Heap is more or less responsible for keeping track of our objects (our data, well... most of it - we'll get to that later.).
Think of the Stack as a series of boxes stacked one on top of the next. We keep track of what's going on in our application by stacking another box on top every time we call a method (called a Frame). We can only use what's in the top box on the stack. When we're done with the top box (the method is done executing) we throw it away and proceed to use the stuff in the previous box on the top of the stack. The Heap is similar except that its purpose is to hold information (not keep track of execution most of the time) so anything in our Heap can be accessed at any time. With the Heap, there are no constraints as to what can be accessed like in the stack. The Heap is like the heap of clean laundry on our bed that we have not taken the time to put away yet - we can grab what we need quickly. The Stack is like the stack of shoe boxes in the closet where we have to take off the top one to get to the one underneath it.
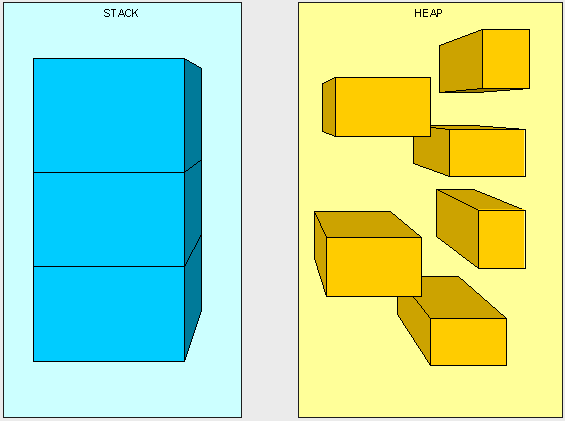
The picture above, while not really a true representation of what's happening in memory, helps us distinguish a Stack from a Heap.
The Stack is self-maintaining, meaning that it basically takes care of its own memory management. When the top box is no longer used, it's thrown out. The Heap, on the other hand, has to worry about Garbage collection (GC) - which deals with how to keep the Heap clean (no one wants dirty laundry laying around... it stinks!).
What goes on the Stack and Heap?
We have four main types of things we'll be putting in the Stack and Heap as our code is executing: Value Types, Reference Types, Pointers, and Instructions.
Value Types:
In C#, all the "things" declared with the following list of type declarations are Value types (because they are from System.ValueType):
- bool
- byte
- char
- decimal
- double
- enum
- float
- int
- long
- sbyte
- short
- struct
- uint
- ulong
- ushort
Reference Types:
All the "things" declared with the types in this list are Reference types (and inherit from System.Object... except, of course, for object which is the System.Object object):
- class
- interface
- delegate
- object
- string
Pointers:
The third type of "thing" to be put in our memory management scheme is a Reference to a Type. A Reference is often referred to as a Pointer. We don't explicitly use Pointers, they are managed by the Common Language Runtime (CLR). A Pointer (or Reference) is different than a Reference Type in that when we say something is a Reference Type is means we access it through a Pointer. A Pointer is a chunk of space in memory that points to another space in memory. A Pointer takes up space just like any other thing that we're putting in the Stack and Heap and its value is either a memory address or null.
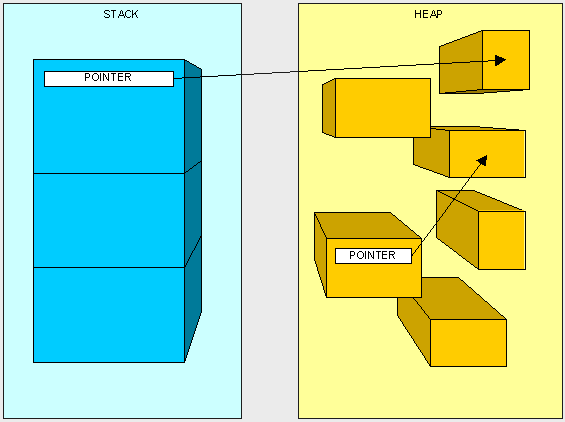
Instructions:
You'll see how the "Instructions" work later in this article...
How is it decided what goes where? (Huh?)
Ok, one last thing and we'll get to the fun stuff.
Here are our two golden rules:
- A Reference Type always goes on the Heap - easy enough, right?
- Value Types and Pointers always go where they were declared. This is a little more complex and needs a bit more understanding of how the Stack works to figure out where "things" are declared.
The Stack, as we mentioned earlier, is responsible for keeping track of where we are in the execution of our code (or what's been called). When our code makes a call to execute a method, it puts the instructions we have coded (inside the method) on the stack, followed by the method's parameters. Then, as we go through the code and run into variables within the method they are "stacked" on top of the stack. This will be easiest to understand by example...
Take the following method.
public int AddFive(int pValue)
{
int result;
result = pValue + 5;
return result;
}
Here's what happens at the very top of the stack. Keep in mind that what we are looking at is "stacked" on top of many other items already living in the stack:
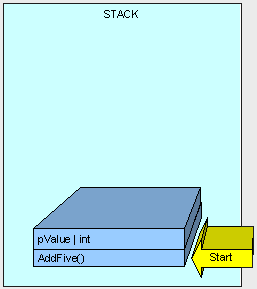
First the method itself (only bytes needed to execute the logic) is placed on the stack followed by its parameter (we'll talk more about passing parameters later).
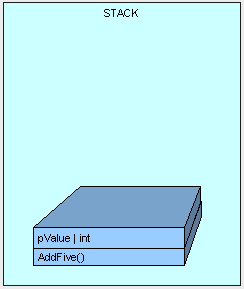
Next, control (the thread executing the method) is passed to the instructions in the AddFive() part of the stack.
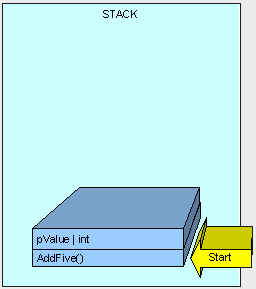
As the method executes, we need some memory for the "result" variable and it is allocated on the stack.
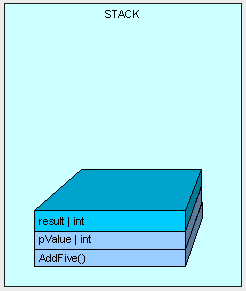
The method finishes execution and our result is returned.
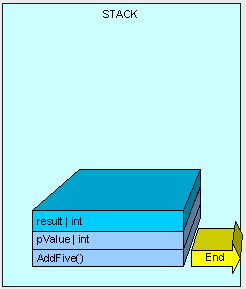
And all memory allocated on the stack is cleaned up by moving a pointer to the available memory address where AddFive() used to live and we go down to the previous method on the stack (not seen here).
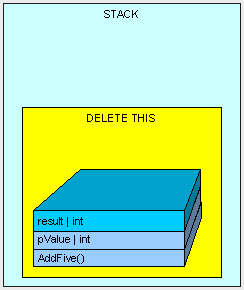
In this example, our "result" variable is placed on the stack. As a matter of fact, every time a Value Type is declared within the body of a method, it will be placed on the stack.
Now, Value Types are also sometimes placed on the Heap. Remember the rule, Value Types always go where they were declared? Well, if a Value Type is declared outside of a method, but inside a Reference Type it will be placed within the Reference Type on the Heap.
Here's another example.
If we have the following MyInt class (which is a Reference Type because it is a class):
public class MyInt
{
public int MyValue;
}
and the following method is executing:
public MyInt AddFive(int pValue)
{
MyInt result = new MyInt();
result.MyValue = pValue + 5;
return result;
}
Just as before, the method itself (only bytes needed to execute the logic) is placed on the stack followed by its parameter. Next, control (the thread executing the method) is passed to the instructions in the AddFive() part of the stack.
Now is when it gets interesting...
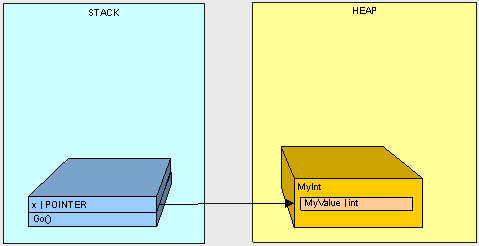
Because MyInt is a Reference Type, it is placed on the Heap and referenced by a Pointer on the Stack.
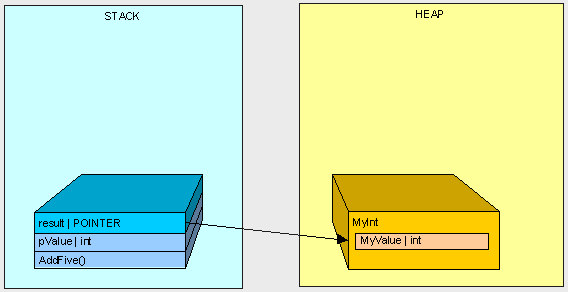
After AddFive() is finished executing (like in the first example), and we are cleaning up...
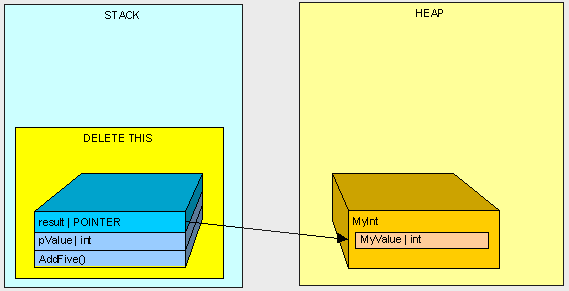
we're left with an orphaned MyInt in the heap (there is no longer anyone in the Stack standing around pointing to MyInt)!
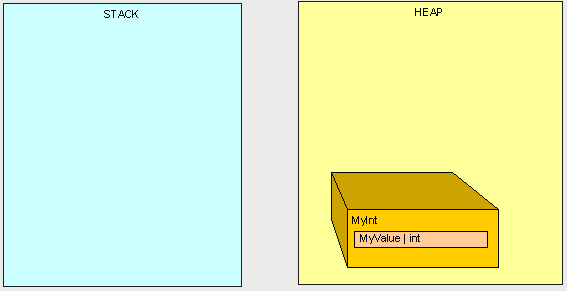
This is where the Garbage Collection (GC) comes into play. Once our program reaches a certain memory threshold and we need more Heap space, our GC will kick off. The GC will stop all running threads (a FULL STOP), find all objects in the Heap that are not being accessed by the main program and delete them. The GC will then reorganize all the objects left in the Heap to make space and adjust all the Pointers to these objects in both the Stack and the Heap. As you can imagine, this can be quite expensive in terms of performance, so now you can see why it can be important to pay attention to what's in the Stack and Heap when trying to write high-performance code.
Ok... That great, but how does it really affect me?
Good question.
When we are using Reference Types, we're dealing with Pointers to the type, not the thing itself. When we're using Value Types, we're using the thing itself. Clear as mud, right?
Again, this is best described by example.
If we execute the following method:
public int ReturnValue()
{
int x = new int();
x = 3;
int y = new int();
y = x;
y = 4;
return x;
}
We'll get the value 3. Simple enough, right?
However, if we are using the MyInt class from before
public class MyInt
{
public int MyValue;
}
and we are executing the following method:
public int ReturnValue2()
{
MyInt x = new MyInt();
x.MyValue = 3;
MyInt y = new MyInt();
y = x;
y.MyValue = 4;
return x.MyValue;
}
What do we get?... 4!
Why?... How does x.MyValue get to be 4?... Take a look at what we're doing and see if it makes sense:
In the first example everything goes as planned:
public int ReturnValue()
{
int x = 3;
int y = x;
y = 4;
return x;
}
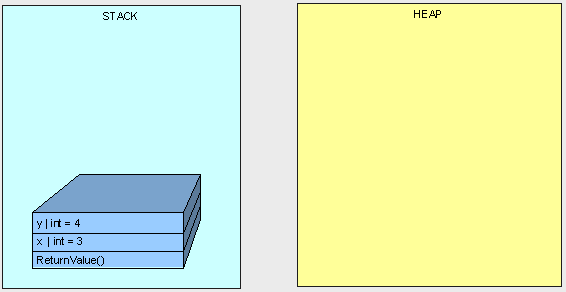
In the next example, we don't get "3" because both variables "x" and "y" point to the same object in the Heap.
public int ReturnValue2()
{
MyInt x;
x.MyValue = 3;
MyInt y;
y = x;
y.MyValue = 4;
return x.MyValue;
}
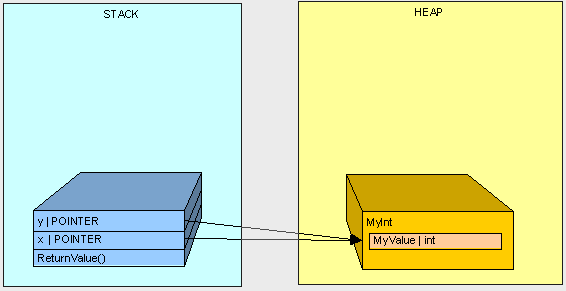
Hopefully this gives you a better understanding of a basic difference between Value Type and Reference Type variables in C# and a basic understanding of what a Pointer is and when it is used. In the next part of this series, we'll get further into memory management and specifically talk about method parameters.
For now...
Happy coding.
In Part I we covered the basics of the Heap and Stack functionality and where Variable Types and Reference Types are allocated as our program executes. We also covered the basic idea of what a Pointer is.
- Space is allocated and the method itself is copied from the instance of our object to the Stack for execution (called a Frame). This is only the bits containing the instructions required to execute the method and includes no data items.
- The calling address (a pointer) is placed on the stack. This is basically a GOTO instruction so when the thread finishes running our method it knows where to go back to in order to continue execution. (However, this is a nice-to-know, not a need-to-know, because it will not affect how we code.)
- Space is allocated for our method parameters and they are copied over. This is what we want to look at more closely.
- Control is passed to the base of the frame and the thread starts executing code. Hence, we have another method on the "call stack".
{
int result;
result = pValue + 5;
return result;
}
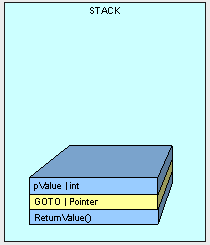
As discussed in Part I, Parameter placement on the stack will be handled differently depending on whether it is a value type or a reference type. A value types is copied over and the reference of a reference type is copied over.
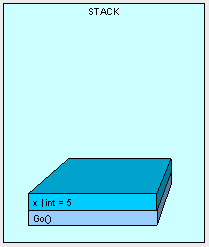
Next, AddFive() is placed on the stack with space for it's parameters and the value is copied, bit by bit from x.
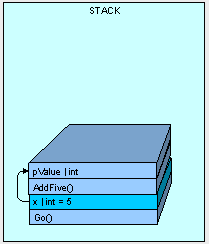
When AddFive() has finished execution, the thread is passed back to Go() and AddFive() and pValue are removed:
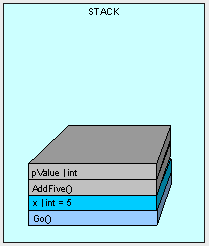
So it makes sense that the output from our code is "5", right? The point is that any value type parameters passed into a method are carbon copies and we count on the original variable's value to be preserved.
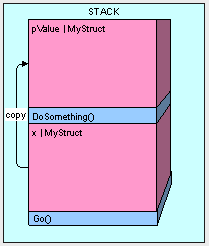
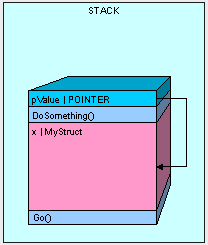
The only thing we have to watch out for when passing our value type by reference is that we have access to the value type's value. Whatever is changed in pValue is changed in x. Using the code below, our results are going to be "12345" because the pValue.a actually is looking at the memory space where our original x variable was declared.
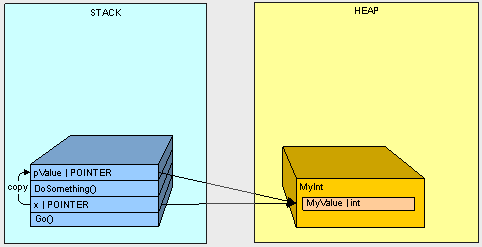
- The method Go() goes on the stack
- The variable x in the Go() method goes on the stack
- DoSomething() goes on the stack
- The parameter pValue goes on the stack
- The value of x (the address of MyInt on the stack) is copied to pValue
x is Vegetable : True
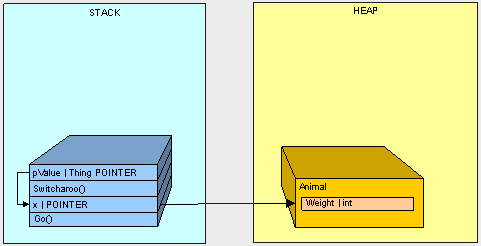
- The Go() method goes on the stack
- The x pointer goes on the stack
- The Animal goes on the heap
- The Switcharoo() method goes on the stack
- The pValue goes on the stack and points to x
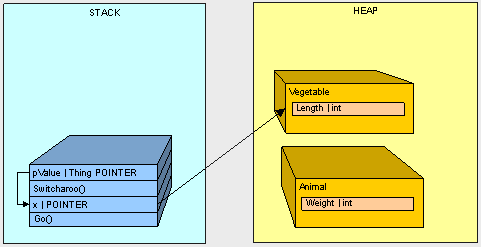
- The Vegetable goes on the heap
- The value of x is changed through pValue to the address of the Vegetable
Ted : Dude!, I have a Red shoe on my right foot, and a Red on my left foot.
Ted : Dude!, I have a Red shoe on my right foot, and a Red on my left foot
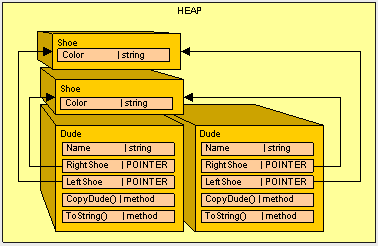
Ted : Dude!, I have a Red shoe on my right foot, and a Red on my left foot
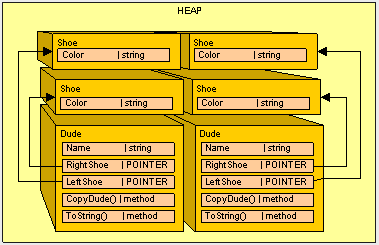
Ted : Dude!, I have a Red shoe on my right foot, and a Red on my left foot.
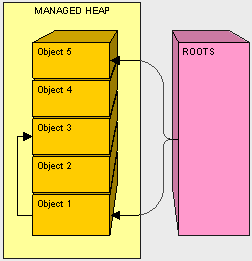
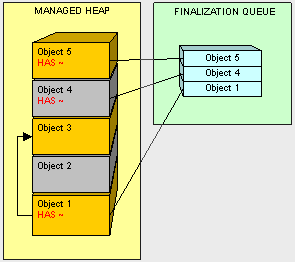
- Global/Static pointers. One way to make sure our objects are not garbage collected by keeping a reference to them in a static variable.
- Pointers on the stack. We don't want to throw away what our application's threads still need in order to execute.
- CPU register pointers. Anything in the managed heap that is pointed to by a memory address in the CPU should be preserved (don't throw it out).
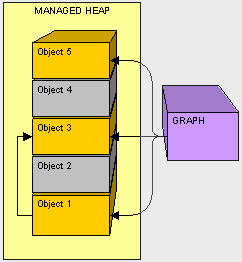
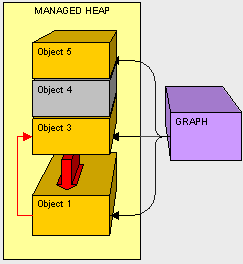
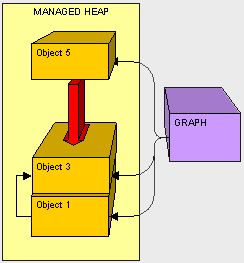
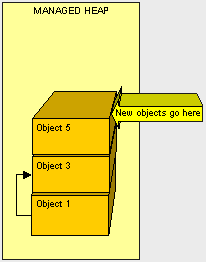
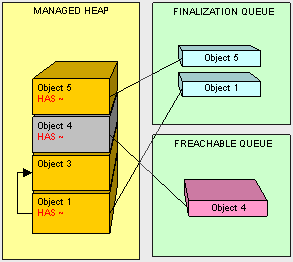
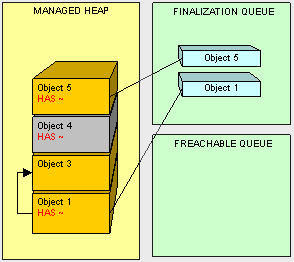
- Clean up. Don't leave resources open! Be sure to close all connections that are opened and clean up all non-managed objects as soon as possible. As a general rule when using non-managed objects, instantiate as late as possible and clean up as soon as possible.
- Don't overdo references. Be reasonable when using references objects. Remember, if our object is alive, all of it's referenced objects will not be collected (and so on, and so on). When we are done with something referenced by class, we can remove it by either setting the reference to null. One trick I like to do is setting unused references to a custom light weight NullObject to avoid getting null reference exceptions. The fewer references laying about when the GC kicks off, the less pressure the mapping process will be.
- Easy does it with finalizers. Finalizers are expensive during GC we should ONLY use them if we can justify it. If we can use IDisposible instead of a finalizer, it will be more efficient because our object can be cleaned up in one GC pass instead of two.
- Keep objects and their children together. It is easier on the GC to copy large chunks of memory together instead of having to essentially de-fragment the heap at each pass, so when we declare a object composed of many other objects, we should instantiate them as closely together as possible.
- And finally... keep objects lighter by making the methods static where appropriate.
-Happy coding


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









