




 Adaboost是一种集成学习方法,通过结合多个弱分类器形成强分类器。本文介绍了Adaboost的工作原理,包括如何根据错误率调整弱分类器权重,并通过实例展示了其在简单数据集上的应用和代码实现。最后,还提到了Adaboost的ROC曲线绘制和相关理论解释。
Adaboost是一种集成学习方法,通过结合多个弱分类器形成强分类器。本文介绍了Adaboost的工作原理,包括如何根据错误率调整弱分类器权重,并通过实例展示了其在简单数据集上的应用和代码实现。最后,还提到了Adaboost的ROC曲线绘制和相关理论解释。
Adaboost也是一种原理简单,但很实用的有监督机器学习算法,它是daptive boosting的简称。说到boosting算法,就不得提一提bagging算法,他们两个都是把一些弱分类器组合起来来进行分类的方法,统称为集成方法(ensemble method),类似于投资,“不把鸡蛋放在一个篮子”,虽然每个弱分类器分类的不那么准确,但是如果把多个弱分类器组合起来可以得到相当不错的结果,另外要说的是集成方法还可以组合不同的分类器,而Adaboost和boosting算法的每个弱分类器的类型都一样的。他们两个不同的地方是:boosting的每个弱分类器组合起来的权重不一样,本节的Adaboost就是一个例子,而bagging的每个弱分类器的组合权重是相等,代表的例子就是random forest。Random forest的每个弱分类器是决策树,输出的类别有多个决策树分类的类别的众数决定。今天的主题是Adaboost,下面来看看Adaboost的工作原理:
既然Adaboost的每个弱分类器的类型都一样,那么怎么组织安排每个分类器呢?如(图一)所示:
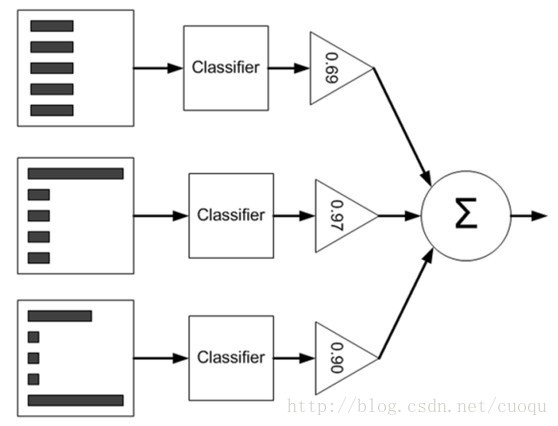
(图一)
(图一)是Adaboost的原理示意图,左边矩形表示数据集,中间表示根据特征阈值来做分类,这样每一个弱分类器都类似于一个单节点的决策树,其实就是阈值判断而已,右边的三角形对每个弱分类器赋予一个权重,最后根据每个弱分类器的加权组合来判断总体类别。要注意一下数据集从上到下三个矩形内的直方图不一样,这表示每个样本的权重也发生了变化,样本权重的一开始初始化成相等的权重,然后根据弱分类器的错误率来调整每个弱分类器的全总alpha,如(图一)中的三角形所示,alpha 的计算如(公式一)所示:

(公式一)
从(公式一)中也能感觉出来,弱分类器权重alpha和弱分类器分类错误率epsilon成反比,如果不能看出反比关系,分子分母同时除以epsilon就可以了,而ln是单调函数。这很make sense,当然分类器的错误率越高,越不能器重它,它的权重就应该低。同样的道理,样本也要区分对待,样本的权重要用弱分类器权重来计算,其实也是间接靠分类错误率,如(公式二)所示:
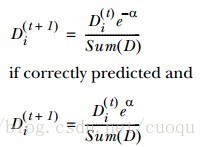
(公式二)
其中D表示样本权重向量,有多少个样本就有多少个权重,下标i表示样本索引,而上标t表示上一次分类器训练迭代次数。这样一直更新迭代,一直到最大迭代次数或者整个分类器错误率为0或者不变时停止迭代,就完成了Adaboost的训练
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 4616
4616

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









