







更新:
没想到这篇文章写出后有这么多人关注和索要源码,有点受宠若惊。说来惭愧,这个工作当时做的很粗糙,源码修改的比较乱,所以一直不太好拿出手。最近终于有时间整理了一下代码并开源出来了。关于代码还有以下几个问题:
~1.在.cu中目前仍然是调用cpu_data接口,所以可能会增加与gpu数据交换的额外耗时,这个不影响使用,后面慢慢优化。~(已解决)
2.目前每层权值修剪的比例仍然是预设的,这个比例需要迭代试验以实现在尽可能压缩权值的同时保证精度。所以如何自动化选取阈值就成为了后面一个继续深入的课题。
3.直接用caffe跑出来的模型依然是原始大小,因为模型依然是.caffemodel类型,虽然大部分权值为0且共享,但每个权值依然以32float型存储,故后续只需将非零权值及其下标以及聚类中心存储下来即可,这部分可参考作者论文,写的很详细。
4.权值压缩仅仅压缩了模型大小,但在前向inference时不会带来速度提升。因此,想要在移动端做好cnn部署,就需要结合小的模型架构、模型量化以及NEON指令加速等方法来实现。
代码开源在github
https://github.com/may0324/DeepCompression-caffe
最近又转战CNN模型压缩了。。。(我真是一年换N个坑的节奏),阅读了HanSong的15年16年几篇比较有名的论文,启发很大,这篇主要讲一下Deep Compression那篇论文,因为需要修改caffe源码,但网上没有人po过,这里做个第一个吃螃蟹的人,记录一下对这篇论文的理解和源码修改过程,方便日后追本溯源,同时如果有什么纰漏也欢迎指正,互相交流学习。
这里就从Why-How-What三方面来讲讲这篇文章。
Why
首先讲讲为什么CNN模型压缩刻不容缓,我们可以看看这些有名的caffe模型大小:
1. LeNet-5 1.7MB
2. AlexNet 240MB
3. VGG-16 552MB
LeNet-5是一个简单的手写数字识别网络,AlexNet和VGG-16则用于图像分类,刷新了ImageNet竞赛的成绩,但是就其模型尺寸来说,根本无法移植到手机端App或嵌入式芯片当中,就算是想通过网络传输,较高的带宽占用率也让很多用户望尘莫及。另一方面,大尺寸的模型也对设备功耗和运行速度带来了巨大的挑战。随着深度学习的不断普及和caffe,tensorflow,torch等框架的成熟,促使越来越多的学者不用过多地去花费时间在代码开发上,而是可以毫无顾及地不断设计加深网络,不断扩充数据,不断刷新模型精度和尺寸,但这样的模型距离实用却仍是望其项背。
在这样的情形下,模型压缩则成为了亟待解决的问题,其实早期也有学者提出了一些压缩方法,比如weight prune(权值修剪),权值矩阵SVD分解等,但压缩率也只是冰山一角,远不能令人满意。今年standford的HanSong的ICLR的一篇论文Deep Compression: Compressing deep neural networks with pruning, trained quantization and Huffman coding一经提出,就引起了巨大轰动,在这篇论文工作中,他们采用了3步,在不损失(甚至有提升)原始模型精度的基础上,将VGG和Alexnet等模型压缩到了原来的35~49倍,使得原本上百兆的模型压缩到不到10M,令深度学习模型在移动端等的实用成为可能。
How
Deep Compression 的实现主要有三步,如下图所示:
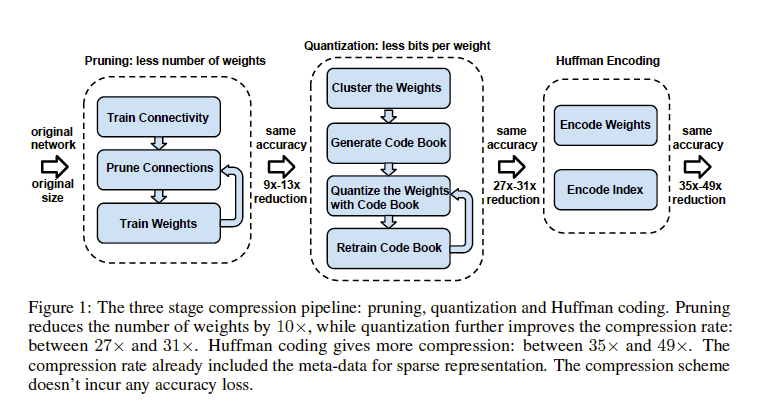
包括Pruning(权值修剪),Quantization(权值共享和量化),Huffman Coding(Huffman编码)。
1.Prunning
如果你调试过caffe模型,观察里面的权值,会发现大部分权值都集中在-1~1之间,即非常小,另一方面,神经网络的提出就是模仿人脑中的神经元突触之间的信息传导,因此这数量庞大的权值中,存在着不可忽视的冗余性,这就为权值修剪提供了根据。pruning可以分为三步:
step1. 正常训练模型得到网络权值;
step2. 将所有低于一定阈值的权值设为0;
step3. 重新训练网络中剩下的非零权值。
经过权值修剪后的稀疏网络,就可以用一种紧凑的存储方式CSC或CSR(compressed sparse column or compressed sparse row)来表示。这里举个栗子来解释下什么是CSR
假设有一个原始稀疏矩阵A

CSR可以将原始矩阵表达为三部分,即AA,JA,IC
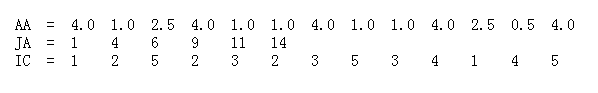
其中,AA是矩阵A中所有非零元素,长度为a,即非零元素个数;
JA是矩阵A中每行第一个非零元素在AA中的位置,最后一个元素是非零元素数加1,长度为n+1, n是矩阵A的行数;
IC是AA中每个元素对应的列号,长度为a。
所以将一个稀疏矩阵转为CSR表示,需要的空间为2*a+n+1个,同理CSC也是类似。
可以看出,为了达到压缩原始模型的目的,不仅需要在保持模型精度的同时,prune掉尽可能多的权值,也需要减少存储元素位置inde
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









