







本文主要介绍MongoDB备份的方式和恢复的办法。
MongoDB将所有的数据存在数据目录文件夹下,默认是C:\data\db,我们也可以通过dbpath来自由配置。如果只是简单的备份,我们只需要将文件夹复制即可。这种情况下我们需要关闭服务器,避免数据不同步。
MongoDB有三种方式在不需要关闭服务器的情况下就可以进行备份,分别是mongodump,主从复制以及副本集方式。
mongodump
mongodump是一种能够在运行时备份的方法,mongodump对运行的MongoDB做查询,然后将所查到的文档写入磁盘。因为mongodump是区别于MongoDB的客户端,所以在处理其他请求时也没有问题。
但是mongodump采用的是普通的查询机制,所以产生的备份不一定是服务器数据的实时快照。
下面我们来看看如何使用mongodump来备份数据库。
首先启动mongodump
效果如下:
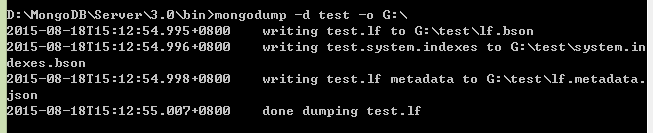
-d 指定数据库 -o 备份存放的位置
就可以到指定的位置找到备份的文件夹了:
打开就可以看到数据:

需要注意一点的是,mongodump备份时的查询会对其他客户端的性能产生影响。
更多的操作我们可以通过mongodump –help来查询
mongorestore
下面介绍如何用mongorestore来恢复数据。
mongorestore获取mongodump 的输出结果,并将备份的数据插入运行的MongoDB实例中。和mongodump一样,mongorestore也是一个独立的客户端:
使用该方法,将刚才备份的lf集合放到新的数据库testNew中去:

-d指定要恢复的数据库
–drop指在恢复前删除集合(若存在),否则数据就会与现有集合数据合并,可能会覆盖一些文档。
查看数据库:
show dbs
use testNew
db.lf.find()
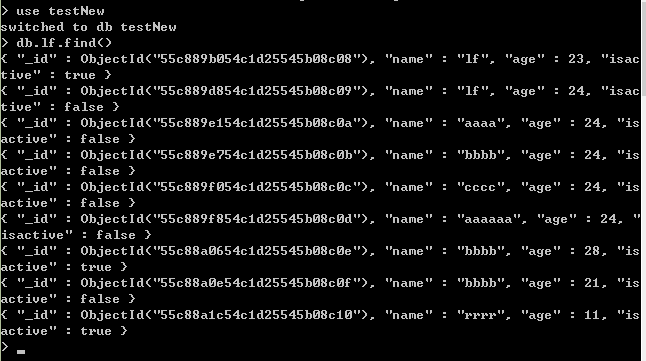
说明数据恢复成功
可以使用mongorestore –help获得帮助信息
需要注意的是,这两个命令操作的都是bson格式的数据,当数据量很大,超过几百G的时候,几乎是不能使用的,因为bson极其占用空间。
fsync锁
说到mongodump备份,就不能不提到fsync和锁了。我们刚刚提到过,使用mongodump备份可以不关闭服务器,但是却失去了获取实时数据视图的能力。而MongoDB的fsync命令能够在MongoDB运行时复制数据目录还不会损坏数据。
其工作原理就是强制命令服务器将所有缓存区写入磁盘,通过上锁阻止对数据库的进一步写入操作,直到释放锁为止。写入锁是让fsync在备份时发挥作用的关键。
在shell中,强制执行fsync并获得写入锁:
db.runCommand({"fsync":1,"lock":1})这时,数据目录的数据就是一致的,且为数据的实时快照.因为上了锁,可以安全的将数据目录副本作为备份。要是数据库运行在有快照功能的文件系统上时,比如LVM,EBS,这个很有用,因为拍个数据库目录的快照很快。
备份好了,解锁:
db.$cmd.sys.unlock.findOne()
db.currentOp()
运行db.currentOp()是为了确保已经解锁了(初次请求解锁会花点时间)。
有了fsync命令,就能非常灵活的备份,不用停掉服务器,也不用牺牲备份的实时性能。要付出的代价就是一些写入操作被暂时阻塞了。
主从复制
上面提到的备份方式很灵活,但是还是没有从服务器上备份好,当复制的方式运行MongoDB,前面的提到的备份技术就不仅能用在主服务器上,也可用在从服务器上。主从复制是MongoDB最常用的复制方式,这种方式很灵活,可以用于备份、故障恢复和读扩展等。
最基本的设置方式就是建立一个主节点和一个或多个从节点,每个从节点要知道主节点的地址。
我们通过mongod --master启动主服务器,通过运行mongod --slave --source master_address启动从服务器,其中master_address的主节点的地址。
这里我们用一台机器的不同端口来做测试:
首先,给主节点建立数据目录:
mongod --dbpath "D:\MongoDB\data\dbs " --port 10000 --master
创建成功后:
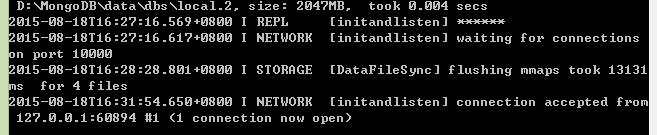
然后,我们设置从节点:
mongod --dbpath "D:\MongoDB\data\dbs\slave " --port 10000 --slave --source 127.0.0.1:10000 
创建后,其自动开始监听主节点的端口:
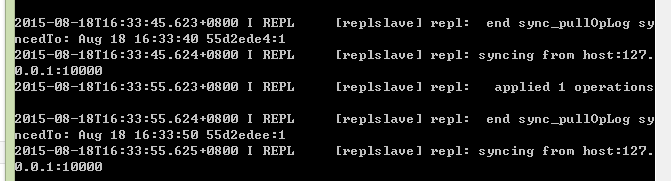
连接到主数据库:
db = connect(“127.0.0.1:10000/master”)
向主节点服务器添加数据:

再连接从节点,从节点查询数据:
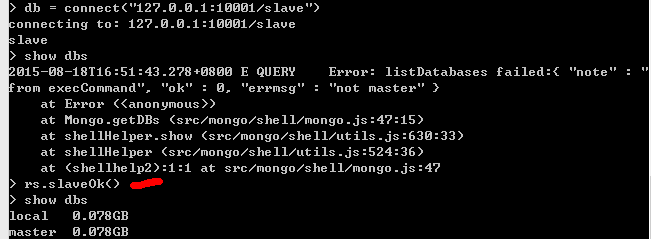
注意如果报错,需要使用rs.slaveOk()方法。
从节点中数据与主节点一致,说明备份成功。所有的从节点都会和主节点保持同步,一个集群中最好不要超过12个从节点。
选项
主从复制的过程中有一些配置选项:
–only
在从节点上指定只复制特定的某个数据库(默认是复制所有数据库)
–slavedelay
用在从节点上,当应用主节点的操作时,从节点增加延时复制(单位秒)。这样就能轻松设置延时从节点,这种节点对用户无意中删除重要文档或者插入垃圾数据等有防护作用,这些不良操作都会被复制到所有的从节点上,通过延时执行操作,可以有个恢复的时间差。
–fastsync
以主节点的数据快照为基础启动从节点。如果数据目录一开始是主节点的数据快照,从节点用这个选项启动要比做完整的同步快的多。
–autoresync
如果从节点与主节点不同步了,则自动重新同步
–oplogsize
主节点oplog的大小(单位MB)
副本集
最后来说说副本集,副本集就是有自动故障恢复功能的主从集群。副本集合主从集群的区别就是副本集中没有固定的主节点。
整个集群会选举出一个活跃节点,当其不能工作时,就会使其他备份节点变为活跃节点。也即是说,副本集总会有一个活跃节点(primary)和一个或多个备份节点(secondary)。
初始化
设置副本集比设置主从集群稍微复杂一点,因为它需要初始化。还得给副本集取一个名称,区别于其他副本集。这里取名lf。
首先启动一个节点:
mongod --dbpath "D:\MongoDB\Server\3.0\bin\master" --port 10000 --replSet lf/127.0.0.1:10001这里的–replSet的作用是让服务器知道这个lf副本集还有别的同伴位置在 lf/127.0.0.1:10001
接下来以同样的方式启动另一台:
mongod --dbpath "D:\MongoDB\Server\3.0\bin\slave" --port 10000 --replSet lf/127.0.0.1:10000如果想要添加第三台,两种方式:
mongod --dbpath " D:\MongoDB\Server\3.0\bin\slave 1" --port 10002
--replSet lf/127.0.0.1:10000
或者是
mongod --dbpath " D:\MongoDB\Server\3.0\bin\slave1" --port 10002
--replSet lf/127.0.0.1:10000,127.0.0.1:10001
两种方式都可以是因为副本集有自动检测功能,在其中指定单台服务器后,MongoDB就会自动搜索并连接其余的节点。
然后就是初始化操作了,在shell脚本中初始化副本集:
use admin
db.runCommand(
{
"replSetInitiate":
{
"_id":"lf",//副本集的名称
"members"://副本集中的服务器列表
[
{
"_id":1,//每个服务器的唯一id
"host":"127.0.0.1:10000"//指定服务器的主机
},
{
"_id":2,
"host":"127.0.0.1:10001"
}
]
}
}
)

初始化成功后,会处于活跃节点,我们可以通过rs.status()来查看各节点状态:
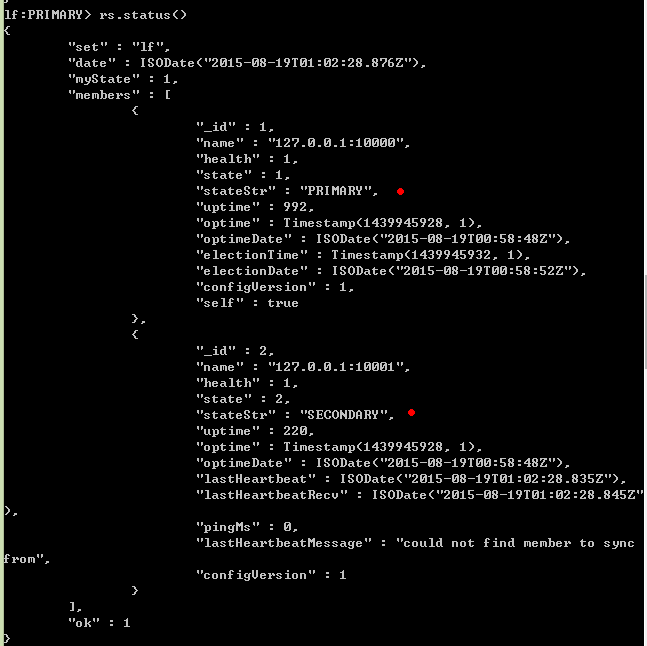
接下来我们在活跃节点中添加数据进行测试:
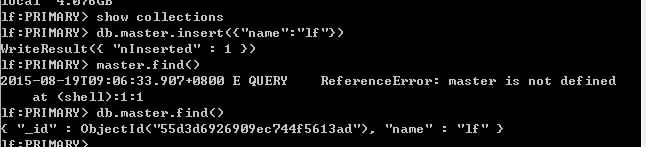
然后连接备份节点并进行数据查询:

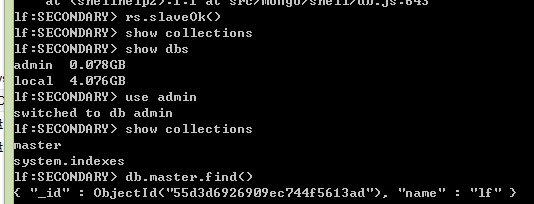
成功查询到数据,说明备份成功。
如果在备份节点查询,会出现
error: { “$err” : “not master and slaveok=false”, “code” : 13435 }错误.
执行如下语句:
db.getMongo().setSlaveOk()
节点
副本集的功能可不仅仅是备份这么简单噢。有几种不同类型的节点可以存在与副本集中:
1. standard 标准节点
这是常规节点,它存储一份完整的数据副本,参与选举投票有可能成为活跃节点
2. passive 被动结点
存储了完整的数据副本,参与投票,不能成为活跃节点
3. arbiter 仲裁者
仲裁者只能参与投票,不接收复制的数据,也不能成为活跃节点
我们可以在节点配置中修改priority键来设置节点的优先级别:
>members.push({"_id":3,"host":"127.0.0.1:10002","priority":40})默认优先级为1,可以是0-1000。
我们也可以通过arbiterOnly键来指定仲裁节点:
>members.push({"_id":4,"host":"127.0.0.1:10003","arbiterOnly":true})当活跃节点出现故障,其余节点会选举一个新的活跃节点,选举由任何非活跃节点发起。仲裁节点的加入是为了避免僵局,因为其自身不会参与竞选。新的活跃节点将是优先级最高的节点,优先级相同的,数据较新的节点获胜。
















 498
498

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











