







 本文总结了如何使用Python爬取二手商品信息并存储到MongoDB数据库中。内容包括创建Py文件抓取链接、另一个Py文件爬取商品详情,以及在MongoDB中自动创建数据库和collection的方法。爬取过程中涉及多种爬虫技巧,并展示了成功存储至数据库的结果。
本文总结了如何使用Python爬取二手商品信息并存储到MongoDB数据库中。内容包括创建Py文件抓取链接、另一个Py文件爬取商品详情,以及在MongoDB中自动创建数据库和collection的方法。爬取过程中涉及多种爬虫技巧,并展示了成功存储至数据库的结果。
其实很早就想知道如何将爬取到的数据存入数据库,并且实现前后台的交互功能,昨天刚刚看了一集关于爬数据并存数据的视频,今天,在这里总结一下~
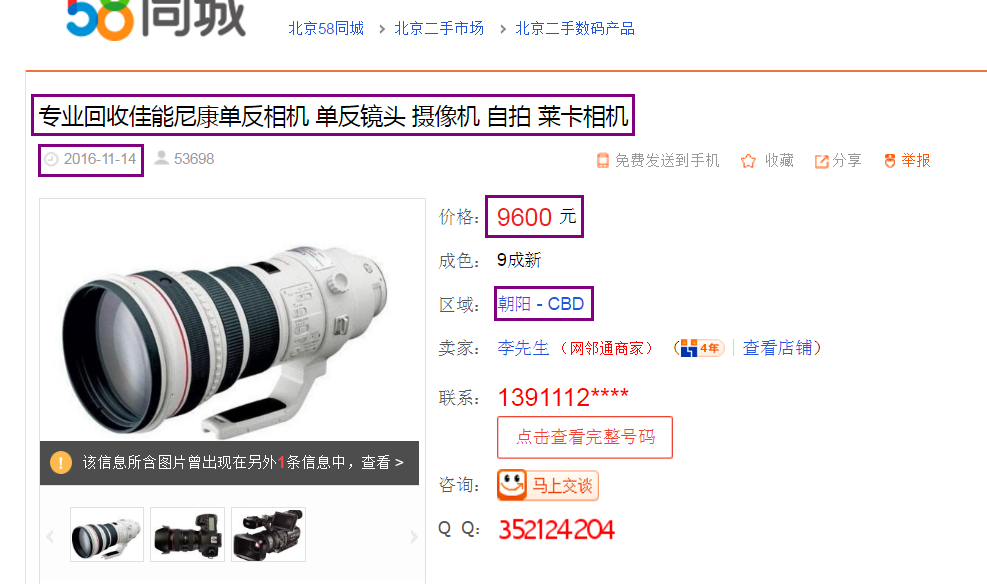
以下为最终所需要爬取的信息:
由于需要爬取所有的二手商品信息,所以以下内容也要爬取到:
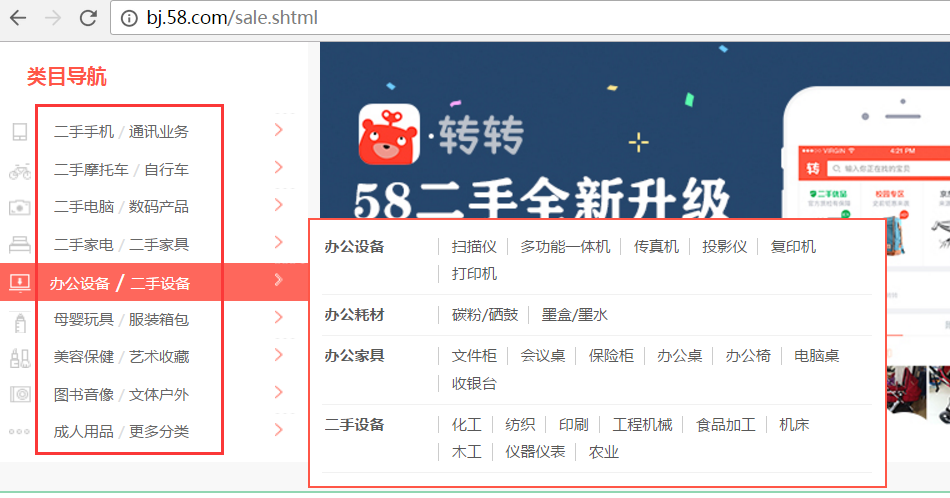
1.先写一个py文件,用于爬取上述图片类目导航的各个链接:
#-*-coding:utf-8-*-
from bs4 import BeautifulSoup
import requests
start_url = 'http://bj.58.com/sale.shtml'
url_host = 'http://bj.58.com'
def get_channel_urls(url):
wb_data = requests.get(start_url)
soup = BeautifulSoup(wb_data.text,'html.parser')
links = soup.select('ul.ym-submnu > li > b > a')
for link in links:
page_url = url_host + link.get('href')
print page_url
get_channel_urls(start_url)
#类目导航链接
channel_list = '''
http://bj.58.com/shouji/
http: 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 5391
5391

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









