






爬取的网站:http://blog.csdn.net/1024.html
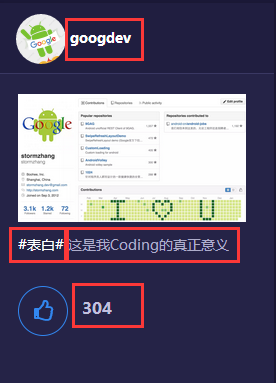
需要爬取的信息如图:
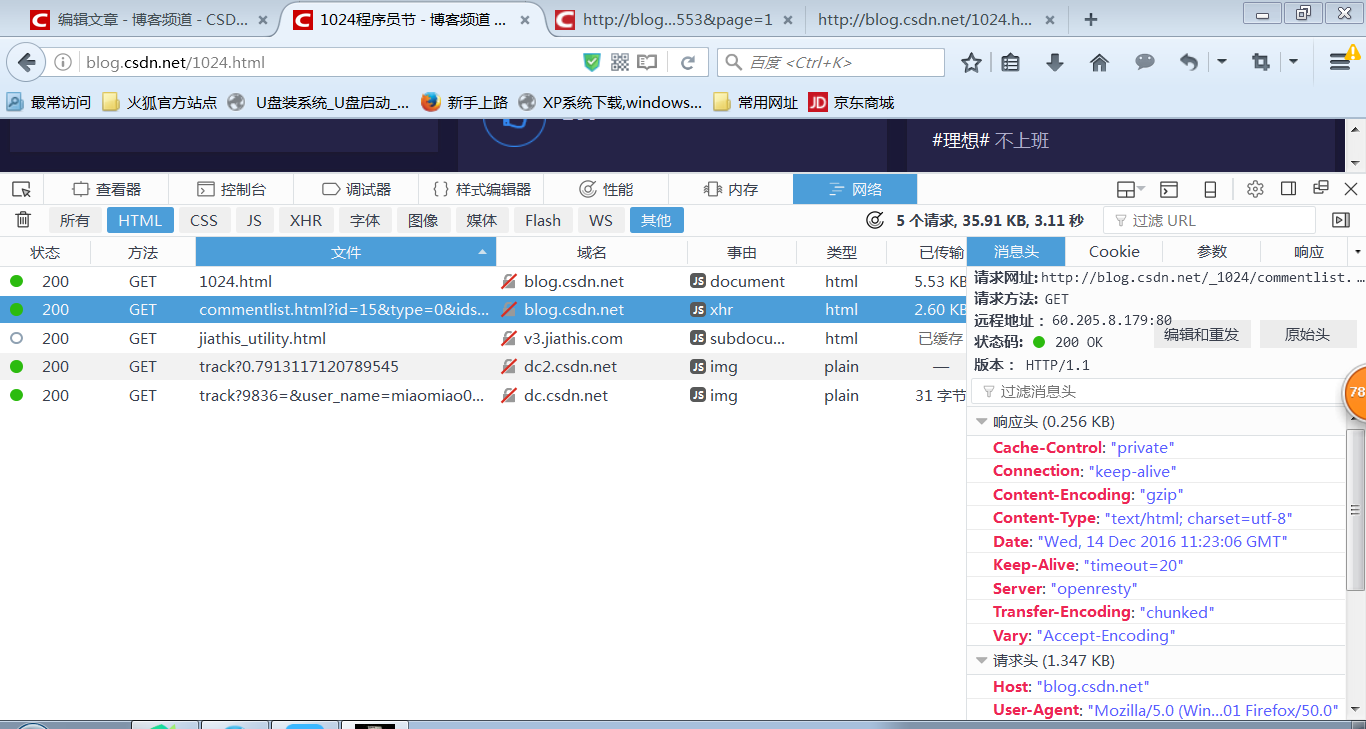
打开页面源代码,发现并没有需要的信息,想起之前爬过的以json格式加载的网易评论,便开始点击查看元素,筛选之后,知道只有蓝色标注那个网址有所需要的内容,如图。然后打开下图的源代码,神奇的东西出现了,在这里,我截取了一部分,如下图。

 本文讲述了如何爬取一个使用JSON格式动态加载内容的网页。通过查看元素并分析源代码,发现关键信息隐藏在特定URL中。内容主要位于<div class='grid' id=''>标签内,通过BeautifulSoup解析,并注意到页面参数'r'对结果无影响,可以忽略。提供了包含爬取逻辑的代码示例。
本文讲述了如何爬取一个使用JSON格式动态加载内容的网页。通过查看元素并分析源代码,发现关键信息隐藏在特定URL中。内容主要位于<div class='grid' id=''>标签内,通过BeautifulSoup解析,并注意到页面参数'r'对结果无影响,可以忽略。提供了包含爬取逻辑的代码示例。
爬取的网站:http://blog.csdn.net/1024.html
需要爬取的信息如图:
打开页面源代码,发现并没有需要的信息,想起之前爬过的以json格式加载的网易评论,便开始点击查看元素,筛选之后,知道只有蓝色标注那个网址有所需要的内容,如图。然后打开下图的源代码,神奇的东西出现了,在这里,我截取了一部分,如下图。
 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言




 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章





















