







本应该一个月前完成的总结,硬是拖到了现在,不能不说我的办事效率有多低下了。。。
前段时间学习了python爬虫的相关知识,爬虫的意思就是用机器代替人去访问链接,然后将页面中的东西爬下来,保存在本地,意思基本就是这样。
现在的爬虫基本上分为这两大类:
累积式抓取(cumulative crawling)和增量式抓取(incremental crawling)
累积式抓取是指从某一个时间点开始,通过遍历的方式抓取系统所能允许存储和处理的所有网页。在理想的软硬件环境 下,经过足够的运行时间,累积式抓取的策略可以保证抓取到相当规模的网页集合。但由于Web数据的动态特性,集合中网页的被抓取时间点是不同的,页面被更新的情况也不同,因此累积式抓取到的网页集合事实上并无法与真实环境中的网络数据保持一致。
增量式抓取是指在具有一定量规模的网络页面集合的基础上,采用更新数据的方式选取已有集合中的过时网页进行抓取,以保证所抓取到的数据与真实网络数据足够接近。进行增量式抓取的前提是,系统已经抓取了足够数量的网络页面,并具有这些页面被抓取的时间信息。
面向实际应用环境的网络蜘蛛设计中,通常既包括累积式抓取,也包括增量式抓取的策略。累积式抓取一般用于数据集合的整体建立或大规模更新阶段;而增量式抓取则主要针对数据集合的日常维护与即时更新。
python爬虫现在挺火的,所以有很多不错的框架可以去学习,其中优秀的一个框架就是Scrapy框架了,学习Scrapy爬虫框架的基本基础有:了解HTML/CSS、学习过基本的模块化编程、有一点python基础,最重要的就是持续不断的学习,有了以上基础,学习Scrapy就没有什么太大的问题了。
Scrapy框架,:中文翻译文档
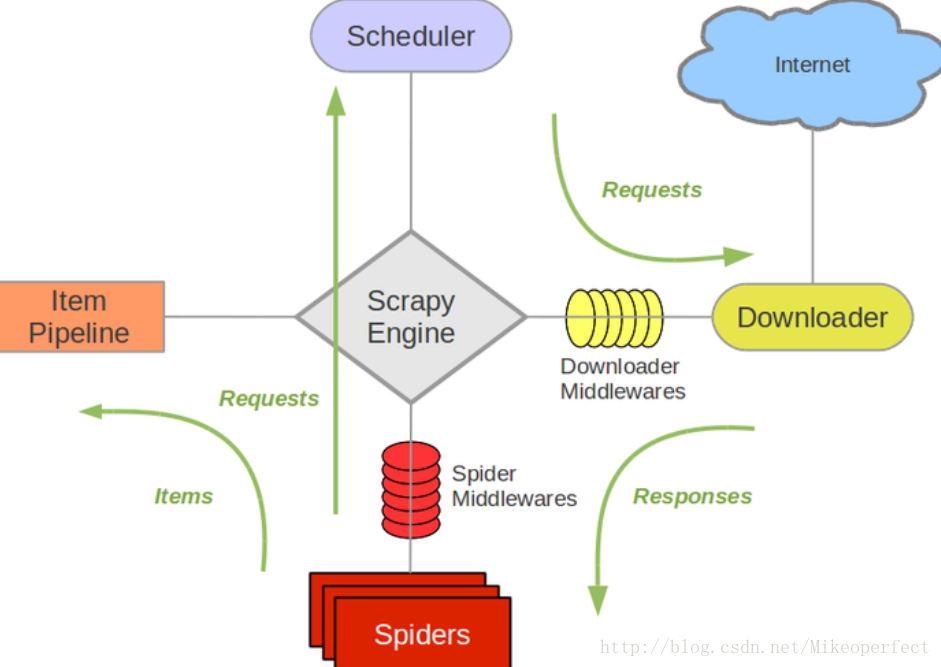
首先使用pip install scrapy 安装scrapy

一、创建一个工程和Spider模块
命令行中使用:
scrapy startproject < name>
scrapy genspider < name>
response类方法(url、status、headers、body、flags、request、copy)、
request类方法(url、method、header、body、meta、copy)
二、编写spider
支持(BeautifulSoup、lxml、re、xpath selector、css selector)
三、编写 Item pipelines
用于处理页面的存储等问题
四、修改settings.py
找到 Item pipelines 关键字,修改、ROBOT.txt=False等等
pipelines去重代码(利用set()):
from scrapy.exceptions import DropItem
def __init__(self):
self.ids_seen=set()
def process_item(self,item,spider):
if item['id'] in self.ids_seen:
raise DropItem("duplicate item found:%s"%item)
else:
self.ids_seen.add(item['id'])
return item代理(按实际情况来)
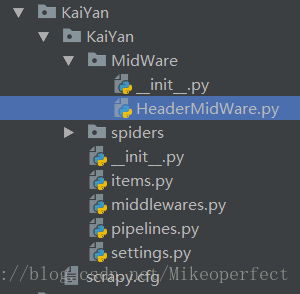
①首先按照上图中的目录新建相关文件(我的工程名为KaiYan)。
②在settings.py中找到DOWNLOADER_MIDDLEWARES
并修改为
DOWNLOADER_MIDDLEWARES = {
'KaiYan.MidWare.HeaderMidWare.ProcessHeaderMidware': 543,
}
,然后在settings.py末尾添加代理:
USER_AGENT_LIST = ['zspider/0.9-dev http://feedback.redkolibri.com/',
'Xaldon_WebSpider/2.0.b1',
'Mozilla/5.0 (Windows; U; Windows NT 5.1; en-US) Speedy Spider (http://www.entireweb.com/about/search_tech/speedy_spider/)',
'Mozilla/5.0 (compatible; Speedy Spider; http://www.entireweb.com/about/search_tech/speedy_spider/)',
'Speedy Spider (Entireweb; Beta/1.3; http://www.entireweb.com/about/search_tech/speedyspider/)',
'Speedy Spider (Entireweb; Beta/1.2; http://www.entireweb.com/about/search_tech/speedyspider/)',
'Speedy Spider (Entireweb; Beta/1.1; http://www.entireweb.com/about/search_tech/speedyspider/)',
'Speedy Spider (Entireweb; Beta/1.0; http://www.entireweb.com/about/search_tech/speedyspider/)',
'Speedy Spider (Beta/1.0; www.entireweb.com)',
'Speedy Spider (http://www.entireweb.com/about/search_tech/speedy_spider/)',
'Speedy Spider (http://www.entireweb.com/about/search_tech/speedyspider/)',
'Speedy Spider (http://www.entireweb.com)',
'Sosospider+(+http://help.soso.com/webspider.htm)',
'sogou spider',
'Nusearch Spider (www.nusearch.com)',
'nuSearch Spider (compatible; MSIE 4.01; Windows NT)',
'lmspider (lmspider@scansoft.com)',
'lmspider lmspider@scansoft.com',
'ldspider (http://code.google.com/p/ldspider/wiki/Robots)',
'iaskspider/2.0(+http://iask.com/help/help_index.html)',
'iaskspider',
'hl_ftien_spider_v1.1',
'hl_ftien_spider',
'FyberSpider (+http://www.fybersearch.com/fyberspider.php)',
'FyberSpider',
'everyfeed-spider/2.0 (http://www.everyfeed.com)',
'envolk[ITS]spider/1.6 (+http://www.envolk.com/envolkspider.html)',
'envolk[ITS]spider/1.6 ( http://www.envolk.com/envolkspider.html)',
'Baiduspider+(+http://www.baidu.com/search/spider_jp.html)',
'Baiduspider+(+http://www.baidu.com/search/spider.htm)',
'BaiDuSpider',
'Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0) AddSugarSpiderBot www.idealobserver.com',]③添加HeaderMidWare.py代码如下:
__author__ = 'KAI_YAN'
from scrapy.utils.project import get_project_settings
import random
settings = get_project_settings()
class ProcessHeaderMidware():
"""process request add request info"""
a=0
def process_request(self, request, spider):
ua = random.choice(settings.get('USER_AGENT_LIST'))
spider.logger.info(msg='now entring download midware')
if ua:
request.headers['User-Agent'] = ua
# Add desired logging message here.
self.a+=1
spider.logger.info(
'{} User-Agent is : {} {}'.format(self.a,request.headers.get('User-Agent'), request)
)
pass代理完成,配合spider下的脚本就可以实现代理功能了。
日志
python日志分为如下几个等级:
| 调试 | 记录 | 警告 | 致命 |
|---|---|---|---|
| DEBUG | INFO | ERROR | CRITICAL |
| logging.debug() | logging.info() | logging.error() | logging.critical() |
python的日志有向下兼容的特性,即警告会包含警告和致命,记录会包含记录、警告和致命。
禁用日志
logging.disable(logging.CRITICAL)
将日志写入文件中
import logging(或者from scrapy.utils.log import configure-logging)
logging.basicConfig(filename="....",level=logging.WARNING,format='%(asctime)s-%(levelname)s-%(message)s')调度器
sched模块
首先导入模块:
import sched
import time
一、生成调度器:
s=sched.scheduler(time.time,time.sleep)二、加入调度事件,
s.enterabs(time,priority=...,function,kwargs=....)
或者
s.enter(delay=........,priority=........,function,argument=.......)三、运行
s.run()
EG:
import os,time,sched
s=sched.scheduler(time.time,time.sleep)
def event(Time):
os.system("pthon ***.py")
s.enterabs(Time+1,event,(Time,))#(Time,)是元组形式,表示函数的参数,不加逗号则默认为字符了
if __name__=="__main__":
a=time.time()
s.enterabs(a,1,event,(a,))
s.run()threading模块
import threading,time
def test_func(msg1,msg2):
print("I'm test_func%s,%s"%(msg1,msg2))
timer_start()
def timer_start():
t=threading.Timer(1,test_func,("msg1","msg2"))
t.start()
if __name__=="__main__":
timer_start()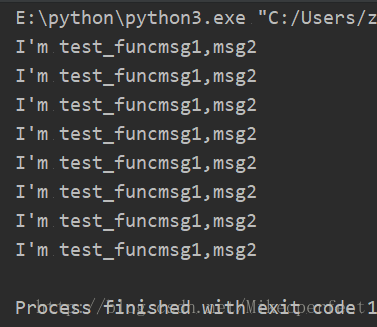
小结
个人感觉这次的 框架没有总结到位,尤其是一些重要的东西,仅仅只是停留在了知识的表面,没有来得及去深入探讨,估计是时间线拉的太长的缘故,以后争取今日事今日毕吧














 3302
3302











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









