







1. 为啥需要学习Scrapy?
-
爬虫必备的技术 面试...
-
让爬虫程序更快更强大
2. 什么是Scrapy?
异步爬虫框架
Scrapy基于Python开发的框架,用来抓取网站并从页面中提取结构化数据,也是当前Python爬虫生态最流行爬虫框架,架构清晰,可扩展性强,可以灵活高效完成各种爬虫的需求
3. 如何学习Scrapy?
4.Scrapy工作流程
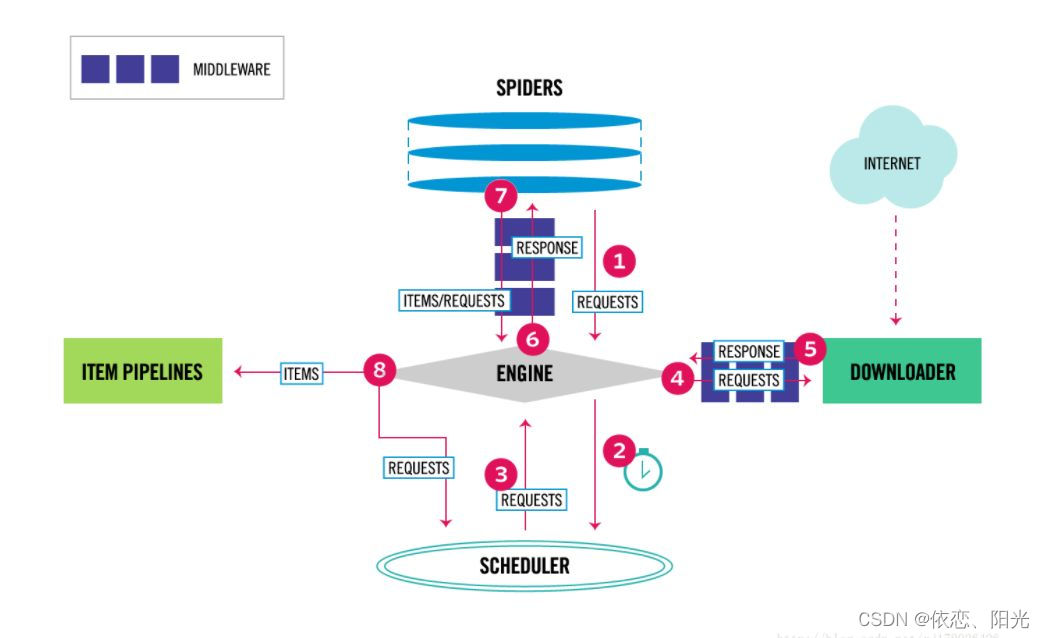
5. Scrapy快速入门
- 安装
pip install scrapy
2.创建项目
scrapy startproject my_scrapy
cd my_scrapy
scrapy genspider spider www.baidu.com
3.运行项目
scrapy crawl spider

功能描述:
- scrapy.cfg:scrapy项⽬的配置⽂件 其中定义项⽬配置路径,部署信息等
- item.py:定义了Item数据结构 所有的item的定义放在这⾥
import scrapy """ Item是保存爬取数据容器 定义爬取结果的数据结构 """ class MyScrapyItem(scrapy.Item): # define the fields for your item here like: # name = scrapy.Field() # 名言 text = scrapy.Field() # 名人 author = scrapy.Field() # 标签 tags = scrapy.Field() - middlewares.py:中间件定义
- pipelines.py:定义Item Pipeline 的实现 数据保存
- settings.py:定义项⽬的全局配置
- spiders⽂件夹: 包含是⼀个个spider的实现 每个spider对应⼀个Python⽂件
import scrapy from my_scrapy.my_scrapy.items import MyScrapyItem class SpiderSpider(scrapy.Spider): name = 'spider' # Spider名称 allowed_domains = ['quotes.toscrape.com'] # 网站域名 start_urls = ['http://quotes.toscrape.com/',] # 初始request请求 num = 1 def parse(self, response): """ 解析返回响应,提取数据或者进一步生成要处理的请求 :param response: 返回响应 :return: """ quotes = response.css('.quote') for quote in quotes: # 旧方法 # extract_first() 返回一条数据 # extract() 返回多条数据 # text = quote.css('span.text::text').extract_first() # author = quote.css('small.anthor::text').extract_first() # tags = quote.css('div.tags a.tag::text').extract() # 新方法 # get() 返回一条数据 # get_all() 返回多条数据 # CSS # text = quote.css('span.text::text').get() # author = quote.css('small.author::text').get() # tags = quote.css('div.tags a.tag::text').getall() # Xpath # 创建字段对象 item = MyScrapyItem() item['text'] = quote.xpath('./span[@class="text"]/text()').get() item['author'] = quote.xpath('.//small[@class="author"]/text()').get() item['tags'] = quote.xpath('.//div[@class="tags"]/a[@class="tag"]/text()').getall() # 返回管道中 yield item next = response.css('.pager .next a::attr("href")').extract_first() url = response.urljoin(next) # 递归爬取 yield scrapy.Request(url,callback=self.parse) # 另一种方法 # yield from response.follow_all(response.css('.pager .next a::attr("href")'),callback=self.parse)
6.补充:创建run方法
目的:为了不用每一次都在终端运行项目
# 可以在pycharm内显示运行项目的内容
from scrapy import cmdline
cmdline.execute('scrapy crawl spider'.split())















 879
879











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











