







MySQL索引基数
前提
- 存储引擎:InnoDB 存储引擎
- 索引数据结构:B+Tree
概念
- 索引基数(cardinality):索引中不重复的索引值的数量;
- 例如,某个数据列包含值1、3、7、4、7、3,那么它的基数就是4。
- 索引基数相对于数据表行数较高(也就是说,列中包含很多不同的值,重复的值很少)的时候,它的工作效果最好。
- 如果某数据列含有很多不同的年龄,索引会很快地分辨数据行。
- 如果某个数据列用于记录性别(只有”M”和”F”两种值),那么索引的用处就不大。
- 如果值出现的几率几乎相等,那么无论搜索哪个值都可能得到一半的数据行。在这些情况下,最好根本不要使用索引,因为查询优化器发现某个值出现在表的数据行中的百分比很高的时候,它一般会忽略索引,进行全表扫描。惯用的百分比界线是”30%”。
- 常用操作:
- 查看语句:
show index from table ;Cardinality列中展示的即为该索引对应的索引基数,是估计值,不是准确值;见示例1,示例2
- 为何是估计值而不是准确值?
- 在生产环境中,数据表的更新操作非常频繁,每一次的数据更新操作,都会更新索引文件中的数据,而如果每次都要进行一次该索引中不同索引值的统计会增加系统压力
- 索引基数的初始值
- 新表中添加索引:索引基数为0,见示例1
- 旧表中添加索引:索引基数为当前表中数据总数,见示例2
- 索引基数的计算方式
- 采用采样的方法,默认情况下InnoDB会对8个叶子节点的信息进行统计,过程如下:
- 取得B+Tree所有叶子节点的数量,记为A
- 随机取得B+Tree索引的8个叶子节点。统计每个叶子节点的不同记录的条数,即为P1,P2,…,P8
- 根据采样计算出Cardinality的预估值:Cardinality=(P1+P2+…+P8)*A/8
- 采用采样的方法,默认情况下InnoDB会对8个叶子节点的信息进行统计,过程如下:
- 为何是估计值而不是准确值?
- 更新语句:
ANALYZE TABLE
- 何时更新索引基数的值?
- 表中的1/16数据已发生变化:上一次统计Cardinality信息后,表中1/16数据已发生变化,则会触发Cardinality统计
- start_modified_counter>2 000 000 000:为对表中某一行数据频繁进行更新操作,实际数据条数并没有发生变化,则InnoDB会生成start_modified_counter计数器,用来统计操作次数,如果次数大于2 000 000 000,则会触发Cardinality统计
- show index、ANALYZE TABLE、SHOW TABLE STATUS以及访问INFOMATION_SCHEMA架构下的TABLES或STATISTICS会导致Cardinality的统计
- 何时更新索引基数的值?
- 查看语句:
// 示例1:新创建表t_student ,新增索引 idx_name
mysql> CREATE TABLE `t_student` (
`id` int(10) unsigned NOT NULL AUTO_INCREMENT COMMENT '主键',
`name` varchar(32) NOT NULL DEFAULT '' COMMENT '姓名',
`age` int(3) unsigned NOT NULL DEFAULT '0' COMMENT '年龄',
PRIMARY KEY (`id`),
KEY `idx_name` (`name`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
mysql> alter table t_student add index idx_name(`name`);
Query OK, 0 rows affected
Records: 0 Duplicates: 0 Warnings: 0

// 示例2:新创建表t_person ,初始化数据后,新增索引 idx_name
mysql>CREATE TABLE `t_person` (
`id` int(10) unsigned NOT NULL AUTO_INCREMENT,
`name` varchar(32) NOT NULL DEFAULT '' COMMENT '姓名',
`sex` tinyint(1) unsigned NOT NULL COMMENT '姓名',
`age` int(3) unsigned NOT NULL COMMENT '年龄',
PRIMARY KEY (`id`),
KEY `idx_name` (`name`) USING BTREE,
KEY `idx_age` (`age`) USING BTREE
) ENGINE=InnoDB AUTO_INCREMENT=7 DEFAULT CHARSET=utf8;
// 手动初始化数据
mysql> select * from t_person ;
+----+------+-----+-----+
| id | name | sex | age |
+----+------+-----+-----+
| 1 | 张三 | 0 | 10 |
| 2 | 李四 | 0 | 20 |
| 3 | 王五 | 1 | 10 |
| 4 | 张三 | 1 | 20 |
| 5 | 赵六 | 1 | 30 |
| 6 | 高七 | 0 | 30 |
+----+------+-----+-----+
6 rows in set

show index from table结果中各列的含义
| 列名称 | 含义 |
|---|---|
| table | 表名 |
| non_unique | 如果索引不能包括重复词,则为0。如果可以,则为1。 |
| key_name | 索引名 |
| seq_in_index | 索引中的列序列号,从1开始 |
| column_name | 列名 |
| collation | 列以什么方式存储在索引中。在MySQLSHOW INDEX语法中,有值’A’(升序)或NULL(无分类) |
| cardinality | 索引基数 |
| sub_part | 如果列只是被部分地编入索引,则为被编入索引的字符的数目。如果整列被编入索引,则为NULL。 |
| packed | 指示关键字如何被压缩。如果没有被压缩,则为NULL。 |
| null | 如果列含有NULL,则含有YES。如果没有,则该列含有NO。 |
| index_type | 所用索引存储方法(BTREE, FULLTEXT, HASH, RTREE) |
应用
DQL语句中索引选择的判断
- 在InnoDB存储引擎中,每个表中可以添加多个索引,若一个DQL中涉及多个索引,只会选择最优的一个
- 索引的选择性的策略,选择性为某一索引列不重复的值的比例;选择性大小的公式:S = C / #T
- S(Selectivity)为选择性,C(Cardinality)为基数,即不重复的索引值,#T为记录总数。
选择性越大意味着不重复的值的比例越高,对于B树索引而言,期望与不重复值比例越高的列作为B树索引的索引列,B树索引便能有效地过滤掉大部分数据行,从而确定具体的数据行为止或者将数据行局限在一个可以接受的范围之内
考虑到索引的顺序,这里提出一个通用的策略,如果没有特别的理由(如排序,索引列出现频率等等),在大部分情况下将选择性最大的列排在索引列的最前面最好的。理由:将选择性最大的索引列排在最前面可以有效过滤掉最多的数据行。
由于排在最前面,所以每一个涉及到这个索引列的查询也能在扫描第一个索引列的时候过滤掉大多数行,从而将剩余的少数行留给后续的索引进行过滤。总而言之,这样一来,相关的查询在通常情况下几乎总是能够访问最少的数据行,从而提升数据库的索引性能。
-若字段类型为(BLOB、TEXT、VARCHAR),考虑前缀索引的选择性。如果前缀索引的选择性足够高,也可以将此索引排在索引列的最开始处。选择一个合适的前缀索长度,在这里可以选择计算不同前缀的选择性,选择一个比较接近于整列值索引选择性的前缀长度即可。而不必将对整个内容进行索引
- 示例 3:
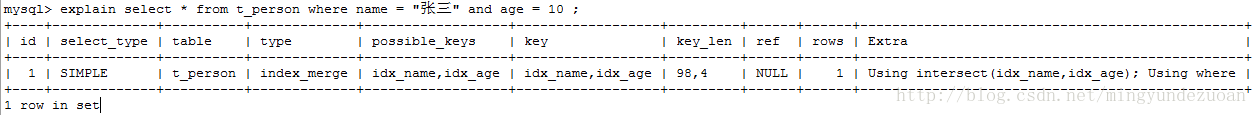
从初始化数据中得出,共6条数据,
idx_name : 张三共两条,索引列中选中的数据与表中总数据比例: 2 / 6
idx_age : 10 共两条,索引列中选中的数据与表中总数据比例:2 / 6
两者相同,故,explain 的结果中 key 列中两个索引均使用到示例 4 :
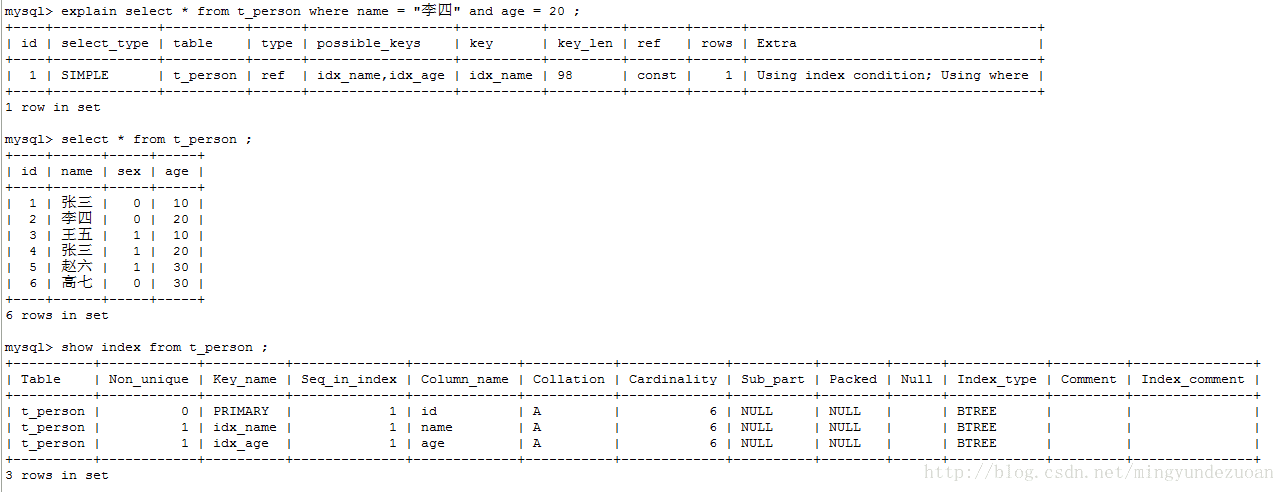
- 从初始化数据中得出,共6条数据,
idx_name : 李四共1条,索引列中选中的数据与表中总数据比例: 1 / 6
idx_age : 20 共两条,索引列中选中的数据与表中总数据比例:2 / 6
Explain 执行结果中 Extra列中有Using index,这就代表这个查询是一个覆盖查询,完全使用了索引来查询数据
索引列中该索引值的数量占比越大,相对的该列的不重复的索引值的数量就越低,即索引基数就越低,所以选择了 idx_name
结论
- 二叉树索引本来最适合的就是点查询,和小范围的range查询,当预估返回的数据量超过一定比例( 貌似当预估的查询量达到总量的30% )的时候,再根据索引一条一条去查就慢了,反而不如全表扫描快了。Mysql有自己内部自动优化机制,但有些自动优化机制可能不是最优的。这时候就需要人工去干预。比如长期不优化表,Mysql判断出索引不优,就会不使用索引。有时候就要人工强制使用真正高效的索引(FORCE INDEX)
- 性别、状态等区分度不大的字段不添加单列索引
- 作为组合索引的最左条件
- 不添加索引,但放在查询条件的最左侧,过滤一部分数据后,再进行最优的索引选择的















 1093
1093

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









