







本次搭建大概过程:
- 配置linux环境
- 安装jdk
- 安装hadoop2.4.1
- 配置ssh免登陆
首先配置一台。在安装好所有的步骤之后,在可以备份扩展机date的时候,克隆一台母机备份。以便扩展(不能直接克隆dateNode机器稍加改造使用,否则会出现:你用该dateNode扩展的所有机器都只能被成功使用一台,其他的莫名其妙的就掉线)
准备linux环境
配置vm虚拟机
点击VMware快捷方式,右键打开文件所在位置 -> 双击vmnetcfg.exe -> VMnet1 host-only ->修改subnet ip 设置网段:192.168.1.0 子网掩码:255.255.255.0 -> apply -> ok
回到windows –> 打开网络和共享中心 -> 更改适配器设置 -> 右键VMnet1 -> 属性 -> 双击IPv4 -> 设置windows的IP:192.168.1.100 子网掩码:255.255.255.0 -> 点击确定
在虚拟软件上 –My Computer -> 选中虚拟机 -> 右键 -> settings -> network adapter -> host only -> ok
对于vm的配置和网络设置,百度有很多,这里只做参考
注:以下有关ip地址的配置,都是与这里的配置有关,需要根据你当前机器所配置的ip为准!
os说明
使用的是centOs
uname -a
Linux had01 2.6.32-358.el6.i686 #1 SMP Thu Feb 21 21:50:49 UTC 2013 i686 i686 i386 GNU/Linux
新建了一个用户组和一个用户名:用户组:hadoop 用户名:hadoop
修改主机名称
修改主机名(每台机器都要修改该名称,方便记忆标识和hosts地址映射)
vim /etc/sysconfig/network
NETWORKING=yes
HOSTNAME=daimayoudu ###
修改IP地址
两种方式:
第一种:通过Linux图形界面进行修改(强烈推荐)
进入Linux图形界面 -> 右键点击右上方的两个小电脑 -> 点击Edit connections -> 选中当前网络(当前系统使用的那一个) -> 点击edit按钮 -> 选择IPv4 -> method选择为manual -> 点击add按钮 -> 添加IP:192.168.1.101 子网掩码:255.255.255.0 网关:192.168.1.1 -> apply
第二种:修改配置文件方式(屌丝程序猿专用)
vim /etc/sysconfig/network-scripts/ifcfg-eth0
DEVICE="eth0"
BOOTPROTO="static" ###
HWADDR="00:0C:29:3C:BF:E7"
IPV6INIT="yes"
NM_CONTROLLED="yes"
ONBOOT="yes"
TYPE="Ethernet"
UUID="ce22eeca-ecde-4536-8cc2-ef0dc36d4a8c"
IPADDR="192.168.1.101" ###
NETMASK="255.255.255.0" ###
GATEWAY="192.168.1.1" ###
修改主机名和IP的映射关系
vim /etc/hosts
192.168.1.101 had01
192.168.1.102 had01
##这里可以多配置几台,加入你打算配置5台来组成分布式集群,这里就多写隐身几台
更改完之后运行:sudo hostname itcast #主机名称,再exit重新登录就会发现[hadoop@localhost ~]$ @localhost 变成了主机名称
(如果没有变化,在外部工具类中,那么就退出重新连接)或则重启服务器
关闭防火墙
查看防火墙状态
service iptables status
#关闭防火墙
service iptables stop
#查看防火墙开机启动状态
chkconfig iptables --list
#关闭防火墙开机启动
chkconfig iptables off
把当前用户添加sudo
运行hadoop可以有权限运行root的权限命令(本人菜鸟,不知道这个具体有啥作用,配置之后的确不配置要好用得多,不用重复输入密码获取root权限)
vi /etc/sudoers
## Allow root to run any commands anywhere
root ALL=(ALL) ALL
hadoop ALL=(ALL) ALL
(该项配置大概在第27行)
重启Linux
reboot
安装JDK
使用SecureCRT在windows中连接服务器操作
上传jdk
上传alt+p 后出现sftp窗口,然后put d:\xxx\yy\ll\jdk-7u_65-i585.tar.gz
或则使用 filezilla 工具上传,或则直接在图形界面拖拽,解压
解压jdk
/home/hadoop/app 我们把所有的软件都安装在app下
#创建文件夹
mkdir /home/hadoop/app
#解压
tar -zxvf jdk-7u55-linux-i586.tar.gz -C /home/hadoop/app
将java添加到环境变量中
vim /etc/profile
#在文件最后添加
export JAVA_HOME=/home/hadoop/app/jdk1.7.0_65
export PATH=$PATH:$JAVA_HOME/bin
(这里也可以把hadoop的环境变量也配置了,以后安装hadoop的时候,就不需要再配置这里了)
-------------------
export JAVA_HOME=/home/hadoop/app/jdk1.7.0_65
export HADOOP_HOME=/home/hadoop/app/hadoop-2.4.1
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
-------------------
#刷新配置
source /etc/profile
以上是环境搭建好了,可以备份一台母机,万一玩废了,还可以重新来过
克隆一台服务器,备份!
安装hadoop2.4.1
先上传hadoop的安装包到服务器上去,解压到/home/hadoop/app目录下
注意:hadoop2.x的配置文件$HADOOP_HOME/etc/hadoop
伪分布式需要修改5个配置文件
配置文件中有默认的的配置参数,可以在官网查看详细信息,这里指修改,必须设置的参数,简单化让程序先运行起来
(rm -rf xxx/sss 删除文件或则文件夹)
需要先进入到hadoop安装目录下的 etc/hadoop/ 中
hadoop-env.sh
vim hadoop-env.sh
#第27行,修改成vim /etc/profile 中配置的java——home路径
export JAVA_HOME=/home/hadoop/app/jdk1.7.0_65
core-site.xml
<!-- 指定HADOOP所使用的文件系统schema(URI),HDFS的老大(NameNode)的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://had01:9000</value>
</property>
<!-- 指定hadoop运行时产生文件的存储目录:要定义在当前用于的权限目录中 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/hadoop-2.4.1/tmp</value>
</property>hdfs-site.xml
hdfs-default.xml
<!-- 指定HDFS副本的数量:上传文件备份的副本个数 -->
<property>
<name>dfs.replication</name>
<value>2</value>
</property>mapred-site.xml
没有该文件的话,该目录下提供了一个模版文件,我们把该文件直接修改名称
mv mapred-site.xml.template mapred-site.xml
<!-- 指定mr运行在yarn上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>yarn-site.xml
<!-- 指定YARN的老大(ResourceManager)的地址 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>had01</value>
</property>
<!-- reducer获取数据的方式 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>将hadoop添加到环境变量
vim /etc/proflie
export JAVA_HOME=/home/hadoop/app/jdk1.7.0_65
export HADOOP_HOME=/home/hadoop/app/hadoop-2.4.1
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
source /etc/profile #刷新资源
**最开始我们增加jdk环境变量的时候一次增加了hadoop环境变量,这一步就可以不增加了**
这里可以copy配置好的hadoop到dateNode节点了
或则把已经配置好的hadoop目录备份一份,如果操作了以下的,再复制到其他节点上就会出现各种错误;
复制文件到远程主机:
scp -r hadoop-2.4.1/ hadoop@had002:/home/hadoop/app/
然后修改had002的主机名称,ip地址(之前备份的母机在这里就显示出作用了)其他的不用修改,重启等待
扩展datenode
以下一大段话是出了问题的总结,可以先不看。跟着笔记走就行了
以后要扩展datenode: 只需要备份一台,配置好的jdk环境变量、和hadoop环境变量(以后只要复制hadoop就不需要再修改环境变量了)、防火墙关闭、把当前用户的hadoop组加入root
(sudo命令那个vi /etc/sudoers配置文件中)即可,直接在虚拟机克隆,然后把ip固定、hosts配置列表从master中复制一份或则手动输入关联,主机名称修改下
再在master上启动hadoop hdfs服务即可
如果出现了:http://master:50070/中看不到你所配置的datenode其他节点。则就是这里扩展(复制)的时候有问题。
重新弄一个os系统。修改主机名称、关闭防火墙、当前组加入sudo配置文件、固定id、hosts列表映射、jdk,hadoop环境变量、再从其他已运行的datenode中把hadoop文件夹复制到统一的目录下即可。
格式化namenode
(是对namenode进行初始化,也就是在had01上面执行该命令)
hdfs namenode -format (hadoop namenode -format)
格式化命令,只是在hadoop的tem目录下生成对应的节点目录,如果遇到启动有问题的,可以尝试删除tem目录下的 nameNode 和 dateNode目录,重新格式化
启动hadoop
启动之前最好先把免验证登录设置了
自己在配置的过程中,就出现了手动输入密码,但是还卡着不动,配置了免验证密码登录之后,再启动就正常了
配置需要自动启动的data节点
(cd etc/hadoop/):vi slaves
把需要启动dataNode进程机器的主机名或则ip地址加入该文件列表,每行一个。
sbin/start-dfs.sh
YARN(资源调度集群框架,服务于mapreduce等运算框架)
sbin/start-yarn.sh
验证是否启动成功
使用jps命令验证
27408 NameNode
28218 Jps
27643 SecondaryNameNode
28066 NodeManager
27803 ResourceManager
27512 DataNode
http://192.168.1.101:50070 (HDFS管理界面,启动hdfs)
http://192.168.1.101:8088 (MR管理界面,启动YARN才能打开该页面)
配置ssh免登陆
要全部配置了免密码登录,连master(本机)也要配置后,才会正常的被启动(实测是这样不会出现什么异常),本机配置之后,不需要输入密码
生成ssh免登陆密钥
进入到我的home目录
cd ~/.ssh
ssh-keygen -t rsa
(四个回车)执行完这个命令后,会生成两个文件id_rsa(私钥)、id_rsa.pub(公钥)
将公钥拷贝到要免密登陆的目标机器上(比如:要在100,上免密码登录101,那么就在100上面操作,然后复制到101上面)
(也就是说:如果要在master上面免密码启动其他date节点:就要在master上面操作,然后复制到其他节点上面)
ssh-copy-id localhost #localhost 是主机名称或则ip地址
ssh密钥验证原理图
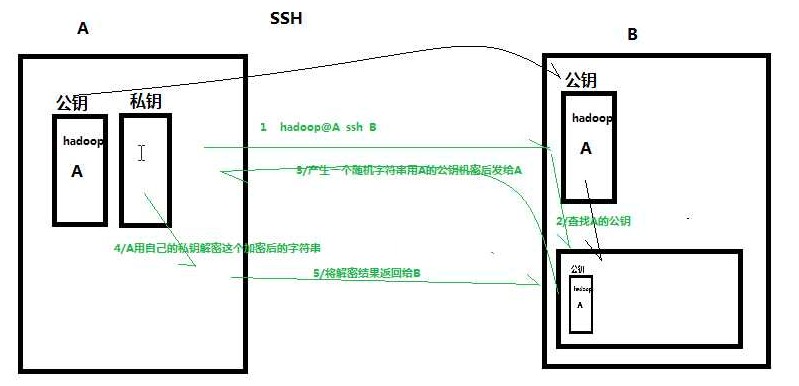
使用HDFS shell测试效果
- 查看帮助
hadoop fs -help //cmd - 上传
hadoop fs -put (linux上文件) (hdfs上的路径)
hadoop fs -put /home/hadoop/insall/Ghost_XP_IE8_CJ_V2015.02.iso hdfs://had01:9000/Ghost_XP_IE8_CJ_V2015.02.iso - 查看文件内容
hadoop fs -cat (hdfs上的路径) - 查看文件列表
hadoop fs -ls / - 下载文件
hadoop fs -get (hdfs上的路径) (linux上文件) 删除文件
hadoop dfs -rm xxx删除目录与目录下所有文件
hadoop dfs -rmr /user/cl/temp
修改linux启动模式
把图形界面修改为字符界面,节省内存
vi /etc/inittab
id:5:initdefault 改为id:3:initdefault
HDFSAPI入门
package cn.hdfs.util;
import java.io.FileOutputStream;
import java.io.IOException;
import java.net.URI;
import java.net.URISyntaxException;
import java.util.ArrayList;
import java.util.List;
import org.apache.commons.io.IOUtils;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FileStatus;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.junit.Before;
import org.junit.Test;
/**
* @ClassName: HdfsUtil
* @Description: hdfs 常用api
* @author zq
*
* @version V0.1
* @date 2015年4月9日 上午10:20:56
*/
public class HdfsUtil {
private FileSystem fi = null;
@Before
public void before() throws IOException, InterruptedException, URISyntaxException {
Configuration conf = new Configuration();
String uriStr = "hdfs://192.168.184.141:9000";
conf.set("fs.defaultFS", uriStr);
// FileSystem fi = FileSystem.get(conf);
FileSystem fi = FileSystem.get(new URI(uriStr), conf, "hadoop");
this.fi = fi;
}
/**
*
* @Title: upLoad
* @Description: 上传文件
*
* <pre>
* org.apache.hadoop.security.AccessControlException: Permission denied: user=zq, access=WRITE, inode="/":hadoop:supergroup:drwxr-xr-x
* 如果抛出以上异常:当前操作的用户没有权限,因为我们部署hadoop是用hadoop用户,而在windows中测试的时候,如果没有指定用户,则以当前系统用户作为访问者
* FileSystem fi = FileSystem.get(new URI(uriStr), conf, "hadoop"); 获取文件系统操作的时候,指定用户
* </pre>
* @throws IOException
* @return void
* @version V0.1
* @createDate 2015年4月9日 上午10:32:59
* @updateDate 2015年4月9日 上午10:32:59
*/
@Test
public void upLoad() throws IOException {
String folder = "C:/Users/zq/Desktop/music/";
String fileName = "data.txt";
fi.copyFromLocalFile(new Path(folder, fileName), new Path("/wordCount/data/", fileName));
}
/**
*
* @Title: downLoad
* @Description: 从hdfs下载文件
* @throws IOException
* @return void
* @version V0.1
* @createDate 2015年4月9日 上午10:39:50
* @updateDate 2015年4月9日 上午10:39:50
*/
@Test
public void downLoad() throws IOException {
String fileName = "dj - 不了了之.mp3";
fi.copyToLocalFile(new Path("/music/", fileName), new Path("/home/hadoop/Desktop/", fileName));
}
/**
* 创建文件夹
*
* @throws IOException
* @throws IllegalArgumentException
*/
@Test
public void mkdir() throws IllegalArgumentException, IOException {
String folder = "/music/mimi";
boolean result = fi.mkdirs(new Path(folder));
System.out.println("makdirs is " + result);
}
/**
* 遍历hdfs上指定路径的文件信息,包括文件夹目录
*
* @throws IOException
*/
@Test
public void showList() throws IOException {
Path path = new Path("/music");
List<String> list = getFile(path, fi);
for (String name : list) {
System.out.println(name);
}
}
public static List<String> getFile(Path path, FileSystem fs) throws IOException {
List<String> result = new ArrayList<String>();
FileStatus[] fileStatus = fs.listStatus(path);
for (int i = 0; i < fileStatus.length; i++) {
FileStatus fss = fileStatus[i];
if (fss.isDirectory()) { // is Directory
result.add(fss.getPath().toString());
Path p = new Path(fss.getPath().toString());
List<String> arr = getFile(p, fs);
result.addAll(arr);
} else {
result.add(fss.getPath().toString());
}
}
return result;
}
/**
* 在hdfs上修改文件名
*
* @throws IOException
*/
@Test
public void rename() throws IOException {
String fileName = "dj - 不了了之.mp3";
boolean result = fi.rename(new Path("/music/", fileName), new Path("/music/", "不了了之(dj).mp3"));
System.out.println("file rename is " + result);
}
/**
* 在hdfs删除指定文件
*
* @throws IOException
*/
@Test
public void delete() throws IOException {
String fileName = "dj - 不了了之.mp3";
fi.delete(new Path("/", fileName), false); //如果文件是一个目录,是否递归删除所有文件
}
/**
* 用于跟踪hdfs下载文件的源码流程
*
* @param args
* @throws IOException
*/
@Test
public void test() throws IOException {
Configuration conf = new Configuration();
conf.set("fs.defaultFS", "hdfs://192.168.184.141:9000");
// 应该根据给定的参数构造出一个具体实现类的实例对象 : DistributedFileSystem
// 重点跟踪源码中是如何选择特定的实现类来构造实例,以及这个实例对象中都包含一些什么样的关键(成员)
//底层是使用common的RPC实现的远程通信调用技术
FileSystem fs = FileSystem.get(conf);
FSDataInputStream inputStream = fs.open(new Path("/music/不了了之(dj).mp3"));
FileOutputStream outputStream = new FileOutputStream("C:/Users/zq/Desktop/music/不了了之(dj)1.mp3");
IOUtils.copy(inputStream, outputStream);
}
}















 3443
3443

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









