







Pycharm 5.0.3
IDE Pycharm
BeautifulSoup 4.5.0
如何在Pycharm下安装BeautifulSoup请看
致力于打造最详细的Requests使用(不定期补充)
还有强烈推荐@崔庆才–Python爬虫利器二之Beautiful Soup的用法不能更详细的用法介绍
都说BeautifulSoup是利器,那就记录下bs的学习过程和代码示例
从以前的几篇博客上来看,我基本没有使用BeautifulSoup来进行对内容的抓取,可能我绝大多数对内容抓取的都是动态网页,而采用的selenium+phantomjs组合,抓的时候也是xpath定位元素的,接下来的一段时间,复习一下bs,正好有空也把正则捡捡,暑假到家屏幕只有一个了,不适合写工程类项目了,所以还是捡捡复习复习基础吧,就酱!
牛刀时间
我们进行网页查看元素分析时候总能看到这样的结构
这个网页结构我就不进行展开了,反正我也不太清楚,哈哈,我负责的还是对数据进行采集,知道怎么运作,哪些元素,tag就行了点击了解html结构
这里我还是对一个具体的小爬虫进行入手,爬自己学校的博士生导师,爬了两层。
BTW,我实在忍不住吐槽,这网页做的是什么玩意啊,规范性去哪了!!!爬起来好费劲啊。先上几幅图,按理来说,每个老师的介绍板块应该是一样的,也应该是由一个人写的脚本,但是!这尼玛随便找了三个人我就看到三种形式,我真是醉了。。。
有这样的–比较标准的

有这样的,我快控制不住体内的洪荒之力了。。。。
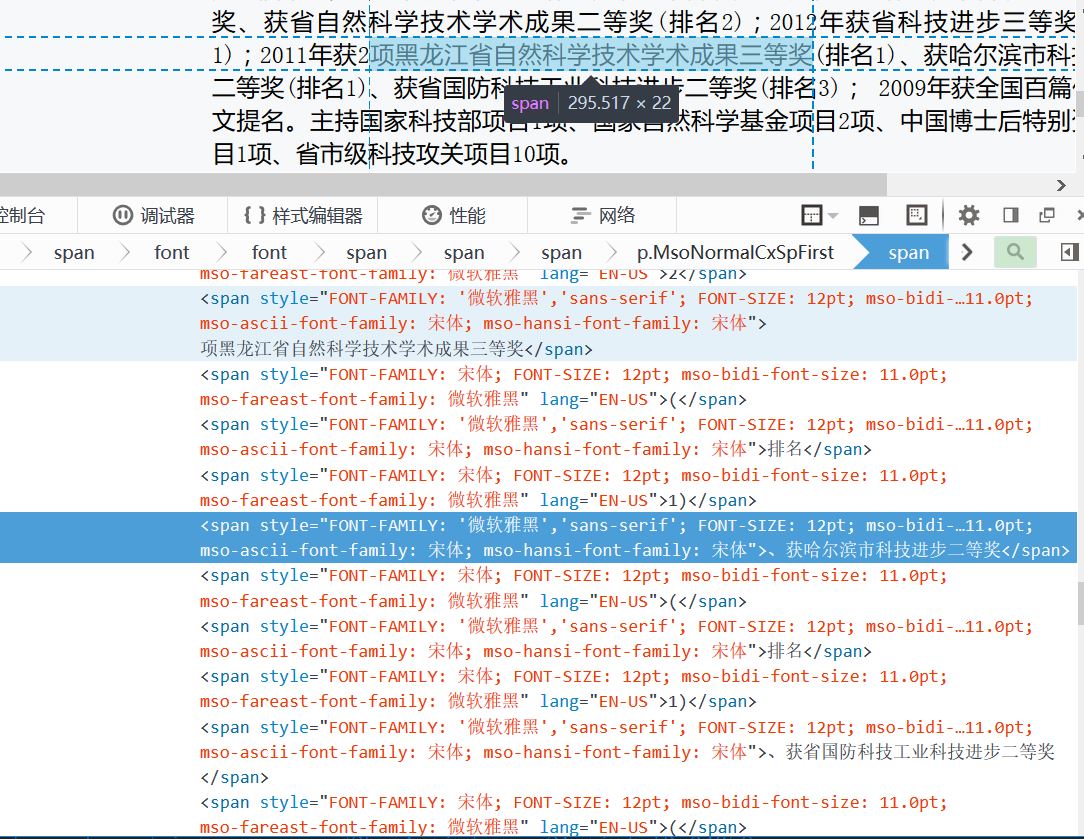
还有直接这样的。。。所有内容都写在一个标签里,哥哥,你累不累啊,我爬也爬好累,都快一个个点开看各自布局了!那爬虫还有什么意义!

程序构思
1.对首页老师名字和第二层url进行抓取,url可以采用正则的方式,然后再过滤一下。当然你也可以采用获取标签属性的方法进行对url的收集
2.对1抓取的url进行下一层的导师具体内容的抓取,这是第二层,直接调用就好
3.循环输出
上代码
# -*- coding: utf-8 -*-
import requests
from bs4 import BeautifulSoup
import re
def getDetail(getURL):
html_detail = requests.get(getURL)
html_detail.encoding='gb2312'#规定编码类型
bs_getDetail = BeautifulSoup(html_detail.text,'lxml')
for column in range(10):#防止采集不全数据
try:
print bs_getDetail.findAll("p",{"class":"MsoNormal"})[column].get_text()
except:
pass
url = 'http://icec.hrbeu.edu.cn/xintongxueyuan/ShowArticle.asp?ArticleID=138877'
html = requests.get(url)
html.encoding='gbk'#规定编码类型,和第二层的网页不是一个编码
bs = BeautifulSoup(html.text,'lxml')#至于为什么要加'lxml',这是IDE提醒我添加上的,无伤大雅咯
url_f=[]#创建个列表用来存第二层url
for i in range(13,44):
url_f.append(bs.findAll("a",{"href":re.compile("/xintongxueyuan/ShowArticle.asp\?ArticleID=[0-9]+")})[i])
#跳过中间的(校内),校内这几个字也是同样的结构,只有这样去除
if i < 35:
print bs.findAll("td",{"class":"STYLE3"})[i-12].get_text()
if i >=35:
print bs.findAll("td",{"class":"STYLE3"})[i-11].get_text()
getURL= u'http://icec.hrbeu.edu.cn'+re.findall(r"/xintongxueyuan/ShowArticle.asp\?ArticleID=[0-9]+",str(url_f[i-13]))[0]
print getURL
getDetail(getURL)#调用函数
print '#--------------------------------------------------------------#'实现效果如下,绝大部分是正常的;
刁 鸣
http://icec.hrbeu.edu.cn/xintongxueyuan/ShowArticle.asp?ArticleID=137277
刁 鸣,男,1960年出生,工学硕士,教授,工学硕士、博士生导师,巴拉巴拉巴拉。。。
研究方向:宽带信号检测、处理与识别,通信信号处理
个人成果:先后承担和参与省部级科研项目10余项,发表学术论文100余篇,巴拉巴拉巴拉。。。
联系方式:diaoming@hrbeu.edu.cn
#--------------------------------------------------------------#
也有不正常的。。。
司伟建
http://icec.hrbeu.edu.cn/xintongxueyuan/ShowArticle.asp?ArticleID=65700
司伟建,男,1971年生,工学博士,研究员,博士生导师,巴拉巴拉巴拉。。。
招生专业:信息与通信工程(博士、硕士)、电子与通信工程
研究方向:宽带信号检测、处理与识别;高精度无源测向技术;谱估计
个人成果:在国内外核心期刊、会议发表学术论文70余篇,巴拉巴拉巴拉。。。
#--------------------------------------------------------------#绝大多数是正常的,有几个例外,我估计不是一个人写的脚本,不然差别不会差那么多,以司伟建导师为例,为什么缺少了联系方式了呢?点开后才发现,他的联系方式根本不在我的规则里,如下图,别的老师都是在MsoNormal中,他偏偏在结尾p标签处,我真是醉了。。。。
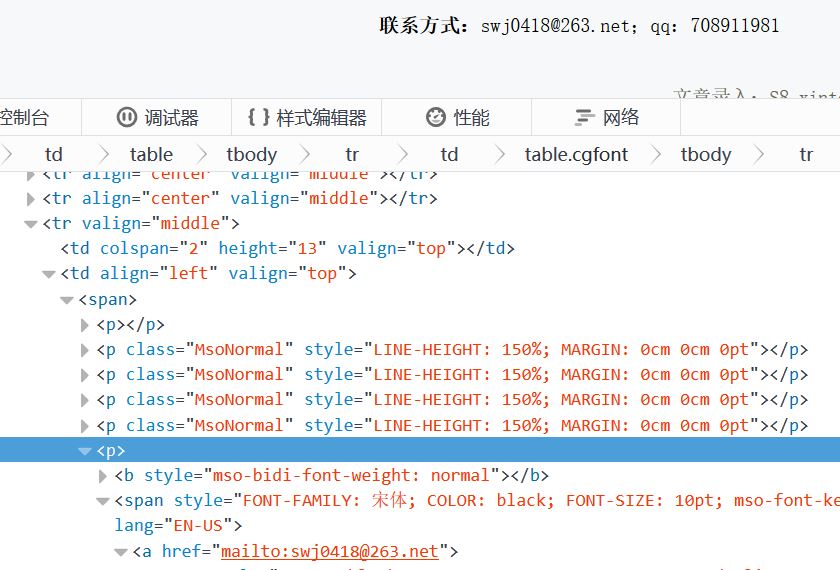
这里就不在做具体的讨论,我选择的项目根本不够规范,练习的BS4也就那么几句,不规范的网页对死板的代码来说杀伤力太大,我已经加了几个防范措施,比如try语句,每次每个老师的MsoNormal选项个数总是不一样,try多几次,抓不到就pass,还有校内这几个字,规范和老师ID一样,我真无语,还得中间靠if来去掉,如果靠正则,估计又有点麻烦。
遇到问题
1.requests编码问题
1.解决方案,通过点击网页才发祥,第一页的编码方式和第二层的编码方式不一样,看来踩点还是没踩好,直接犯错,具体解决方法和urllib的方式不太一样,具体可看致力于打造最详细的Requests使用(不定期补充)里面的最后一节,关于requests的一些编码问题。
2.BeautifulSoup和Re的一些组合问题
2.以bs.findAll("a",{"href":re.compile("/xintongxueyuan/ShowArticle.asp\?ArticleID=[0-9]+")})为例,我们用的最多的莫过于findAll,它的实际用法是
findAll(tag,attributes,recursive,text,limit,keywords)
我们基本是用前面两个参数就够了,前面那就话的意思是,先找到a标签,然后参数是href,里面的值我们用正则表达式来进行筛选,注意这里要的是编译好的正则
3.关于正则的一点使用
3.可以采用编译好的正则来直接findall,就像这两个,是等价的
getURL= u'http://icec.hrbeu.edu.cn'+re.findall(r"/xintongxueyuan/ShowArticle.asp\?ArticleID=[0-9]+",str(url_f[i-13]))[0]和下面这个编译好的再进行处理
p = r"/xintongxueyuan/ShowArticle.asp\?ArticleID=[0-9]+"
patten = re.compile(p)
getURL= u'http://icec.hrbeu.edu.cn'+patten.findall(str(url_f[i-13]))[0]多用几次,加深印象!
致谢
@崔庆才–Python爬虫利器二之Beautiful Soup的用法
常用html元素总结包括基本结构、文档类型、头部、主体等等
@MrLevo520–致力于打造最详细的Requests使用(不定期补充)














 987
987











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









