







一、总体思想—由粗到精的定位
- 利用人脸检测器(haar特征或者其它的detection方法),把人脸部位的图片(bbox)裁剪出来,送入CNN
- 好处:外界背景因素(eg:风景、身体、头发)的干扰减小了,有利于提高精度。
- detection: 采用CNN定位出5个特征点的bbox精度要比直接采用人脸检测器的效果好。
- 利用level1的CNN粗定位出5个特征点的坐标
- 利用level2和level3的CNN对这5个特征点的坐标进行精调
二、级联CNN的具体实现
1、网络总体结构
- 网络的总体结构如下图1所示:
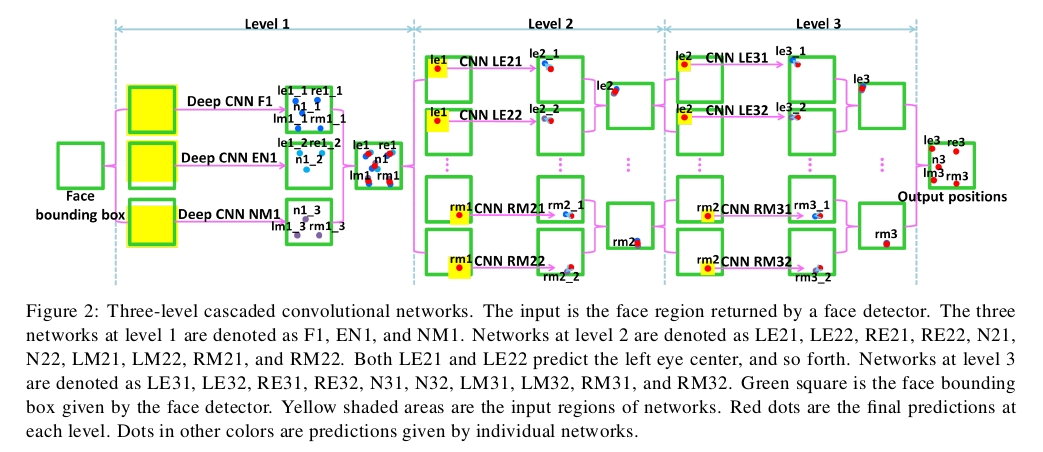
图1
图中的黄色区域是每层检测器的扫描区域。 F1、EN1和NM1首先是一层粗的定位,后面再通过level2和level3实现更为精细的位置修正(怎么体现级联及精调的?)
答:预测时以前一级预测的点为中心进行padding(padding的大小见下面的3、每个level输入区域的区别),这样就体现了3个level是怎样级联及精调的了。
然而, 实际训练时它是通过landmark(ground truth) random shift(0.05/0.02)来模拟level1/2阶段预测出来的特征点然后再通过padding实现剪裁的,所以,实际上训练时23个model之间是相互独立的,并没有体现级联的关系。Note: 感觉这样训练出的模型不会有太大的误差,比直接用预测的点做训练效果要好,因为预测的点有的误差会比较大,这样误差就会一级一级的传递下去,从而导致训练出来的模型效果差。
具体shift的细节:
def randomShift(landmarkGt, shift):
diff = np.random.rand(5, 2)
diff = (2*diff - 1) * shift #(-1,1)*shift,landmarkGt已经归一化了
landmarkP = landmarkGt + diff
return landmarkP- 预测过程
- 每个level使用多个CNN来预测一个点,然后把重复预测的特征点通过位置平均形成最终预测,这样有利于提高网络的稳定性、防止预测特征点的位置偏差过大,提高精度。但是,为什么代码作者说只使用F1预测的结果要比使用F1/EN1/NM1三者做平均效果好一点呢?
- level2和level3的每个CNN的输出是两个神经元(因为一个CNN,只定位1个特征点坐标,一个特征点坐标,包含了(x,y)两维)。
2、网络参数的选择
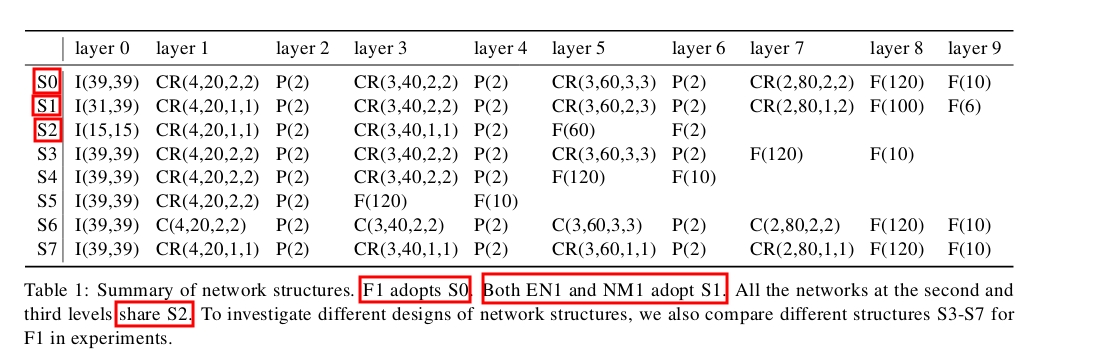
- 输入层用I(h,w)表示,其中,h和w分别表示输入区域的的高度和宽度。带绝对值矫正的卷积层表示为:CR(s,n,p,q), 不带绝对值矫正的卷积层表示为:C(s,n,p,q),其中,s表示卷积核的边长大小,n表示fliter的个数,p和q表示权重共享参数,每个卷积层的map被均匀的分成p*q个区域,每个区域内权值是局部共享的。传统的卷积网络可以看作p=q=1, fliter stride 在x, y 方向均为1。池化层采用max pooling, stride为2,pooling区域不重合,结果乘以一个增益系数g,加上一个偏置b。
论文作者分析了3个网络选择的重要因素,S3—S7为对比实验:
- 第一级的网络必须要深。level 1是粗定位,输入的图片区域比较大,特征提取难度比较大,所以我们设计这一层级网络的时候,需要保证网络的深度(9层),更深的结构有利于形成全局的高级特征。level2和level3输入的图片区域比较小,特征提取的难度也比较小,因此采用了浅层网络(6层)。(没咋看明白?局部特征的训练只需要浅层的网络即可?)
- 对卷积层上的神经元,采用双曲正切激活函数后加绝对值校正(tanh+abs),能有效提高效果。(代码作者采用的是Relu激活函数)
- 卷积层采用local sharing weights 有助于level 1的精度提高。(代码作者采用的是传统的卷积方法)
For networks whose inputs contain different semantic regions, locally sharing weights at high layers is more effective for learning different high-level features, e.g., eyes, nose, and mouth.
3、每个level输入区域的区别
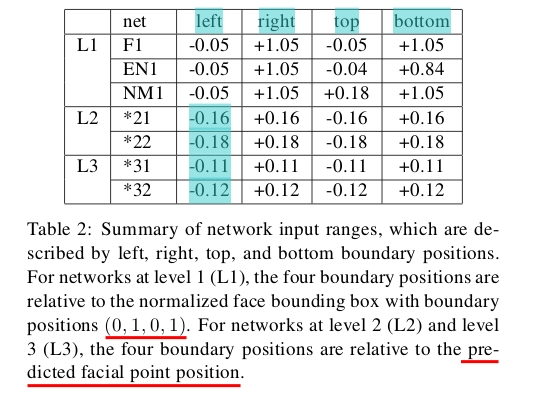
F1输入整个脸,输出5个点,EN1输入人脸的上部和中部,输出两个眼睛和鼻子3个点,NM1输入中部和底部,输出鼻子和左右嘴3个点。(具体输入图像的大小见上面的Table1)
Note: 从Table2可以看出论文作者在level1阶段对bbox进行了放大,个人感觉如果detection做的比较准,这里放大检测框就没有多大的必要了(而且他只检测5个关键点),您觉得呢?
LE21和LE22都是用来预测左眼中心的位置,那他们的区别在哪呢?
答:区别在于剪裁区域的大小,从Table2可以清晰的看出。level2和level3使用相同的网络结构来预测同一个点,那他们的区别在哪?
答:在这两级,我们用两个不同大小的区域来预测每个点,第三层的剪裁区域比第二层的小。每一级的网络精度输入如Table2所示。Note: 上述level2和level3的之间以及其自身内部两个CNN预测同一个点的区别都是在于patch大小不同,为什么要这样处理呢?有什么好处呢?(论文作者:这两层输入区域的大小是被严格限制的,因为局部特征有时是模糊和不可信的)
4、每个level的输入和输出
level1
face detection——face bbox——灰度图——resize(F,EN,NM)——输入到level1的CNN中进行训练
输入:原始图片(包含bbox和landmark),如下图2所示。
输出:预测出的5个特征点的坐标,如下图3所示(蓝色的点)。
图2
图3level2
输入:以level1阶段预测出的特征点为中心进行剪裁(正方形的框,是否可以换成矩形框(包含整个眼睛的局部特征)???),实际训练时它是通过landmark(ground truth) random shift 0.05来模拟level1阶段预测出来的特征点,然后再通过padding实现剪裁的。),得到包含5个特征点的patch,输入到CNN中去,如下图4所示。
输出:修正后的5个特征点坐标。level3
输入:以level2阶段预测出的特征点为中心,然后用一个比level2阶段更小的bbox进行剪裁(实际训练时它是通过landmark(ground truth) random shift 0.02来模拟level2阶段预测出来的特征点,然后再通过padding实现剪裁的。),得到包含5个特征点的patch,输入到CNN中去。
输出:修正后的5个特征点坐标。


三、模型表示、训练及评价
- 模型表示
不同模型的主要区别在于决策函数和损失函数以及参数学习算法的差异 。
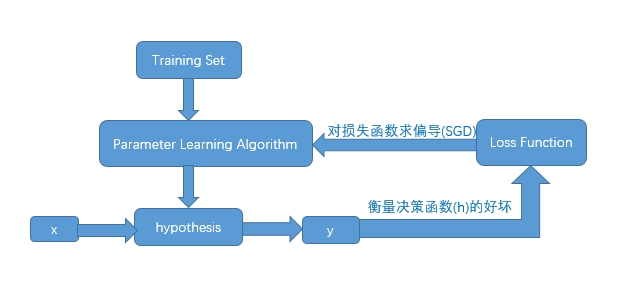
根据任务,可以把要学习的决策函数表示为:
其中,X是输入的人脸图像,W是我们要学习的参数,
Y∈[(x1,y1),(x2,y2),(x3,y3),(x4,y4),(x5,y5)]
是我们需要检测的人脸特征点的坐标位置。
这是一个典型的回归问题,可以采用最简单的均方误差损失函数(MSE),然后用机器学习方法学习这个模型。
其中 (xi,yi) 为预测的位置, (x′i,y′i) 为标注的人脸特征点的位置。
模型训练
- level1:输入经过resize后的bbox,并通过镜像和旋转增强数据后开始训练。
- level2和level3:首先通过landmark(ground truth) random shift来模拟level1/2阶段预测出来的特征点,然后再通过padding实现剪裁,最后经过resize输入CNN进行训练。level2在水平和竖直最大的shift为0.05,level3为0.02,这个距离是以bounding box的大小为基准的。
- 参数学习算法:mini-batch SGD
- 参数初始化方法:Xavier
- 学习率的设置:inv
模型评价
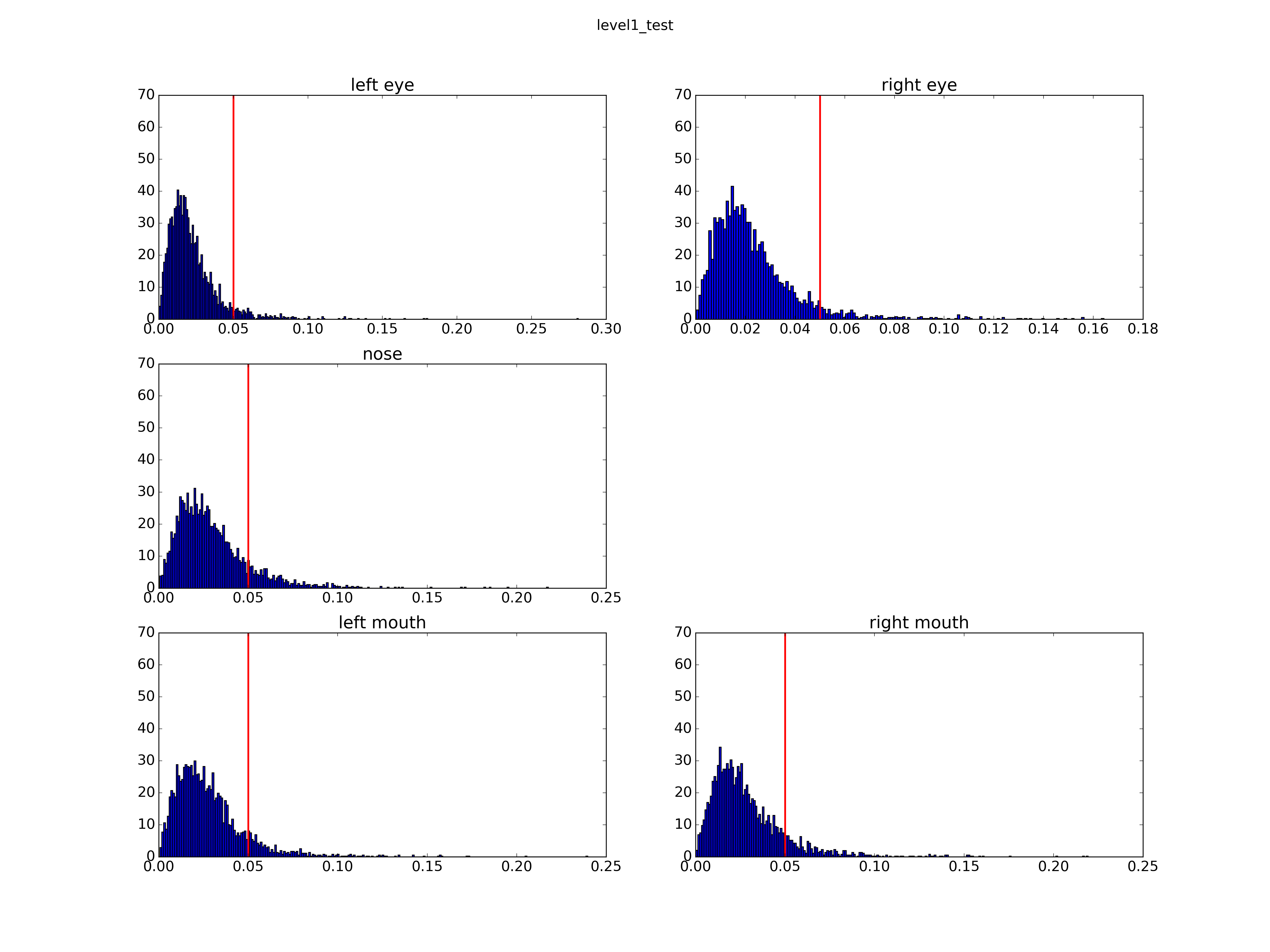
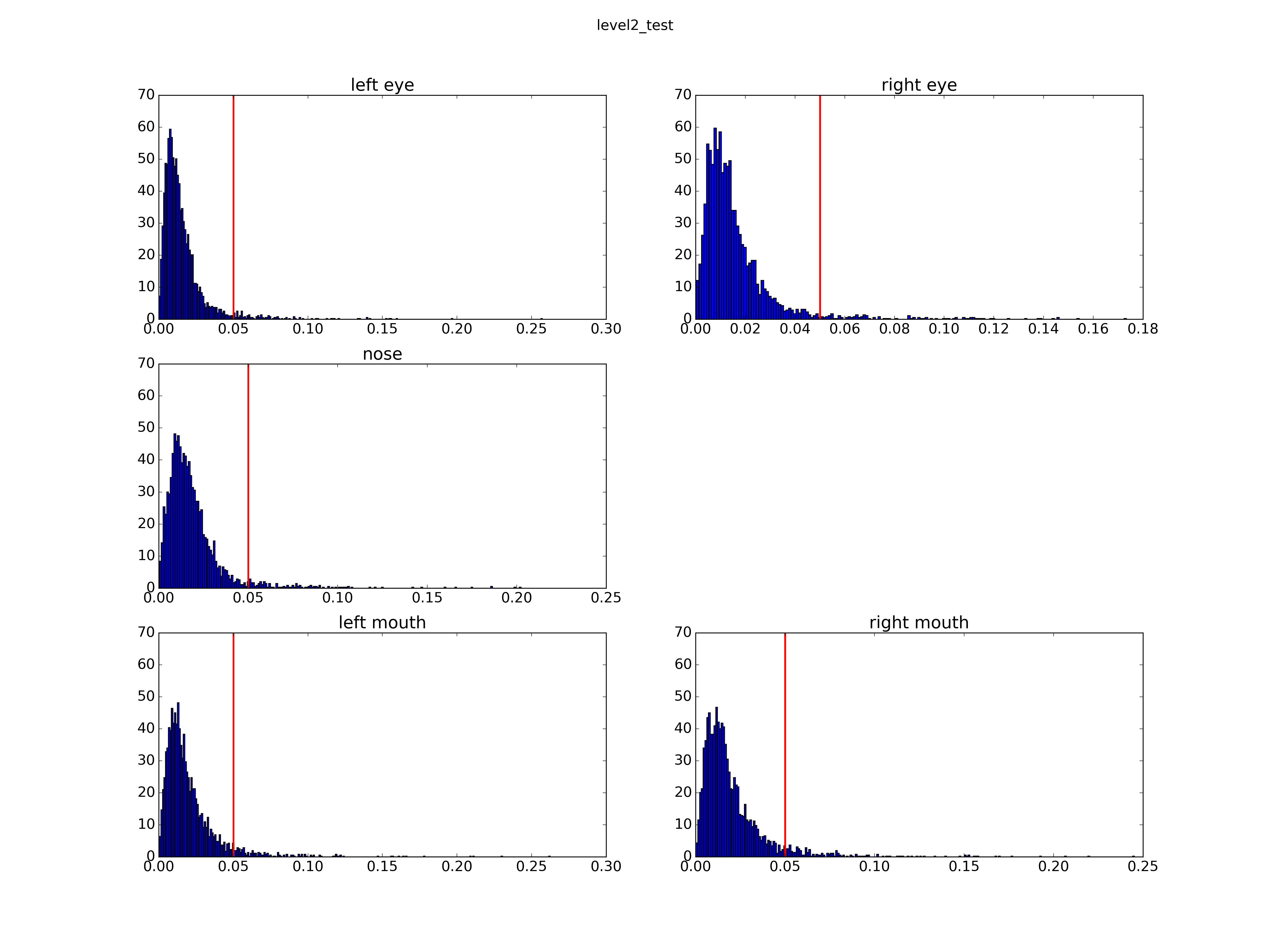
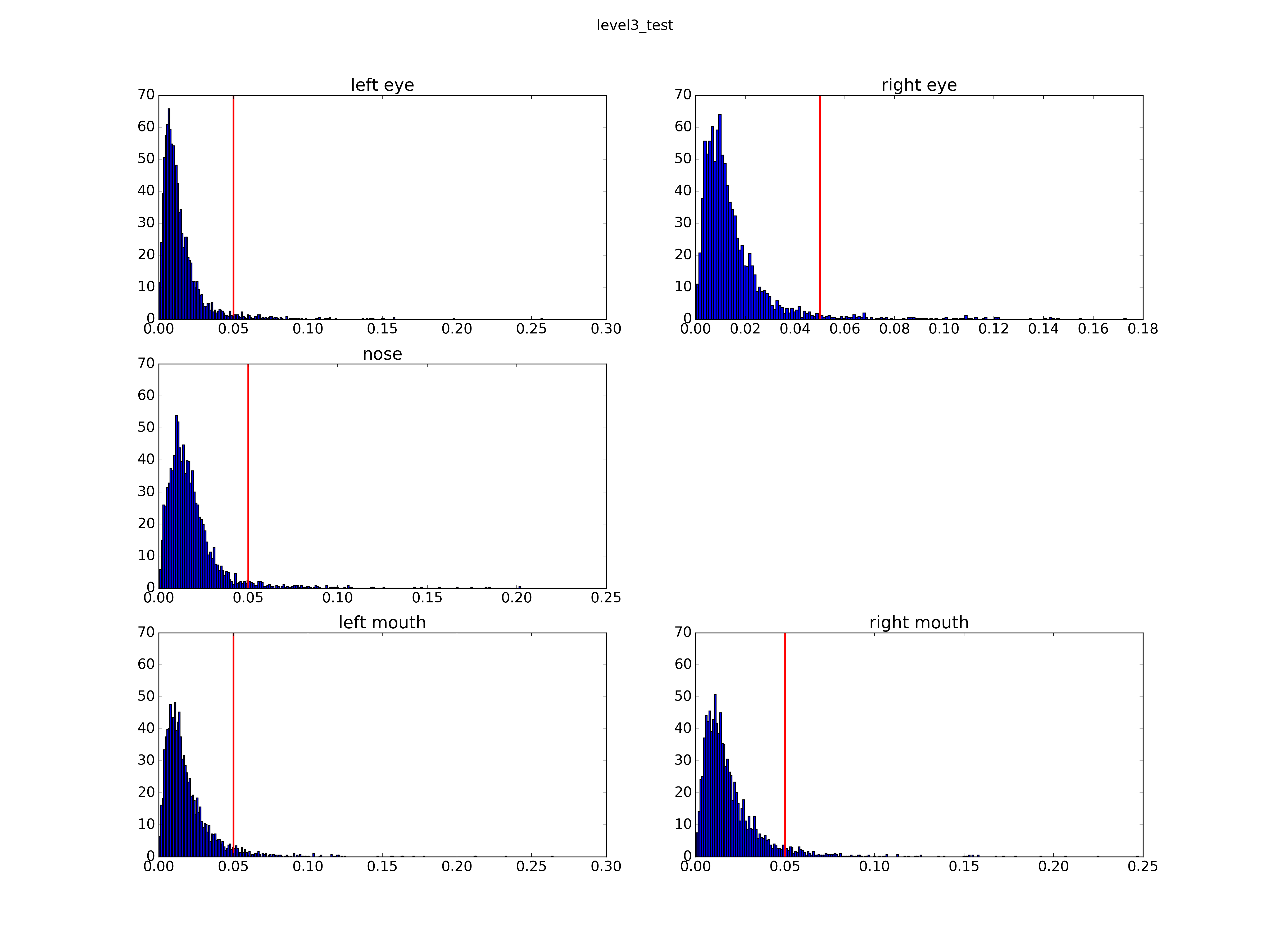
测试误差评价标准公式如下:

其中 l 是bbox的宽度, 如果误差大于5%则认为该点检测失败。
四、其它细节
- 由于输出是多个坐标,是multi-label,因此采用hdf5 layer
- 多级回归:level1预测的是绝对位置,level2和level3预测的是调整位置。
五、测试
把level1的model F1迭代次数更改为2,000,000次,在lfw的3466张图片上测试误差较1,000,000次的时候稍微下降了一点。
| Mean Error | Level1 | Level2 | Level3 |
|---|---|---|---|
| Left Eye | 0.022291 | 0.015758 | 0.014879 |
| Right Eye | 0.023227 | 0.015856 | 0.015009 |
| Nose | 0.029688 | 0.018491 | 0.018174 |
| Left Mouth | 0.028141 | 0.019943 | 0.019349 |
| Right Mouth | 0.028678 | 0.020154 | 0.019674 |
| Failure(Error>5%) | Level1 | Level2 | Level3 |
|---|---|---|---|
| Left Eye | 0.060589 | 0.034911 | 0.032891 |
| Right Eye | 0.059435 | 0.031448 | 0.030294 |
| Nose | 0.131275 | 0.039527 | 0.037796 |
| Left Mouth | 0.111079 | 0.052510 | 0.051645 |
| Right Mouth | 0.118003 | 0.058280 | 0.057126 |
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









