







Fortran语言的历史
Fortran是英文FORmula TRANslation的缩写, 意为"公式翻译". 为科学, 工程问题中那些能够用数学公式表达的问题而设计的语言, 主要用于数值计算. Fortran至今已经有四十多年历史. 第一代Fortran是1954年提出来的, 称为FortranI. 它于1956年在IBM 704计算机上实现的. 是由IBM的John Backus提出并开发的一种容易理解, 简单易学而又像汇编一样高效运行的语言. 1958年出现的FortranII对FortranI进行了很多扩充(如引进了子程序). FortranII在很多机器上实现了. 其后出现的FortranIII因为存在严重的缺陷, 所以没有在任何计算机上实现. 1962年出现的FortranIV并不与FortranII完全兼容.
由于Fortran满足现实需要,所以传播很快, 从而出现了很多的Fortran的版本. 各种版本间语法和语义并不完全一致,所以给用户造成极大不变. 为此, 1962年5月, 当时的美国标准化协会ASA(American Standard Association, 后面改名为ANSI -- American National Standard Institute, 现名为NIST -- National Institute of Standard and Technology)成立工作组开始统一各个版本, 并于1966年正式公布了两个美国标准文本: 标准基本FortranX3.10-1966(相当于FortranII) 和 标准FortranX3.9-1966(相当于FortranIV).
由于Fortran在国际上的广泛使用, 1972年国际化标准组织ISO(International Standard Organization)公布了ISO Fortran标准, 即<程序设计语言FortranISO 1953-1972>. 它分为三级: 一级相当于FortranIV,二级介于FortranII和FortranIV之间,三级相当于FortranII.
FortranIV(即Fortran66)流行了十几年,几乎统治了所有的数值计算领域。但它不是结构化语言,没有实现三种基本结构的语句,程序中需要使用GOTO语句来实现特定的算法,美国标准化协会在1976年对FortranX3.9-1966进行修订,把各个版本有效的功能都加入了进来,并加入了新的功能。并在1978年正式公布为美国国家标准ANSI X3.9-1978 Fortran,称作Fortran77。1980年Fortran77被接受成为国际化标准。Fortran77扩充了一些结构化的语句,但不是完全的结构化语言。由于扩充了字符处理功能,Fortran77不仅适用于数值领域,还适用于非数值领域。
之后经过十多年的标准化过程,1991年通过了Fortran90的新标准ANSI X3.198-1991,相应的国际化标准为ISO/IECI1539:1991。Fortran90保证了Fortran77的兼容性,Fortran77是Fortran90的严格子集。
现在有各种程序设计语言,而且在一些特殊领域使用其它语言会更为合适,但在数值计算、科学和工程领域,Fortran仍然具有强大的优势。随着巨型计算机(向量机和并行机)的异军突起,出现了新的高性能Fortran语言(HPF)。它是Fortran90的一个扩展子集,主要用于分布式内存计算机上的编程,以减轻用户编写消息传递程序的负担。HPF-1.0的语言定义在1992年的超级计算国际会议作出的,正式文本在1993年公布的。1997年发布了HPF-2.0语言定义。Fortran95包含了许多HPF的新功能。
在Fortran90出现之前,在并行机上运行程序需要结合专门的矢量化子程序,或者信赖Fortran编译系统进行自动矢量化。而Fortran90之后,程序员可在程序中有目的地控制并行化。Fortran90具有C++的所有重要功能,然而C语言主要用于微机上的廉价开发,而Fortran的目的是产生高效最优化运行的可执行程序。用Fortran编写的大型科学软件较C语言编写的通常要快一个量级。当今不仅大型机,微机和工作站也有了多处理器。高性能并行计算已成必然,串行机上的线性内存模式已不再适用。Fortran作为具有处理相应问题的标准并行化语言,其独特的数组操作充分体现了它的先进性。
第一个Fortran程序
Fortran的程序用.f后缀表示(表示固定格式),下面是一个求算术平均数与几何平均数的代码:
- C-----Fortran固定格式用C开头(必须在行首)表示注释------
- C每行必须用tab缩进,否则编译错误(严格来说是6个空格)
- C程序大小写不分
- C用PROGRAM表示程序开头
- PROGRAM first_program
- C定义四个实数
- real a, b, av1, va2
- C从标准输入中得到a和b的值
- READ (*,*) a, b
- C--av1为a和b的算术平均数
- av1 = (a+b)/2
- C--av2为a和b的几何平均数
- av2 = sqrt(a*b)
- C在标准输出中显示结果
- WRITE(*,*) av1, av2
- C用END表示程序结尾
- END
- !-----Fortran自由格式中只能用!开头表示注释,C不能用于注释------
- PROGRAM first_program !行前不必用tab缩进,但缩进仍然合法
- REAL a, b, av1, va2
- rEAd (*,*) a, b !大小写不分
- av1 = (a+b)/2
- av2 = sqrt(a*b)
- WRITE(*,*) av1, av2
- END
gfortran可以用来编译fortran程序。
早期的fortran程序(Fortran77)是写在一张12行80列的卡片上的。每一张卡片表示程序中的一行。卡片上的一列可以表示一个字符。当时允许输入的字符只有0-9,A-Z,以及特殊符号“+ - * / ( ) , . ':”。通过在一列中打1~3个孔来表示一个字符:

卡片上明示了0~9行,在0行上面为第11行,再上面为第12行。卡片的编码方式与机器以及应用有关。此处11行和12行都不打孔时,0~9行中的一个孔表示一个数字;第11,12,0行中打一个孔以及1~9行中打一个孔表示一个大写字母;第11,12,0行中打一个孔或不打孔、2~7行中打一个孔同时第8行也打一个孔表示一个特殊字符;不打任何孔的列被视为一个空格。正是因为早期的卡片只支持大写字母,所以如今Fortran程序中不区分大小写。
从上面的打孔卡片可以看到,一行Fortran程序(即一张卡片)代表了一条Fortran语句。有时会出现一张卡打不下一行语句,这时再第二张卡片的第6列打一个非0的孔,可以表示该程序行是上一个程序行的续行。前5列是标号区,可以输入5位整数,通常情况下标号区是不允许输入非数字的,但注释除外,第一列为C的语句不会被编译器处理。第7~72列是语句区。而最后8列是在卡片时代方便程序员查找的注释区,不会被编译器处理。
之后的Fortran90格式更加自由。它一行有132列,可以有多条语句,语句之间用分号隔开,语句也没有固定位置的限制。在程序行中字符“!”后的内容都被视为注释(字符串中的“!”除外)。空格也变得有意义了(Fortran77会忽略行中的空格,关键字和变量中可以有空格)。此外如果132列还写不完一行语句的话,可以在末尾加“&”字符表示有续行,续行的开始则用“&”字符来承接上一行。F77里前面5列的10进制整型数由来表示编号,可用于之后的跳转;F90里还可以用英文名加冒号来表示标签,用于跳转。
文件名后缀.f或.for表示固定格式,而.f90表示自由格式。
一个Fortrant程序的组成结构有:
主程序
[PROGRAM 程序名] ←语句可省略
.....
END [PROGRAM [程序名]] ←END必须有
辅程序(过程)
SUBROUTINE 子程序
FUNCTION 函数
BLOCK DATA 块数据
MODULE 模块 (F90)
内部过程 CONTAINS (F90)
常量与变量
Fortran的常量类型有整型、实型、复型、逻辑型和字符型:
- PROGRAM VARIABLES
- INTEGER I !整型声明语句
- REAL F !实型声明语句
- DOUBLE PRECISION D !双精度声明语句
- COMPLEX C !复型声明语句
- LOGICAL B !逻辑型声明语句
- CHARACTER S !字符型声明语句
- !整型常量
- I = -1234 !整型默认为4字节
- I = -324_8 !8字节整型。下划线加数字表示精度,只允许1,2,4,8个字节
- I = 123_1 !1字节整型
- I = 2343_2 !2字节整型
- I = 238_4 !4字节整型
- !实型常量
- F = 23. !以小数点表示实型数,默认为4字节
- D = 87234.42343256_8 !8字节实型,只允许4或8个字节
- F = 32.16_4 !4字节实型
- F = 7.8E9 !指数表示(E字母)
- D = 8.2384D12 !双精度的指数表示(D字母)
- !复型常量(C语言里没有的)
- C = (8.3, 98) !括号里面分别表示实部与虚部
- !逻辑型常量
- B = .TRUE. !只能有.TRUE.和.FALSE.两个值
- B = .FALSE.
- !字符型常量
- S = 'a'
- S = "x" !Fortran90开始允许使用双引号
- END
Fortran的变量名由字母(不区分大小写)、下划线和数字组成,变量第一个字符必须是字母(下划线也不行)。Fortran77变量可以是6个字符,Fortran90可以有31个字符。Fortran中没有保留字,所以关键字如if也是可以用作变量名的,虽然阅读时容易造成混淆。
上面的代码中可以看到变量的显式声明,在不显式声明的时候,变量名遵循I~N规则,即以I、J、K、L、M、N开头的(未声明的)变量都视为整型变量;其它未声明的变量都被视为实型。比如:
- program implicit_type
- imax = 85; ! i开头的变量被视为整型
- nmin = 23; ! n开头的变量也被视为整型
- phigh = 28.8 ! 其它变量都被视为实型
- end
- program implicit_type
- implicit real (i-k) !i,j,k开头的变量都会被视为实型
- implicit integer (a,d,x-z) !a,d,x,y,z开头的变量都会被视为整型
- implicit complex (c) !c开头的变量会被视为复型
- end
变量类型的优先级为显式声明>隐式声明>I~N规则。显式声明和隐式声明的作用范围仅限于当前程序。
整数常量可以用B开头表示二进制(比如B'101011')、用O开头表示八进制(比如O'34761')、用Z表示十六进制(比如Z'23af8')。
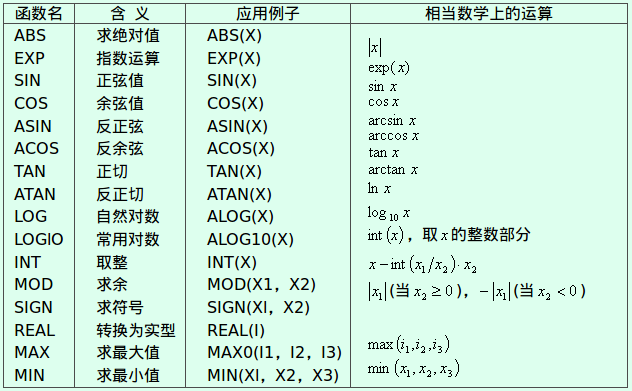
常用的Fortran77库函数如下表所示:
运算符
算术运算符有5种:
+ 表示“加”(或正号)
- 表示“减”(或负号)
* 表示“乘”
/ 表示“除”
** 表示“乘方”关系运算符有6种:
| 关系运算符 | 英语含义 | 所代表的数学符号 | |
| .GT. .GE. .LT. .LE. .EQ. .NE. | > >= < <= == /= | Greater Than Greater than or Equal to Less Than Less than or Equal to EQual to Not Equal to | > (大于) ≥ (大于或等于) < (小于) ≤ (小于或等于) = (等于) ≠ (不等于) |
逻辑运算符有5种:
| 逻辑运算符 | 含义 | 逻辑运算例 | 例子含义 |
| .AND. .OR. .NOT. .EQV. .NEQV. | 逻辑与 逻辑或 逻辑非 逻辑等价 逻辑不等价 | A.AND.B A.OR.B .NOT.A A.EQV.B A.NEQV.B | A,B为真时,则A.AND.B为真 A,B之一为真,则A.OR.B为真 A为真,则.NOT.A为假 A和B值为同一逻辑常量时,A.EQV.B为真 A和B的值为不同的逻辑常量,则A.NEQV.B为真 |
各种运算符的优先级别:
| 运算类别 | 运算符 | 优先级 |
| 括号 | ( ) | 1 |
| 算术运算 | ** | 2 |
| * / | 3 | |
| + - | 4 | |
| 关系运算 | .GT. .GE. .LT. .LE. .EQ. .NE. | 5 |
| 逻辑运算 | .NOT. | 6 |
| .AND. | 7 | |
| .OR. | 8 | |
| .EQV. .NEQV. | 9 |
程序流程控制
if选择结构:
- read *, iValue
- !单行if语名
- if (iValue > 0) print *, iValue, " is greater than 0"
- !if then else语句块
- if (ivalue > 5) then
- iValue = 5
- else if (ivalue > 0) then
- iValue = 0
- else
- iValue = -5
- end if
- print *, iValue
case选择结构:
- !整型case,不支持实型case和复型case
- read *, iValue
- select case (iValue)
- case (3) !当值为3时
- print *, "It's 3!"
- case (6:) !当下界为6时(大于等于)
- print *, "above 6"
- case (:0) !当上界为0时(小于等于)
- print *, "below 0"
- case (4:5) !当在4到5之间时(小于等于下界大于等于上界)
- print *, "between 4 and 5"
- case default !其它情况
- print *, "default"
- end select
- !字符型case
- read *, cValue
- select case (cValue)
- case ("x")
- print *, "it's x!"
- case ("a":"g")
- print *, "between a~g"
- case default
- print *, "other"
- end select
- !逻辑型case
- read *, iValue
- select case (iValue > 0)
- case (.true.)
- print *, "positive"
- case (.false.)
- print *, "negtive or zero"
- end select
循环结构:
- !固定循环次数的do循环
- !不带标号的do
- do i=1, 20, 1 !类似于C里的for(i=1,i<=20,i+=1)
- print *, i
- end do
- !省略最后的增量
- do i=1, 20 !仍然每次递增1
- print *, i
- end do
- !带标号的do
- do 123, i=20, 0, -2 !do后是标号,即从123处开始循环
- print *, i
- 123 continue !循环终端。该行有标号。可以用end do代替,比较过时
- !隐do循环
- !在读写语句里可以控制读写的次数
- print *, (i*5, i=1,20)
- !可以嵌套循环
- write (*,*) ((i,j,i=1,5),j=6,9) !i为内层循环,j为外层循环
- !无限循环
- do
- print *, "I'm here!"
- read *, i
- if (i > 5) cycle !cycle回到循环起点,类似于C的continue
- print *, "not greater than 5!"
- if (i < 0) exit !exit用于退出循环,类似于C的break
- end do
- !用标签来控制嵌套循环的流程
- outer: do
- print *, "I'm in outer!"
- inner: do
- print *, "I'm in inner!"
- read *, i
- if (i > 0) exit inner !跳出内循环
- if (i < 0) exit outer !直接跳出外循环
- end do inner !必须接标签名
- end do outer
- !do while循环
- i = 0
- do while (i < 20)
- <span style="font-size:18px;"><strong> </strong></span> print *, "in while", i
- i = i+1
- end do
终止程序:
- !程序退出
- stop 1 !类似于C的exit(1)
- print *, "skipped" !这行不会被执行
类型声明语句的格式为:类型说明[(种别说明)][,属性说明表] :: 变量名表[=初值],方括号中的可以被省略,所以最简形式为类型说明:: 变量名表
类型说明有五种:integer, real, complex, character, logical
种别说明表示变量所占用的字节数。integer(kind=8)表示8字节的整型。kind可以省略,写成integer(8)。其它类型也可以用相同的方式指定种别。整型种别可以是1、2、4、8,实型种别可以是4、8、16,复型种别可以是8、16、32,逻辑型种别可以是1、2、4,字符型种别只能是1。
在类型后加上“*”号与数字也可以表示变量的字节数,比如integer*8等同于integer(8)。值得注意的是complex*32等同于complex(16),因为复数包含两个部分。character*8表示长度为8的字符串,虽然字符型类别只能是1。
F90中关于种别选择的内部函数有:
KIND(X):函数KIND用于查询变量的种别,它返回X的种别值,当X取值为0时,返回标准种别值即缺省值。如:KIND(0)返回值是整型的标准种别值,KIND(0.)、KIND(.FALSE.)、 KIND(“A”)分别返回实型、逻辑型、字符型的标准种别值。
SELECTED_REAL_KIND([n][,m]):该函数返回实型变量对所取的值范围和精度恰当的种别值。其中n是指明十进制有效位的位数,m指明值范围内以10为底的幂次。例如: SELECTED_REAL_KIND(6,70)的返回值为8,表示一个能表达6位精度、值范围在-1070—+1070之间实型数的种别值为8。但该机型上不能提供满足要求的种别值时,它的返回值是:-1(当精度位数达不到时),-2(当数值范围达不到时),-3(两者都达不到时)。对给定的实型和复型量X,它的精度和范围可通过内部函数PRECISION(X)和RANGE(X)查出。
SELECTED_INT_KIND([m]):该函数返回整型变量对所取的值范围恰当的种别值。m指明值的范围是-10 m—+10 m。属性说明可以是下表的某个或某几个的组合:
| 属性关键字 | 描述 | 适用范围 |
| ALLOCATABLE | 说明动态数组 | 数组 |
| AUTOMATIC | 声明变量在堆栈中而不是在内存中 | 变量 |
| DIMENSION | 说明数组 | 数组变量 |
| EXTERNAL | 声明外部函数的名称 | 过程 |
| INTENT | 说明过程哑元的用意 | 过程哑元 |
| INTRINSIC | 声明一个内部函数 | 过程 |
| OPTIONAL | 允许过程被调用时省略哑元 | 过程哑元 |
| PARAMETER | 声明常量 | 常量 |
| POINTER | 声明数据对象为指针 | 变量 |
| PRIVATE | 限制模块中的实体访问于本块内 | 常量、变量或模块 |
| PUBLIC | 允许模块中的实体被外部使用 | 常量、变量或模块 |
| SAVE | 保存过程执行后其中的变量值 | 变量或公共块 |
| STATIC | 说明变量为静态存储 | 变量 |
| TARGET | 声明变量为目标 | 变量 |
| VOLATILE | 声明对象为完全不可预测并在编译时无优化 | 数据对象或公共块 |
初值可以在声明语句中赋值,也可以用data语句(F77)。data语句的形式为:
DATA 变量名表1/初值表1/[[,]变量名表2/初值表2/…]
比如data i/3会给i赋个初值3。data i,f /4,3.5/ 分别给i和赋值。如果变量已经被赋过值了,那么data语句不会再改变这个变量的值。data语句还可以给数组赋初值(后面介绍)。
字符串的声明方式如下:
CHARACTER[(LEN=整型字符长度表达式[,KIND=种别值])][,属性说明] :: 变量名表[=初始值]
前面已经提到字符的种别只能是1,但是它有一个len的选项。比如:CHARACTER(LEN=12,KIND=1) :: A,B或CHARACTER(KIND=1,LEN=12) :: A,B,len和kind可以省去,但len值必须在前面,如character(12, 1) :: A, B,种别值也可以省略:character(12) :: A, B,它等价于character*12 :: A, B。
字符的长度在声明时可以用*表示为不确定,比如character(len=*), parameter :: c = "abcde"。这行等同于C语言里的const char[] c = "abcde";。只有声明为parameter属性或者过程哑元(dummy argument)时,才可以使用不确定的长度。(哑元在后面介绍)。
字符子串可以通过s(a:b)方式得到,比如s为“abcdefg”,s(3:5), s(:3), s(5:), s(:), s(4:4)分别返回:cde、abc、efgh、abcdefgh和d。注意fortran中索引从1开始,而不是从0开始。子串可以进行赋值,比如s(3:5) = "xyz"。赋值时,如果左边变量的长度更小,则只取右边字符串的前面一部分;如果左边变量长度更大,则在多出的部分补空格。
//操作符可以把两个字符串拼接,比如s//"tommy",可以产生一个新的字符串。
可以用<、>、==和\=来比较两个字符串,区分大小写。"Tommy"和"tommy"是不等的。字符串末尾的空格会被忽略,比如"tommy "与"tommy"是相等的,但字符串开头的空格不会被忽略,比如" tommy"和"tommy"就是不等的。此外还有比较字符大小的函数:LGE、LGT、LLE、LLT:
| 引用方式 | 含 义 | 例 |
| LGE(a1,a2) | a1是否≥a2 | LGE(‘A’,‘B’)值为假 |
| LGT(a1,a2) | a1是否>a2 | LGT(‘A’,‘B’)值为假 |
| LLE(a1,a2) | a1是否≤a2 | LLE(‘A’,‘B’)值为真 |
| LLT(a1,a2) | a2是否<a2 | LLT(‘A’,‘B’)值为真 |
其它与字符串相关的函数:
- program string
- character c
- character*8 :: s
- !字符与数值的转换
- iValue = ichar("a") !97-返回字符的序号值
- iValue = iachar("a"); !97-返回字符的ascii码
- !iValue = iachar("ab") !Error: Argument of IACHAR at (1) must be of length one
- c = char(97) !a-返回序号值对应的字符
- c = achar(97) !a-返回ascii码对应的字符
- !字符串的长度
- iLen = len("abcdefg"); !7
- iLen = len("abcdefg "); !9
- iLen = len_trim("abcdefg "); !7 去除尾部空格后的长度
- !查找子串,找不到返回0
- iIndex = index("abcdefg", "cde"); !3
- iIndex = index("abcdefg", "abcxyz"); !0
- !验证第一个参数里的所有字符是否属于第二个参数表示的字符集,如果都属于则返回0,否则返回
- 第一个不属于字符集的索引。
- iIndex = verify("bcd", "abcdefg"); !0
- iIndex = verify("bcdxyz", "abcdefg"); !4
- !去除末尾的空格
- s = trim("abcd ") // "efg" !abcdefg
- end
派生类型( 结构体)用以下方式说明:
TYPE[,访问属性说明::] 派生类型名
成员1类型说明
……
成员n类型说明
END TYPE [派生类型名]
其中TYPE是关键字,表示派生类型定义开始。访问属性说明关键字是PUBLIC或PRIVATE,默认值是PUBLIC,即访问方式是共用的。PRIVATE表示该类型是专用的,这个关键字只有当TYPE块写在模块说明部分中时,才允许使用。下面是一个例子:
- program type_demo
- type one
- integer a
- character*16 s
- end type
- type :: two
- sequence !表示按定义的顺序储存各个成员
- logical(8):: b
- complex :: c = (23, 9.8) !可以缺省初始化
- end type
- type(one):: o1, o2 = one(18, "xyz");
- type(two):: t1;
- t1%b = .true.
- print *, o2%a, o2%s
- end
数组在程序中的表现如下:
- !声明数组
- real a(10) !下标从1到10的一维数组
- integer b(-5:8) !下标从-5到8的一维数组
- dimension iArray(4) !根据i~n规则确定为是整型或实型数组
- character*8, dimension(2:5) :: sa !类型声明形式
- integer indices(3)
- !赋初值
- data a /10*3/ !赋成10个3
- data b(-3), b(0), b(3) /1, 2, 3/ !把选中的三个元素分别赋成1,2,3
- data (iArray(i),i=1,4) /4*2/ !把所有元素赋为2
- !数组的存取
- print *, "input 10 elements:"
- read *, (a(i), i=1,10) !读入数组a的所有元素
- a(1) = a(1) + 2
- a(2:4) = 5 !把a(2)、a(3)和a(4)都设为5。a(2:4)等价于a(2:4:1)
- print *, (a(i), i=1,5) !打印前5个值
- !三元下标
- b(:) = 8 !打b中的所有元素都设为8
- b(1:6:2) = 7 !把b(1)、b(3)、b(5)设为7,三元下标(起始:终止:增量)
- b(:-3) = 3 !把b(-5)、b(-4)、b(-3)设为3.默认起始为数组开头。
- b(6::2) = 9 !把b(6)和b(8)设为9,默认终止为数组末尾
- print *, b
- !向量下标
- indices = (/3, 8, 6/)
- a(indices) = 13 !把a(3)、a(8)、a(6)设为13
- print *, a
- integer :: a(10, 5) = 77 !大小为10x5的数组,所有的元素值都为77
- a(:,2:3) = 8 !把每行的2,3列都设为8
- print *, ((a(i,j), i=1,10), j=1,5)
自动(automatic)数组根据过程哑元(函数参数)来确定数组的形状与大小:
- subroutine automatic_array(N)
- integer a(N)
- a(:) = 8
- print *, a
- end
call automatic_array(8)
可调(adjustable)数组根据传入的哑元数组以及维度信息来确定数组的大小:
- subroutine adjustable_array(A, N)
- integer A(N)
- print *, A
- end
integer a(8)
call adjustable_array(a, 8) !传入的形状必须与原数组形状一样。
假定形状(assumed-shape)数组可以先假定数组的维度,传入的数组必须有相同的维度。假定形状数组必须定义在interface里:
- interface
- !假定形状(assumed-shape)数组
- subroutine assumed_shape_array(A)
- integer A(:,:) !假定是个二维数组
- end subroutine
- end interface
integer a(2,3)
call assumed_shape_array(a) !a必须是二维,否则编译出错
假定大小(assumed-size)数组先假定数组指定维度的大小,传入的数组必须有相同的维度大小,否则在运行时可能会出现错误:
- subroutine assumed_size_array(A)
- integer A(2,2,*)
- print *, A(:,:,1)
- end
integer a(2,2,3)
call assumed_size_array(a)
数组的赋值可以用下面这种便利的方式:
- integer a(6)
- integer b(8)
- a = (/1,2,3,4,5,6/) !长度必须一样,否则编译会出错
- print *, a
- a = (/3,2,3,4,7,8/) !可以多次对数组进行赋值
- print *, a
- a = [4,8,9,2,1,5] !方括号与(/.../)方式等价
- print *, a
- b = (/1,2,a(1:4),8,9/) !数组方式
- print *, b
- b = (/(i*2,i=1,4),a(3:6)/) !隐do方式
- print *, b
Fortran中的多维数组在内存中是 按列存储的,与C语言按行存储不同。
Fortran90对元素的处理是并行的,哪怕不是在并行计算机上,操作在形式上也是并行的。看下面的例子:
- integer :: a(9) = (/(i,i=1,9)/)
- a(2:9) = a(1:8) !并行方式
- print *, a ! 1 1 2 3 4 5 6 7 8
- a = (/(i,i=1,9)/)
- do i=2,9
- a(i) = a(i-1) !串行方式
- end do
- print *, a ! 1 1 1 1 1 1 1 1 1
reshape函数可以把一维数组转换成多维数组的格式,从而能够将其赋给一个多维数组变量。它的格式为:
结果=RESHAPE(源,形状[,补充][,顺序])
源是用来转变的一维数组;形状是一个一维整型数组,各元素表示结果数组的各个维度的大小;补充是和源一样类型的一维数组,当源比结果数组小时,其元素用来补充缺少的元素;顺序也是一维数组,其元素为1到n的一个排列,其中n为形状数组的大小,默认情况下顺序数组的元素为(1,2,...,n),表示源数组中的元素先填充顺序为n的维度,最后填充顺序为1的维度。下面是一个例子:
- integer b(2,3)
- b = reshape((/1,2,3,4,5,6/), (/2,3/))
- print *, b
- b = reshape((/1,2,3/), (/2,3/), (/8,9/))
- print *, b !1,2,3,8,9,0。补充数组的元素仍不够的情况下补0
- b = reshape((/1,2,3,4,5/), (/2,3/), (/8,9/), (/2,1/))
- print *, b !1,4,2,5,3,8。顺序2,1说明先填满第一个维度(即行),再来填第二个维度(即列)。
where语句可以用来进行带条件的数组赋值,它的形式为
WHERE(屏蔽表达式) 赋值语句 或
[构造名:]WHERE(屏蔽表达式1)
[块]
[ELSEWHERE(屏蔽表达式2) [构造名]
[块]]
[ELSEWHERE [构造名]
[块]]
END WHERE [构造名]
下面是where的一个例子:
- integer A(5), B(5), C(5)
- A = (/1,2,3,4,5/)
- B = (/3,3,3,3,3/)
- C = (/0,0,0,0,0/)
- where (A >= B) C = A
- print *, C ! 0,0,3,4,5
- where (A < B)
- C = -1
- elsewhere (A == B)
- C = 0
- elsewhere
- C = 1
- end where
- print *, C ! -1,-1,0,1,1
forall语句是Fortran95对where语句的推广,它的一般形式为:
FORALL(循环三元下标[,循环三元下标]…[,屏蔽表达式]) 赋值语句 或
[构造名:]FORALL(循环三元下标[,循环三元下标]…[,屏蔽表达式])
[块]
END FORALL [构造名]
下面是forall的一个例子:
- integer A(5, 5)
- A = reshape((/(i,i=1,25)/), (/5,5/))
- forall(i=2:3,j=1:5:2) A(i,j) = 0
- print *, A
Fortran中可以直接以数组(或数组片段)为对象进行运算。当两个数组相容(即形状相同)时, 所有的算术运算符 (+ , - , * , / , **) 、逻辑运算符 ( 如 .AND. , .OR. , .NOT.) 和所有关系运算符 ( 如 .LT. , .EQ. , .GT.) ,还有很多内在函数都可以接受数组名称作为参数并对数组元素逐一运算。比如:
- integer A(2,3), B(2,3), C(2,3)
- logical P(2,3), Q(2,3), R(2,3)
- real X(2,2), Y(2,2)
- !算术运算
- A = reshape((/(i,i=1,6)/), (/2,3/))
- B = 2
- C = A + B
- print *, C
- C = A - B
- print *, C
- C = A * B
- print *, C
- C = A / B
- print *, C
- !比较运算
- P = A < B
- print *, P
- Q = A > B
- print *, Q
- !逻辑运算
- R = P .and. Q
- print *, R
- R = P .or. Q
- print *, R
- R = .not. P
- print *, R
- !基本内在函数
- X = reshape((/1.,2.,3.,4./), (/2,2/))
- Y = cos(X)
- print *, Y
- Y = sin(X)
- print *, Y
- Y = sqrt(X)
- print *, Y
| 函数名称 | 描述 |
| ALL(mask[,dim]) | 判断全部数组值在指定维上是否都满足mask的条件 |
| ANY(mask[,dim]) | 判断是否有数组值在指定维上满足mask的条件 |
| COUNT(mask[,dim]) | 统计在指定维上满足mask的条件的元素个数 |
| CSHIFT(array,shift[,dim]) | 进行指定维上的循环替换 |
| DOT_PRODUCT(vector_a,vector_b) | 进行两个向量的点乘 |
| EOSHIFT(array,shift[,boundary][,dim]) | 在指定维上替换掉数组末端,复制边界值到数组末尾 |
| LBOUND(array[,dim]) | 返回指定维上的下界 |
| MATMUL(matrix_a,matrix_b) | 进行两个矩阵(二维数组)的乘积 |
| MAXLOC(array[,dim][,mask]) | 返回数组的全部元素或指定维元素当满足mask条件的最大值的位置 |
| MAXVAL(array[,dim][,mask]) | 返回在指定维上满足mask条件的最大值 |
| MERGE(tsource,fsource,mask) | 按mask条件组合两个数组 |
| MINLOC(array[,dim][,mask]) | 返回数组的全部元素或指定维元素当满足mask条件的最小值的位置 |
| MINVAL(array[,dim][,mask]) | 返回在指定维上满足mask条件的最小值 |
| PACK(array,mask[,vector]) | 使用mask条件把一个数组压缩至vector大小的向量 |
| PRODUCT(array[,dim][,mask]) | 返回在指定维上满足mask条件的元素的乘积 |
| RESHAPE(source,shape[,pad][,order]) | 使用顺序order和补充pad数组元素来改变数组形状 |
| SHAPE(source) | 返回数组的形状 |
| SIZE(array[,dim]) | 返回数组在指定维上的长度 |
| SPREAD(source,dim,ncopies) | 通过增加一维来复制数组 |
| SUM(array[,dim][,mask]) | 返回在指定维上满足mask条件的元素的和 |
| TRANSPOSE(matrix) | 转置二维数组 |
| UBOUND(array[,dim]) | 返回指定维上的上界 |
| UNPACK(vector,mask,field) | 把向量在mask条件下填充field的元素解压至数组 |
数组可以是静态的,也可以是动态的。静态数组的存储空间直到程序退出才会释放,而动态数组(F90)可以在运行时进行分配和释放。动态数组有两种:自动数组和可分配数组,前面已经介绍过了。
对于allocable的数组,可以用allocate来分配一块内存:
ALLOCATE(数组名[维界符][,数组名[(维界符[,维界符...])]] ...[,STAT=状态值])。
STAT用来接受返回值,如果不设置STAT的话,如果分配出错,程序会中止。下面是个例子:
- INTEGER, ALLOCATABLE :: A(:),B(:)
- INTEGER ERR_MESSAGE
- ALLOCATE(A(10:25),B(SIZE(A)),STAT=ERR_MESSAGE)
- IF(ERR_MESSAGE.NE.0) PRINT *,'ALLOCATION ERROR'
DEALLOCATE( 数组名 [, 数组名 ]...[,STAT= 状态值 ])
ALLOCATED(数组名)可以判断一个数组是否已被分配。
过程和模块
F90中,共有四种程序单元:主程序、过程或辅程序、块数据单元和模块。下表是对它们的概括描述:
| 程序单元 | 定义 |
| 主程序 | 主程序是程序开始执行的标志,其第一条语句不能是SUBROUTINE,FUNCTION,MODULE和BLOCK DATA。主程序可以用PROGRAM语句作为第一条语句,但不是必需的 |
| 过程 | 子程序或函数 |
| 块数据单元 | 在命名的公共块中提供变量初始值的程序单元 |
| 模块 | 包含数据对象定义、类型定义、函数或子程序接口和其它程序可访问的函数或子程序 |
主程序是整个程序的入口,类似于C里的main函数。它的格式为:
[PROGRAM [程序名]]
[说明部分]
[可执行部分]
[CONTAINS
内部过程]
END [PROGRAM[程序名]]
过程类似于C语言里的函数。它分为外部过程、内部过程和内在过程。
外部过程独立于其它的程序单元,它的形式有两种:
外部函数:FUNCTION语句
[说明部分]
[可执行部分]
[CONTAINS
内部过程]
END [FUNCTION函数名]
外部子程序:SUBROUTINE语句
[说明部分]
[可执行部分]
[CONTAINS
内部过程]
END [SUBROUTINE子程序名]
内部过程是(通过contains语句)包含在宿主单元(外部过程、模块或主程序单元)内的过程,它的形式也有两种:
内部函数 :FUNCTION语句
[说明部分]
[可执行部分]
END [FUNTION函数名]
内部子程序:SUBROUTINE语句
[说明部分]
[可执行部分]
END [SUBROUTINE子程序名]
可以看到内部过程不能再包含其它的内部过程。
内在过程就是Fortran的库函数,比如sin、abs等。Fortran90中定义了113个内在过程。
下面是子程序与过程(外部与内部)的例子:
- program procedures
- implicit none
- integer:: x=5,y=6,res=0
- integer:: add !声明函数(返回值)
- character*8 get_something
- call increase(x, y) !必须用call来调用一个
- print *, x, y ! 6, 7
- res = add(x,y)
- print *, x, y, res! !7,8,15
- print *, get_something() !hello
- end
- subroutine increase(x,y) !x,y为哑元,类似于C的参数,但是是引用
- integer:: x,y; !声明实元,与哑元对应起来。类似于实参和形参的关系。
- x = x + 1;
- y = y + 1;
- end
- function add(x,y) result(s) !s为返回值
- integer:: x,y,s;
- x = x+1;
- y = y+1;
- s = x+y;
- end
- function get_something() !不声明result则函数名自身为返回值名
- character*8 get_something;
- call inner(get_something);
- contains
- subroutine inner(s) !内部过程
- character*8 s
- s = "hello"
- end subroutine
- end
External属性和哑过程用来调用外部文件里的过程,分别对应于C的extern关键字和外部函数声明。下面是一个例子:
caller.f:
- program caller
- integer,external:: add
- print *, add(1,2)
- end
- function add(x,y) result(s)
- integer,intent(in):: x,y !被声明为intent(in)的参数不能被修改
- integer:: s
- s = x + y
- end
除了哑过程,还可以用 interface来声明外部过程:
- program caller
- interface
- function add(x,y)
- integer::x,y,add
- end function
- end interface
- print *, add(1,2)
- end
变元的save属性类似于c的static,而且在未声明的情况下变量也都是save的。(而且我的gfortran(gcc4.5.2)根本不支持automatic属性,哪怕是用-fautomatic和-frecursive的命令参数。这样所有的变量都只能是save的……fortran95本应该支持static关键字的,但我的gfortran也不支持……)。
在调用子过程或函数时,可以使用关键字变元,使用关键字改变传入实参的顺序。比如:
- program caller
- interface
- subroutine test_keyword_param(A,B,C,D)
- integer A,B,C,D
- end
- end interface
- call test_keyword_param(62,C=83,D=7,B=2)
- end
- subroutine test_keyword_param(A, B, C, D)
- integer A, B, C, D
- print *, "A=", A;
- print *, "B=", B;
- print *, "C=", C;
- print *, "D=", D;
- end
另一个有趣的特性是可选变元,它用optional属性表示。代码如下:
- subroutine test_optional_param(A, B, C, D)
- integer A, B
- integer, intent(in), optional :: C, D
- print *, present(C)
- !logical, intrinsic :: present
- if (present(C)) then
- print *, C, "as C is passed in!";
- end if
- if (present(D)) then
- print *, D, "as D is passed in!";
- end if
- end
如果函数要支持 递归的话,必须在函数前显式声明recursive属性,而且还必须有显式result声明。
通过接口可以把几个子过程合并成一个类属过程,类似于C里的模板的作用:
- interface show
- subroutine show_integer(x)
- integer x
- end
- subroutine show_real(x)
- real x
- end
- end interface
- call show (55);
- call show (32.13);
- end
- subroutine show_integer(x)
- integer x
- print *, "integer - ", x
- end
- subroutine show_real(x)
- real x
- print *, "real - ", x
- end
块数据单元用来存放公共数据,它的形式为:
BLOCK DATA[块数据名]
[说明部分]
END [BLOCK DATA[块数据名]]
Fortran中所有程序单元都是分别编译的,所以它们的作用域都是独立的。也就是说,一个程序单元内部的局部变量是不会被其它程序单元使用的。Fortran77使用了COMMON和EQUIVALENCE来共享数据。
COMMON用于在不同的程序单元中共享数据的用法如下:
- program common_test
- common /group1/a,b,c
- integer a,b,c
- a = 5
- b = 6
- c = 7
- call print_commons
- end
- subroutine print_commons
- common /group1/x,y,z
- integer x, y, z
- print *, x, y, z !5,6,7
- end
EQUIVALENCE用于在同一程序单元中共享数据:
- program equivalence_test
- integer a, b, c
- character*8 e, f
- equivalence (a, b, c), (e, f) !a,b,c共享数据;e,f共享数据
- a = 5;
- print *, a, b, c !5,5,5
- b = 10;
- print *, a, b, c !10,10,10
- e = "ok"
- print *, e, f !ok,ok
- end
INCLUDE是一种共享代码(而非共享数据)的方法:
- program interface_test
- include 'mytype.f'
- type(mytype) :: t1 = mytype(1,1.)
- end
- type mytype
- integer a
- real b
- end type
在Fortran90引入了 模块MODULE的概念,它包含了COMMON、EQUIVALENCE和INCLUDE的功能。它是共享数据推荐使用的方式:
- module mymodule
- integer global
- integer, private:: hidden
- type mytype
- integer a
- real b
- end type
- type, private:: hiddentype
- integer x
- real y
- end type
- contains
- subroutine show
- print *, global, hidden
- end subroutine
- end module
- program interface_test
- use mymodule
- interface
- function add(x,y) result(z)
- use mymodule
- type(mytype), intent(in) :: x, y
- type(mytype) :: z
- end function add
- end interface
- type(mytype) :: t1 = mytype(1,1.)
- type(mytype) :: t2 = mytype(2,2.)
- type(mytype) :: t3
- ! type(hiddentype) :: ht = hiddentype(5,0.5) !不能访问private type
- global = 88
- hidden = 99
- call show !88, 0 private数据访问无效
- t3 = add(t1, t2)
- print *, t3%a, t3%b !3,3.0
- call show !88,0 add函数里对global的赋值无效
- end
- function add(x,y) result(z)
- use mymodule, only:mytype
- type(mytype):: x,y,z
- z%a = x%a + y%b
- z%b = x%b + y%b
- globle = 13 !允许,但无效
- end
基于上例,这里展示一下Fortran中重载操作符的方法, .word.类型的也是一种操作符,类似于.and.和.or.:
- module mymodule
- type mytype
- integer a
- real b
- end type
- interface operator(+) !重载+
- module procedure add
- end interface
- interface operator(.add.) !重载.add.
- module procedure add
- end interface
- contains
- function add(x,y) result(z)
- type(mytype), intent(in):: x,y
- type(mytype) z
- z%a = x%a + y%b
- z%b = x%b + y%b
- end function
- end module
- program interface_test
- use mymodule
- type(mytype) :: t1 = mytype(1,1.)
- type(mytype) :: t2 = mytype(2,2.)
- type(mytype) :: t3
- t3 = add(t1, t2)
- t3 = t1 + t2
- t3 = t1 .add. t2
- print *, t3%a, t3%b !3,3.0
- end
输入输出和文件
文件分为外部文件和内部文件。外部文件包括外部设备(如键盘和屏幕)以及磁盘上的文件,而内部文件指在内存中可以像磁盘文件一样进行操作的数据块。
为了对文件进行操作,需要使用逻辑设备与它们连接。外部文件可以通过open(unit=id,file='filename')的方式打开,id便是逻辑设备的标识符,可以用来读写,也能用close关闭文件。设备号的取值范围为-32768到32767。
Fortran预定义了4种外部文件(设备):
| 设备号 | 连接的设备 |
| 星号(*) | 总是键盘和显示器 |
| 0 | 缺省状态下是键盘和显示器 |
| 5 | 缺省状态下是键盘 |
| 6 | 缺省状态下是显示器 |
此前所有的print *, ...语句就是表示向显示器输出。*设备不能被关闭。
内部文件对应的逻辑设备可以用一个变量名来表示:
- subroutine test_internal_unit
- character(14) str
- write (str, '(All)'), 1
- read (str, '(All)'), n
- print *, n
- end
外部文件的访问方式有两种:顺序访问和直接访问;而文件结构有三种:格式化文件、无格式文件和二进制文件。这样组合出来的文件有六种。
1、格式化顺序文件
以可读的字符串形式进行(顺序)读写。文件打开时在文件开头写入(文件原有数据会被清空),之后每次在文件末尾处写入一条记录。所有记录的大小不定,且由回车符加换行符(即\r\n)分隔。下面是一个例子:
- subroutine test_seq_formatted_file
- open (3, file='myfile') ! 默认情况下文件打开方式为顺序访问格式化文件
- write (3, '(All)'), "43" ! '(All)'为一种格式,读写格式化文件时必需。数字以可读的字符串形式写入。
- write (3, '(All)'), "again" ! 每次写一条记录会自动添加\r\n以示记录结束
- close (3)
- end
2、 格式化直接文件
所有的记录同样用\r\n分隔,但所有记录的大小一样,而且在打开文件时需要指定每个记录的大小(字节数):
- subroutine test_dir_formatted_file
- open (4,file='mydirfile',form='formatted',access='direct',recl=10)!recl=10表示每条记录的长度是10个字节,所有记录用\r\n隔开
- write (4, '(All)', rec=3), 65 !在第三个记录里写入65(以字节形式)
- write (4, '(All)', rec=5), 'hello'
- close (4)
- open (4,file="mydirfile",form='formatted',access='direct',recl=10)
- read (4, '(All)', rec=3), iValue
- print *, iValue ! 65
- close (4)
- end
3、 无格式顺序文件
记录不再用\r\n分隔,而且每个记录的大小也可以不同。文件内容的排序方式为:记录1大小(字节数) + 记录1 + 记录1大小 + 记录2大小 + 记录2 + 记录2大小+记录3大小+记录3 + 记录1大小……每个记录的前后分别用1个字节来表示该记录的大小。下面是个例子:
- subroutine test_seq_unformatted_file
- integer, dimension(20):: array, array2
- real :: r1, r2
- array = (/(i,i=1,20)/)
- r1 = 4.5
- open (8, file='uf-seq', form='unformatted')
- write (8), array
- write (8), r1
- close (8)
- open (8, file='uf-seq', form='unformatted')
- read (8), array2
- read (8), r2
- close (8)
- print *, array2, r2
- end
4、 无格式直接文件
记录不用任何特殊方式分隔。每个记录包含相同的字节数:
- subroutine test_dir_unformatted_file
- integer(4) :: i=5, j=0
- open (9, file='uf-dir', form='unformatted',access='direct',recl=4)
- write (9, rec=3), i
- write (9, rec=10), 10
- read (9, rec=3), j
- close (9)
- print *, j ! 5
- end
5、 二进制顺序文件
数据就是以字节序列的方式存放在文件中,没有添加任何表示文件结构的特殊字节。这种文件的打开方式为form='binary'。(我的gfortran不支持这种形式的文件……)
6、二进制直接文件
与无格式直接文件类似,所有记录的大小一样,其大小由open函数的recl参数指定。记录中未被使用的部分由未定义的字节填充。
下面贴出四类文件操作语句:
a) OPEN语句
OPEN语句用于把设备号与文件名连接起来,并且对文件的各项性质进行指定。它的一般形式为:
OPEN([UNIT=]unit[,ACCESS=access][,ACTION=action][,BLANK=blanks][,BLOCKSIZE=blocksize][,CARRIAGECONTROL=carriagecontrol][,DELIM=delim][,ERR=err][,FILE=file][,FORM=form][,IOFOCUS=iofocus][,IOSTAT=iostat][,PAD=pad][,POSITION=position][,RECL=recl][,SHARE=share][,STATUS=status])
其中的各项参数的意义及取值如下:
1) UNIT:设备号说明。unit是大于或等于0的正整数,设备号说明是OPEN语句的第—项时可以省略“UNIT=”。
2) ACCESS:存取方式说明。access是字符串表达式:
APPEND 追加方式
SEQUENTIAL 顺序访问方式
DIRECT 直接访问方式
当省略此说明项时为顺序访问方式。
3) ACTION:描述文件的读写属性。action是字符串表达式:
READ 文件为只读方式打开
WRITE 文件为只写方式打开
READWRITE 文件为可读写方式打开
当省略此说明项时,文件打开顺序:READWRITE->READ->WRITE。
4) BLANK:说明数据格式输入字段中空格的含义。blank是字符串表达式:
NULL 空格忽略不计,相当于在格式描述符中的BN编辑符
ZERO 空格处理成数字0,相当于BZ编辑符
当省略此说明项时为ZERO。此说明只能用于格式输入。
5) BLOCKSIZE:指定以字节为单位的设备缓存的大小,默认值为一4字节整数。
6) CARRIAGECONTROL:指明处理文件中的第一个字符的方式,其值为字符串表达式:
Fortran 对第一个字符作一般的Fortran解释
LIST 指出在文件的每两个记录之间有—个空格
默认状态下,对于连接到打印机和显示器这样的设备,设置值为Fortran,对于连接到文件的设备,设置值为LIST。当FORM被设成UNFORMATTED和BINARY时,其值被忽略。
7) DELIM:指明分隔直接列表或格式化名称列表记录的方式,其值为字符串表达式:
APOSTROPHE 用单撇号(’)分隔
QUOTE 用双撇号(”)分隔
NONE 不用分隔符
如果在OPEN语句中设置了分隔符,则在文件中的单撇号和双撇号都是成对出现的。
8) ERR:出错处理说明。其值是同一程序中的一条语句的标号,当OPEN语句执行出错时执行此语句。如果省略该项,则出错时给出出错信息并终止运行。
9) FILE:文件名。file是一字符串表达式,可以是空、合法的数据文件名字、设备名字或是作为内部文件的变量。在WinNT/9x中允许使用长度大于8的文件名和长度大于3的文件扩展名。省略此项时,编译器将自动产生一个文件名唯一的临时文件,这个临时文件将在结束运行或与文件连接的设备关闭后被删除掉。
10) FORM:记录格式说明。form是字符串表达式:
FORMATTED 记录按有格式存放。
UNFORMATTED 记录按无格式存放。
当省略此说明项时为:对顺序文件是有格式的;对直接文件是无格式的。
11) IOFUS:指出一个新Quickwin子窗口是否为活动窗口,其值为逻辑值。缺省值为真。
12) IOSTAT:出错状态说明。iostat是—个缺省长度为4的整形变量。当执行此OPEN语句时系统给变量赋值:
零 没有发生错误
负数 文件结尾
正数 发生错误,其值视具体计算机系统而定
若省略该项则没有此功能。
13) PAD:从格式化文件中记录的数据少于要读取的数据时,是否用空格来填充没有从记录中读到数据的变量。pad是字符串表达式:
YES 填充(默认值)
NO 不填充
14) POSITION:指定打开顺序文件的访问位置,position是字符串表达式:
ASIA 已被连接的文件的访问位置是固定的,未被连接的文件的访问位置是文件的开始处。
REWIND 把文件的访问位置定在文件的开始处(文件己存在)。
APPEND 把文件的访问位置定在文件的末尾处(文件己存在)。
对于一个新文件,文件的访问位置总是被定在文件的开始处。
15) RECL:记录长度(单位为字节)说明。recl是指定的正整型量或算术表达式,用来指定直接文件中的每条记录的字节数,或顺序文件中的记录的最大长度。
16) SHARE:指明当文件打开时是否实现文件的锁定。share是字符串表达式:
DENYRW 动态读写模式。不允许其他的进程打开这个文件。
DENYWR 动态写模式。不允许其他的进程以写的方式打开这个文件。
DENYRD 动态读模式。不允许其他的进程以读的方式打开这个文件。
DENYNONE 默认的非动态模式。允许其他的进程打开这个文件。
17) STATUS:文件状态说明。status是字符串表达式:
OLD 表示指定的文件是已经存在的老文件。这一状态一般用于读操作,如果用于写操作则重写文件,原文件内容将被覆盖。如果指定的文件并不存在,则系统将给出出错信息。
NEW 表示指定的文件尚不存在。执行OPEN语句时将在磁盘上建立该文件并使其状态改变为OLD。NEW状态一般用于写操作。如果指定的文件名已经存在将给出出错信息(有的系统不给出信息而是把这个已经存在的文件冲掉使原来的内容不复存在)。
SCRATCH 表示与设备号相连接的文件在关闭时将被自动删除。注意:此状态不能与FILE说明共存,只能用于由计算机系统指定的文件名,使该文件作为程序运行过程中的一个临时性文件。
REPLACE 表示替换一个有相同名字的文件,如果没有同名的文件存在,将产生一个新文件。
UNKNOWN 表示文件可以是已存在的或不存在的。系统打开文件状态的次序为:OLO->NEW->创建新文件。STATUS的设置值只影响磁盘文件,像键盘和显示器这样的设备将忽略这一设置。
若省略该项时默认的状态为UNKNOWN。
b) ENDFILE语句
ENDFILE语句的功能是在文件上写一条文件结束记录,这时文件定位在结束记录的后面。它的一般形式为:
ENDFILE{unit|([UNIT=]unit[,ERR=err][,IOSTAT=iostat])}
由于用ENDFILE语句在文件中写入一条结束记录后,文件的指针被定位在结束记录之后,所以若再想向同一个文件中添加更多的记录,就必须使用BACKSPACE或REWIND语句对文件进行文件指针定位的操作。在直接访问文件中使用ENDFILE语句在文件中写入一条结束记录后,新的结束记录后的所有老的记录都将被删除掉。
c) CLOSE语句
CLOSE语句解除设备号与文件的连接,又称关闭文件。它的一般形式为:
CLOSE([UNIT=]unit[,ERR=err][,IOSTAT=iostat][,STATUS|DISPOSE|DISP=status])
其中除STATUS以外的各项参数的意义及取值与OPEN语句中的相同。STATUS是文件关闭后状态说明,其值是一字符串:
DELETE 与设备连接的文件不保留,被删除
KEEP(或SAVE) 与设备号连接的文件保留下来不被删除
PRINT 将文件递交给打印机打印并被保留(仅对顺序文件)
PRINT/DELETE 将文件递交给打印机后被删除
SUBMIT 插入一个进程以执行文件
SUBMIT/DELETE 插入一个进程以执行文件,当插入完成后被删除
默认设置将删除带有SCRATCH属性的临时文件,对其它文件为KEEP。
在程序中,没有必要显示的进行文件的关闭,—般情况下,当程序退出时将以各个文件的默认状态关闭所有的文件。CLOSE语句不必与OPEN语句出现存同一程序单元中。
d) 文件指针定位语句
REWIND语句:称为反绕语句,它使指定设备号的文件指针指向文件的开头,通常用于顺序文件的操作。它的一般形式为:
REWIND{unit|([UNIT=]unit[,ERR=err][,IOSTAT=iostat])
BACKSPACE语句:称为回退语句,它使指定设备号的文件指针退回一个记录位置,一般用于顺序文件。它的一般形式为:
BACKSPACE{unit|([UNIT=]unit[,ERR=err][,IOSTAT=iostat])
除了以下几种情况外,使用BACKSPACE语句正好使文件的指针向前移动一条记录:本条记录前再没有记录时文件指针的位置不变;文件指针的位置在一条记录的中间时,文件指针移到本条记录的开始处;本记录的前—记录是文件结束记录时,文件指针移到文件结束记录之前。
使用硬件设备
在Fortran中标准的输入设备是键盘,标准的输出设备是显示器(控制台)。—般的输入输出语句都是针对标准设备进行操作的,如果想对除键盘和显示器以外的其他的物理设备进行读写操作,就应该把物理设备名描述为文件名,这样就可以像操作文件一样对其进行操作,绝大多数设备名没有扩展名。以下是WinNT/9x下的一些设备名。
| 设备 | 描述 |
| CON | 控制台(即屏幕,标准输出设备) |
| PRN | 打印机 |
| COMl | 1#串行通信口 |
| COM2 | 2#串行通信口 |
| COM3 | 3#串行通信口 |
| COM4 | 4#串行通信口 |
| LPTl | 1#并行通信口 |
| LPT2 | 2#并行通信口 |
| LPT3 | 3#并行通信口 |
| LPT4 | 4#并行通信口 |
| NUL | 空(NLTLL)设备。放弃输出,不包含任何输入 |
| AUX | 1#串行通信口 |
| LINE1 | 1#串行通信口 |
| USER1 | 标准输出 |
| ERRl | 标准错误 |
| CONOUT$ | 标准输出 |
| CONIN$ | 标准输入 |
输入输出的方式,包括格式化的方式和非格式化的方式。
非格式输入输出,包括直接列表I/O和名称列表I/O。直接列表输出便是之前常看到的write (*), var1, var2, var3的形式。这些直接附在write语句后,用逗号分隔的就是直接列表。而直接列表输入以read (*,*), var1, var2, var3的形式。括号里的星号分别对应于设备单元(stdin)和输出格式。输入可以用星号(*)表示重复,比如10*3表示输入10个3。用斜杠(/)表示输入流的结束。
名称列表以NAMELIST/名称列表组名/变量列表[[,]/组名/变量列表]...的形式表示。比如名称列表输出的代码可以是:
- integer:: i1=5
- logical:: l1=.true.
- character*20:: c1='hello'
- namelist/wlist/i1,l1,c1
- write (*, nml=wlist)
- &WLIST
- I1= 5,
- L1=T,
- C1="hello ",
- /
格式化输入输出要更复杂些,下面是格式化输出的例子:
- integer :: i1=5, i2=2351
- integer myformat
- print 12345, i1, i2 !使用标号为12345的格式
- 12345 format(I3,I5) !定义了宽度分别为3和5的两个整型
- assign 12345 to myformat !将标号格式赋给一个整型(已删除的特性)
- write (*, myformat), 6313, 81 !输出*** 81。因为格式为三位,却要输出四位整型,所以显示星号。
- print '(F8.3)', 23.35 !直接以字符串表示格式。fw.d表示总宽(包括负号和小数点)为w、小数部宽为d的实数
- print '(E10.3)', 23432532.32 !Ew.d表示总宽为w有效位为d的指数形式。输出:0.234E+08
- print '(G8.3)', 1223.54 !绝对值小于0.1或大于10的d次方的数用E格式,否则用F格式
- print '(D8.3)', 234.52 !双精度数据,与E编辑符用法相仿。输出:.235D+03(四舍五入)
- print '(L5)', .true. !逻辑型数据。 输出:T
- print '(A)', 'a' !字符
- print '(A5)', 'abc' !字符串
- print '(B5.3)', 1 !二进制。Bw.d,w为字段宽度。m表示需要输出的最少数字位数,缺省值为1。输出:001
- print '(O5.3)', 82 !八进制。输出:122
- print '(Z5.3)', 82 !十六进制。输出:052
- print '(EN16.6e2)', 23928.2 !工程计数法,ENw.d[Ee]。EN和E编辑描述符基本类似,区别在于EN输出数据的非指数部>分的绝对值强制在1到1000的范围内,且指数可以被3整除。包括指数的区域的宽度是w个字符,小数点后d个字符,指数宽度e是>可选的。输出:23.928199E+03
- print '(ES16.6e2)', 23928.2 !科学计数法,和E编辑描述符也基本类似,区别在于ES输出数据的非指数部分的绝对值强
- 制在l到10的范围内,而非E的0到1的范围。输出:2.392820E+04
- end
- integer :: i=5
- print '(2I4)', 23, 532 !表示输出两个I4格式
- !print 111, 26, 232, 1921 !
- 11 !format(<i-2>I4) !等同于format(3I4)。gfortran不支持
- 12 !format(2I<i+5>) !等同于format(2I10)。gfortran不支持
不可重复编辑描述符可以改变解释重复编辑符的方式,还可以改变完成输入输出的方式。
| 形式 | 名称 | 用途 | 可否用于输入 | 可否用于输出 |
| ’ ’或” ” | 撇号编辑 | 传递string到输出单元 | 否 | 是 |
| nH | Hollerith编辑 | 传递下n个字符到输出单元 | 否 | 是 |
| Q | 字符计数编辑 | 返回记录中剩余字符的数目 | 是 | 否 |
| T,TL,TR | 位置编辑(Tab) | 指定记录的位置 | 是 | 是 |
| nX | 位置编辑 | 指定记录的位置 | 是 | 是 |
| SP,SS,S | 可选加号的编辑 | 控制加号的输出 | 否 | 是 |
| / | 斜杠编辑 | 指向下一个记录或写记录结束符 | 是 | 是 |
| \ | 反斜杠编辑 | 延续相同的记录 | 否 | 是 |
| $ | 美元符号编辑 | 延续相同的记录 | 否 | 是 |
| : | 格式控制结束 | 如果I/O列表中没有其它记录则结束语句 | 否 | 是 |
| kP | 指数比例编辑 | 设置后面的F和E编辑符的指数比例 | 是 | 是 |
| BN,BZ | 空格解释 | 指定对数值空格的解释 | 是 | 否 |
1、 撇号编辑符(单撇号’或双撇号”)用来插入所需的字符串,如WRITE(*,’(1X,’I=’,I3,’J=’,I4)’) I,J。如果需要输出的字符包括单撇号,则用两个连续的单撇号代表一个被输出的撇号 (撇号编辑符为单撇号时)或用双撇号的编辑符,如WRITE(*,’(’I’ ’m a boy’)’)或WRITE(*,’(”I ’ma boy”)’)。
2、 H编辑符用来输出字符常量,其一般形式为:nH字符串。n为字符串中字符个数。它的作用与撇号编辑符相似。例如,上面用撇号编辑符的例子也可用H编辑符:WRITE(*,’(9HI ’m a boy)’)。用H编辑符必须准确地数出字符串中字符(包括符号,. ’)的个数,数错了就会造成错误。因此不建议使用H编辑符,而应该用A编辑符和撇号编辑符来输出字符串。F77之所以保留H编辑符主要是为了与F66兼容,但在F95中已被废除。
3、 X编辑符用来在输出时产生空格。没有空格的输出时数据是连成一片的,难以区分开,为此需要插入空格。它的一般形式为:nX,n为插入的空格数,如WRITE(*,’(1X,’I=’,I3,5X,’J=’,I4)’) I,J在数据I和字符串’J=’之间插入5个空格。注意第一项中的1X,在行式打印机上可作为纵向走纸控制符,但在输出到文件和屏幕时,按Visual Fortran的默认编译它仅仅为空一格。
4、 纵向控制符,在把格式记录中的信息传送到打印设备上(打印机或终端)时,格式说明中的第一个字符不被印出,这个字符作为纵向间隔控制标志,称为纵向控制符。它们的功能在下表中列出。
| 格式说明的首字符 | 纵向间隔控制功能 | 常用形式 |
| (空格) | 移到下一行开头 | 1X, ’ ’,1H |
| 0(数字0) | 移到下面第二行开头 | ’0’,1H0 |
| 1(数字1) | 移到下一页第一行开头 | ’1’,1H1 |
| +(加号) | 移到当前行开头 | ’+’,1H+ |
| 其它字符 | 移到下一行开头 | (非标准规定) |
要使这些功能在VisualFortran上实现,必须按以下步骤修改默认值:对于输出到终端的情形,在菜单选项中Project -> Setting -> Fortran-> Compatibility选取Enable VMS Compatibility项。对于输出到文件的情形,在打开文件的OPEN语句中加上说明项CARRIAGECONTROL='FORTRAN'。这时每行记录的第一个字符被当作控制符,可能产生输出的数字或字符被吃掉的情形。另外重叠印刷功能仅对于行式打印机有效,对于终端和文件的输出其效果是覆盖。
5、斜杠(/)编辑符的作用是结束记录在本行的输出并从下一行开始输出下一个记录。如果有两个连续的斜杠,相当于增加一个空行输出。如果在编辑符的最后出现斜杠,也是再输出一个空行。用n个连续的斜杠,可以达到输出n-1个空行的效果。如WRITE(*,’(I3,I4/I1,I2//3F8.2/)’) I,J,M,N,X,Y,Z 的输出第一行为I,J的值,第二行为M,N的值,第三行为空行,第四行是X,Y,Z的值,第五行为空行。
6、反斜杠(\)编辑符和美元($)编辑符的作用相同,都是在输出一个记录行后取消回车符。常用于输出字符串与输入数据显示于屏幕同一行的情形。
例:Write(*,’(”Please Enter Your Age =”,$)’)
Read(*,*) My_age
当屏幕上输出字符串PleaseEnter Your Age =后没有换行,My_age的数值可紧接在=号后输入。
7、位置编辑符(T,TL,TR)在用于输出时,指出将要输出到记录上的下一个字符的位置。它们的一般形式为:Tn,TLn,TRn。n是非零正整数。
T指明记录相对于左Tab端的位置,记录上的下一个字符输出第n个字符的位置上。对于行式打印输出,因为记录的第一个字符作为纵向控制符不被打印,所以Tn是定位在打印记录的第n-1个字符的位置上。在这个位置之前若没有字符输出,则填满空格。
TL用于输出时,指明把记录上的下一个字符输出到从当前位置向左移n个字符的位置上。如果左移已到记录的第一列,则不再向左移,即向左移至多回退到第一列。TR用于输出时,指明把记录上的下一个字符传输到从当前位置向右移n个字符的位置上。如WRITE(*,’(TR10,F6.2,TL16,F6.2)’) 4.25, -21.46语句的输出结果是-21.46 4.25。
8、冒号编辑符,当I/O列表中没有更多的数据顶时,冒号(:)编辑符使格式控制结束。此编辑将常常用于FORMAT语句中没有要输出的数据项时的输出结束。
9、P编辑符设置比例因子以改变小数点位置,它用于实数变量编辑描述符如F、E和G编辑符。其作用范围延续到下一个比例因子的设置处。它的一般形式是:kP。k是一有符号整数以指定小数点向左或向右移几位,k取值范围在-128至127之间。在每一个输入输出语句开始时,这个比例因子被初始化为O。输出时,正k向右移,负k向左移(输入时相反)。比例因子对下面格式编辑符的影响:在用F编辑符输出时,这个要输出的值在显示以前将乘以10k。在用E编辑符输出时,这个要输出的值的实数部分在显示以前将乘以10k,其指数部分减k。
例:Format Value Output
1PE12.3 -270.139 -2.701E+02
1P,E12.2 -270.139 -2.70E+02
-1PE12.2 -270.139 -0.03E+04
例:dimension a(6)
a=25.;write(*, "(' ',f8.2,2pf8.2,f8.2)") a
其输出是: 25.00 2500.00 2500.00
2500.00 2500.00 2500.00
10、SP,SS和S编辑符在数字输出字段中控制着任选加号(+)的打印。SP在其后所有正数值域的位置输出加号,SS为不输出加号,S重新储存SS使其后不输出加号。
1、 BN,BZ编辑符在数字输入字段中控制着空格的解释。 BN编辑符忽略数字输入字段中内嵌和后续空格,使格式控制器仅使用字段上的所有非空格字符,并使它们向右对齐。 BZ编辑符使结尾空格符和分散空格符为零,而开头空格符仍为零。
2、 Q编辑描述符返回当前输入记录中剩余的字符数。对应的I/O列表中的数据项必须是整型或逻辑型的。
下面贴两段格式与I/O列表的关系:
输出格式指定和I/O列表
在输出语句执行时,I/O列表中的每一项都和一个可重复编辑符联系(I/O列表中的复型数据需要两个编辑符),非重复编辑符不和I/O列表中的数据项联系。如果I/O列表包含一个或多个数据项,则在格式指定时至少有一个可重复编辑符。空的编辑指定()只能用在I/O列表没有数据项的情况。一条编辑指定为空的FORMAT()格式WRITE语句输出的是回车换行。
在格式输入输出过程中,格式控制器从左向右扫描格式数据项。下面列出了格式控制器可能碰到的具体情况及相应的解释:
1) 如果I/O列表中出现了可重复编辑符和相应的数据项,该数据项和编辑符是互相联系的,该数据项的输出会在编辑符的格式控制下执行。如果没有相应的数据项格式控制器将中止输出,即多余的编辑符无效。
2) 如果I/O列表中项数多于格式说明中的可重复编辑符个数,即WRITE语句中的输出项表列中还有末输出的元素,而格式说明中的编辑符已用完,则重新使用该格式说明,但从下一行开始产生一个新记录。
3) 如果在格式说明中包含有重复使用的编辑符组,则当格式说明用完后再重新使用时,只有最右面的一个编辑符组(包括其重复系数)和它右面的编辑符被重复使用。
4) 遇格式说明的右括号(即最后面一个括号)或斜杠“/”时,结束本记录的输出,但不意味停止全部输出。只要I/O列表中还有未输出的量,将重复使用格式说明或按斜杠右面的格式说明组织输出。右括号与斜杠的不同是:当扫描到右括号而列表中已无数据项时,输出即告结束。而斜杠只表示结束本行输出,即使此时已无输出变量要输出,输出并未停止,它会重新开始一个新记录,直到遇到右括号或非重复编辑符为止。
5) 如果出现冒号编辑符(中止格式控制)且I/O列表中没有其它项,则格式控制器将中止输入输出。
输入格式指定和I/O列表
一条编辑指定为空的FORMAT()格式READ语句将跳过相邻的下一个记录,除非输入输出设置成ADVANCE=’NO’,这时文件位置将保持不变。记录中的字符如果少于编辑符指定的长度,在右侧会填以空格,除非在OPEN语中指定PAD=’NO’。用户输入的空格的解释取决于空格编辑描符(BN或BZ)的作用或OPEN语句中的BLANK=选项。BN和BZ的优先级比BLANK=选项要高。
总结起来,输入输出的语句包括:
| 语句 | 功能 |
| ACCEPT | 输入数据,和格式化顺序READ语句类似 |
| BACKSPACE | 定位到文件上一个记录开始处 |
| CLOSE | 断开和一个单元(文件和设备)的连接 |
| DELETE | 从相关文件中删去一条记录 |
| ENDFILE | 写一个文件结束记录 |
| INQUIRE | 返回一个单元或外部文件的属性 |
| OPEN | 使一个单元号和一个文件或设备相连接 |
| | 向星号单元(屏幕)输出数据 |
| READ | 从一个文件向I/O列表中的项目输入数据 |
| REWIND | 重新定位于文件的开头 |
| REWRITE | 覆盖当前记录 |
| UNLOCK | 释放先前被READ语句锁定的相关或顺序文件中的一个记录 |
| WRITE | 从一个I/O列表中的项目向文件输出数据 |
后记
刚开始看fortran介绍时,它被描述为从语言这一层便支持并行,生成的代码要比c还快。而且工程计算还是应该使用fortran而非c。通过对fortran的大致了解,总体感觉对于向量或矩阵操作,fortran较c要占优。fortran语言比较严谨,语言模块分类也比较丰富,比如C的函数调用可以对应于fortran的子过程、函数,内部过程等。对于文件的操作的方式也很其全。最大的不足可能是编译器的支持并不充分(gcc4.5.2不支持一些fortran标准,而且还有一些bug);以及用户群太小(碰到问题在google上很难找到相应的答案。)
作为史上第一门高级编程语言,了解下fortran总归是有益的,虽然现实中能用到的机会可能不多。但是从其它语言,如perl中也能依稀看到fortran的影子。
当同事发现我在学习fortran时,说道:“你竟然看这么老的语言,涉猎真是广”。其实fortran也一直在与时俱进,在95后,还有03标准和08标准。作为高级语言的史祖,fortran绝对含有巨大的能量。让我联想到生化5里的始祖病毒,呵呵。“涉猎”一词还让我联想到盛大三国杀里的神吕蒙的配音(有点恶心)。














 7510
7510











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









