







一、Spark环境搭建
1.1 下载Spark
下载地址:http://spark.apache.org/downloads.html
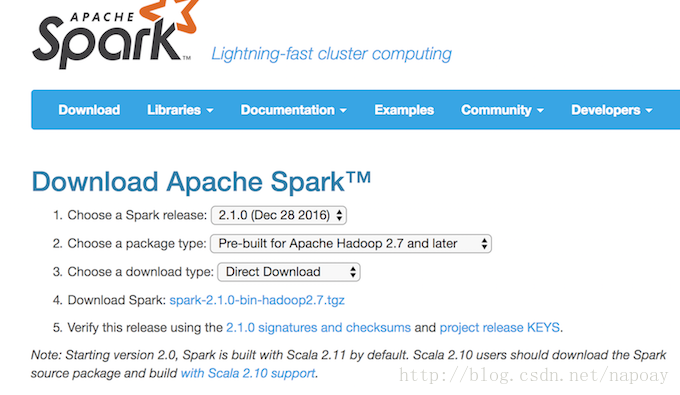
下载完成后解压即可。
把spark的运行目录加到环境变量:
#Spark Home
export SPARK_HOME=/usr/local/Cellar/spark-2.1.0-bin-hadoop2.7
export PATH=$PATH:$SPARK_HOME/bin我这里用的是简单的本地单机版,运行计算PI的例子进行测试:
run-example org.apache.spark.examples.SparkPi如果一切顺利,可以看到以下结果:
.......
17/10/11 10:59:06 INFO DAGScheduler: Job 0 finished: reduce at SparkPi.scala:38, took 0.895042 s
Pi is roughly 3.1441357206786034
.......二、下载安装Scala
下载地址:http://www.scala-lang.org/download/
解压缩、添加scala目录到环境变量:
#Scala Home
export SCALA_HOME=/usr/local/Cellar/scala-2.12.0
export PATH=$PATH:$SCALA_HOME/bin查看Scala版本信息:
scala -version
Scala code runner version 2.12.0 -- Copyright 2002-2016, LAMP/EPFL and Lightbend, Inc.三、Idea中安装Scala插件
打开Idea,config中找到Plugins:

搜索scala:
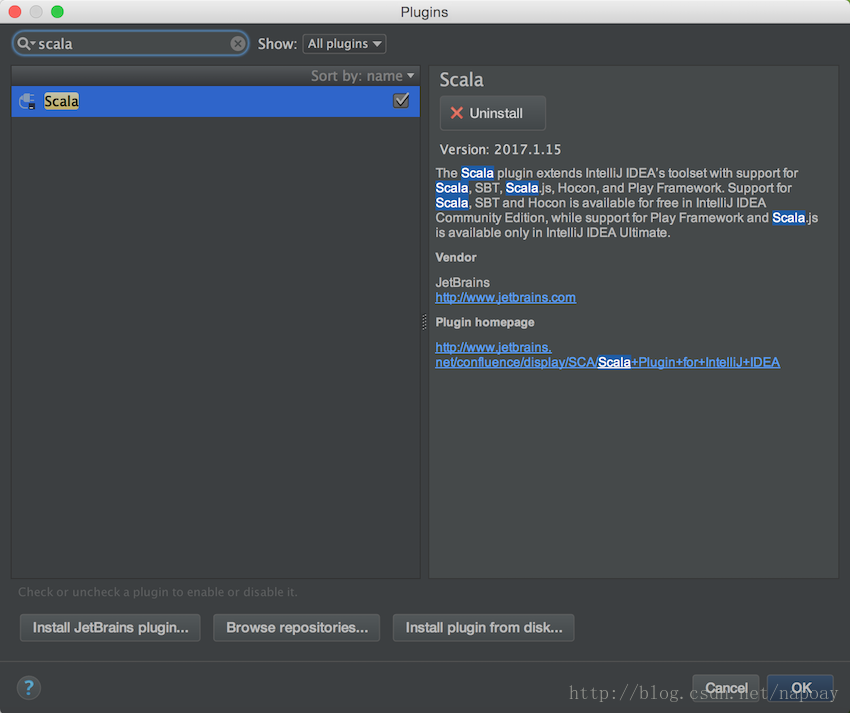
四、Idea中创建Sbt工程
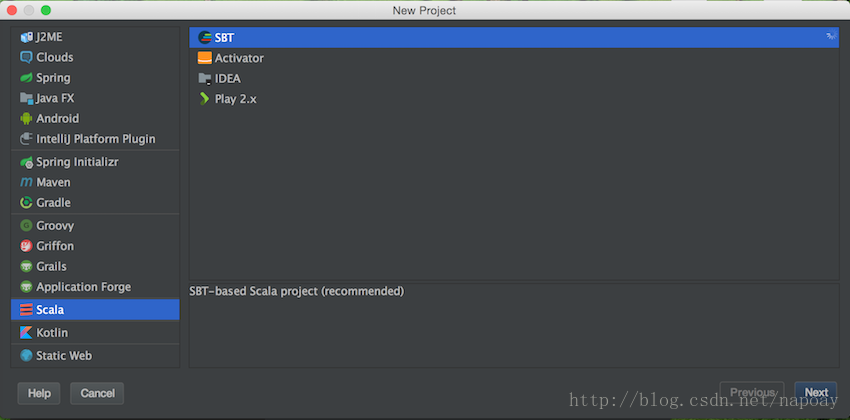
新建工程,选择SCALA->SBT:
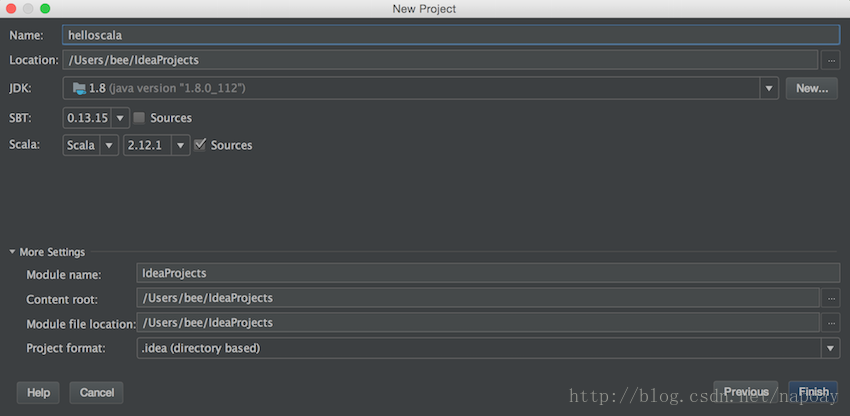
配置工程名称和路径:
新建Scala Class:
Kind选择Object,注意,这里不要选class.
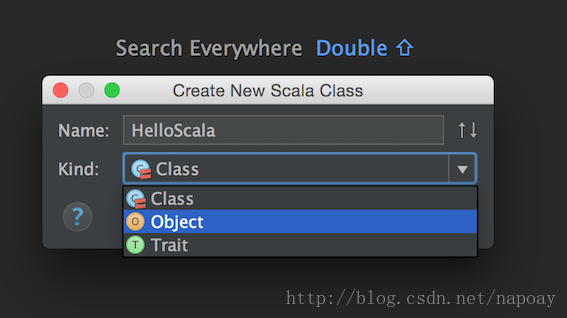
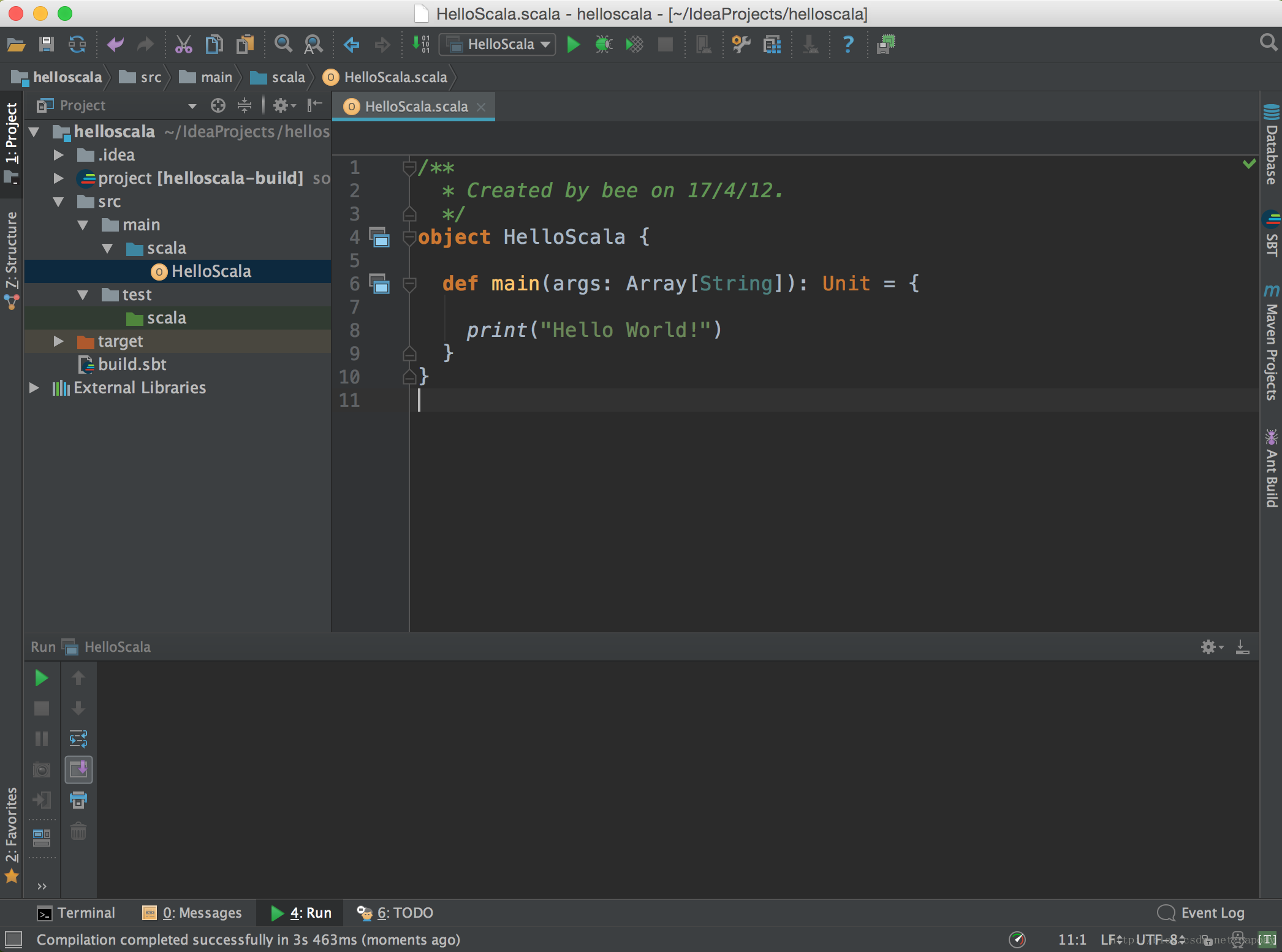
写个Hello World:
运行( 如果上面文件选择class,这里没有运行scala文件到命令):
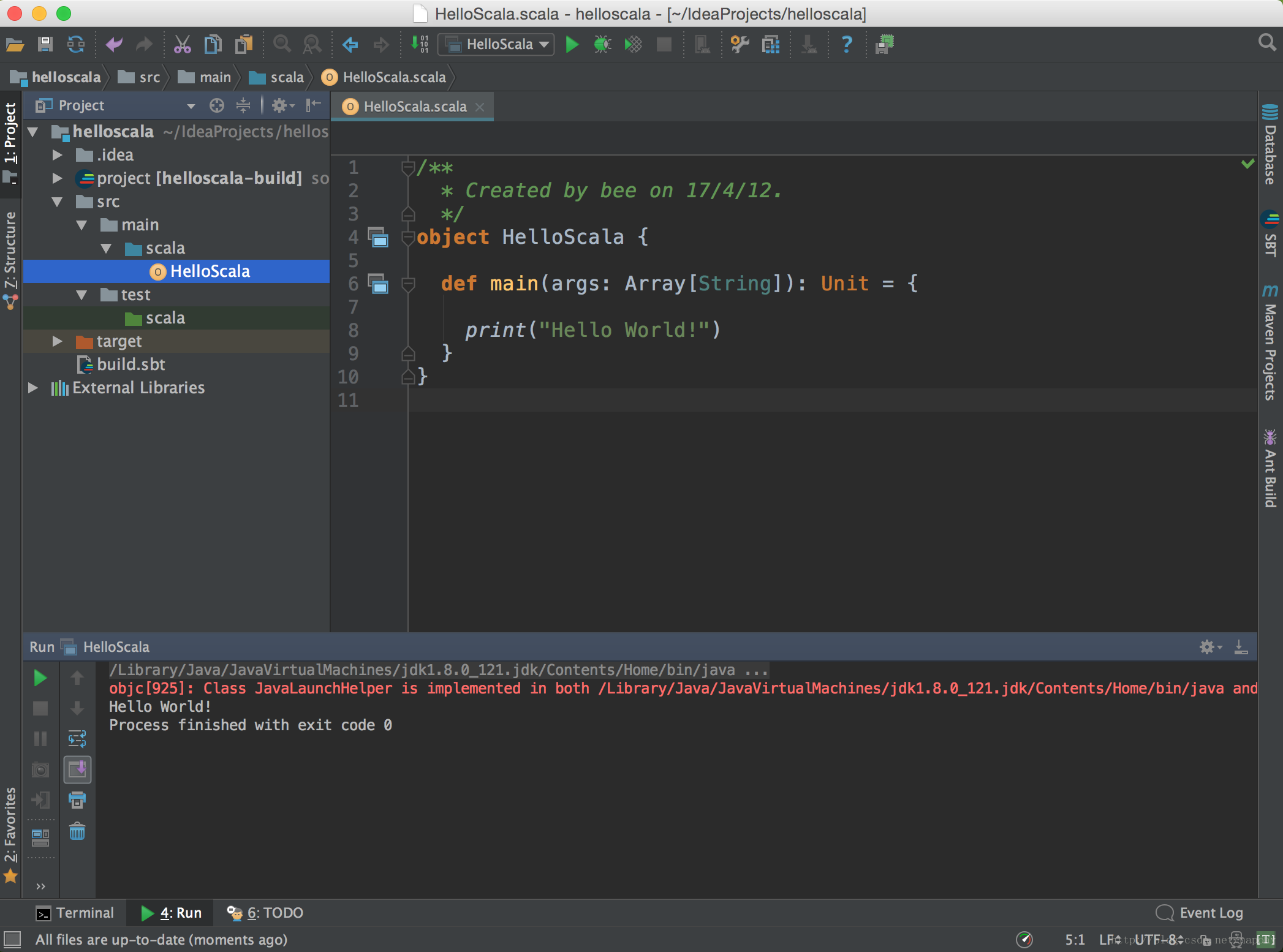
结果:
五、 Spark Maven工程
在maven工程中编写Spark程序,加入Spark的坐标:
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.10</artifactId>
<version>2.1.0</version>
</dependency>aven工程中要想支持Scala,需要配置Scala SDK。在IDEA中依次选择File-> project structure->Global Libraries,添加Scala SDK:
这里一定要注意Scala的版本。
六、使用Spark分析用户购物记录
下面的数据是用户购买商品的记录,数据列之间用逗号分割,依次为用户名、商品名、价格,把下面的数据保存到文件UserPurchaseHistory.csv中:
John,iPhone Cover,9.99
John,HeadPhones,5.49
Jack,iPhone Cover,9.99
Jill,Samsung Galaxy Cover,8.95
Bob,iPad Cover,5.49
Jack,iPad Cover,5.49新建一个scala文件:UserPurchaseApp.scala,编写代码:
package com.sprakmllib
import org.apache.spark.{SparkConf, SparkContext}
/**
* Created by bee on 17/10/10.
*/
object UserPurchaseApp {
def main(args: Array[String]): Unit = {
val sc = new SparkContext("local[1]", "first")
val user_data = sc.textFile("/Users/bee/Documents/spark/sparkmllib/UserPurchaseHistory.csv")
.map(line => line.split(","))
.map(purchaseRecord => (purchaseRecord(0), purchaseRecord(1), purchaseRecord(2)))
//购买次数
val numPurchase = user_data.count();
println("购买次数: "+numPurchase)
//购买商品的不同客户
val uniqueUsers = user_data.map { case (user, product, price) => user }.distinct().count()
println("购买商品的不同客户: "+uniqueUsers)
//总收入
val totalRevenue = user_data.map { case (user, product, price) => price.toDouble }.sum()
println("总收入: "+totalRevenue)
//统计最畅销的产品
val productsByPopularity=user_data.map{case(user,product,price)=>(product,1)}
.reduceByKey(_+_)
.collect()
.sortBy(-_._2)
val mostPopular=productsByPopularity(0)
println("统计最畅销的产品: "+mostPopular)
}
}
运行结果:
购买次数: 6
购买商品的不同客户: 4
总收入: 45.400000000000006
统计最畅销的产品: (iPad Cover,2)















 2767
2767

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











