







为了避免遗忘,先将前几天AC的代码贴一下,顺便写下解题报告。
题目如下:
最大连续子序列
Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 65536/32768 K (Java/Others)Total Submission(s): 17500 Accepted Submission(s): 7723
Problem Description
给定K个整数的序列{ N1, N2, ..., NK },其任意连续子序列可表示为{ Ni, Ni+1, ...,
Nj },其中 1 <= i <= j <= K。最大连续子序列是所有连续子序列中元素和最大的一个,
例如给定序列{ -2, 11, -4, 13, -5, -2 },其最大连续子序列为{ 11, -4, 13 },最大和
为20。
在今年的数据结构考卷中,要求编写程序得到最大和,现在增加一个要求,即还需要输出该
子序列的第一个和最后一个元素。
Nj },其中 1 <= i <= j <= K。最大连续子序列是所有连续子序列中元素和最大的一个,
例如给定序列{ -2, 11, -4, 13, -5, -2 },其最大连续子序列为{ 11, -4, 13 },最大和
为20。
在今年的数据结构考卷中,要求编写程序得到最大和,现在增加一个要求,即还需要输出该
子序列的第一个和最后一个元素。
Input
测试输入包含若干测试用例,每个测试用例占2行,第1行给出正整数K( < 10000 ),第2行给出K个整数,中间用空格分隔。当K为0时,输入结束,该用例不被处理。
Output
对每个测试用例,在1行里输出最大和、最大连续子序列的第一个和最后一个元
素,中间用空格分隔。如果最大连续子序列不唯一,则输出序号i和j最小的那个(如输入样例的第2、3组)。若所有K个元素都是负数,则定义其最大和为0,输出整个序列的首尾元素。
素,中间用空格分隔。如果最大连续子序列不唯一,则输出序号i和j最小的那个(如输入样例的第2、3组)。若所有K个元素都是负数,则定义其最大和为0,输出整个序列的首尾元素。
Sample Input
6 -2 11 -4 13 -5 -2 10 -10 1 2 3 4 -5 -23 3 7 -21 6 5 -8 3 2 5 0 1 10 3 -1 -5 -2 3 -1 0 -2 0
Sample Output
20 11 13 10 1 4 10 3 5 10 10 10 0 -1 -2 0 0 0Huge input, scanf is recommended.HintHint
这题的第一思路是上三角矩阵,枚举任意一个子段的和。如下:
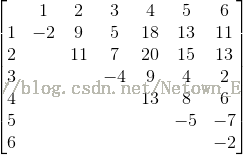
但是这样显然是不行的,首先是比较占内存,因此我做了下面改进,用一维数组来存结果。
代码如下:
#include <iostream>
#define Max 10000
using namespace std;
int main()
{
int item[Max];
int table[Max];
int k;
while(cin>>k && k)
{
int i, j;
int down = 1, up = k;
int sum = -1;
for(i = 1; i <= k ; i++)
{
int x;
cin>> x;
item[i] = x;
table[i] = x;
for( j = 1 ; j <= i ; j++)
{
if( i != j )
{
item[j] = item[j]+item[i];
}
if( item[j] >= 0 && item[j] > sum )
{
sum = item[j];
down = j;
up = i;
}
}
}
if( sum < 0 ) cout<<"0"<<" "<<table[down]<<" "<<table[up]<<endl;
else cout<<sum<<" "<<table[down]<<" "<<table[up]<<endl;
}
}算法每输入一个元素,都将该元素依次加到该元素之前的数值上,同时用三个变量记录最大值及始终点。
算法执行过程中,数组item的变化如下:
第一遍是:-2
第二遍是: 9, 11
第三遍是: 5, 7, -4
第四遍是:18, 20, 7, 13
……
形成的结果是上面的上三角矩阵的转置。
从这个角度上来说,这个算法并没有提高效率,只不过节省了空间。
TLE是很自然的。(算法的复杂度依然是O(n^2))
后来参考别人的思路,发现算法可以在O(n)的时间复杂度内结束。
以下是源码:
#include <iostream>
#define Max 10000
using namespace std;
int main()
{
int item[Max];
int k;
while(cin>>k && k)
{
int i, j;
bool flag = false;
for(i = 1; i <= k ; i++)
{
int x;
cin>> x;
if( x>=0 ) flag = true; //记录是否全为负数
item[i] = x;
}
if(flag)
{
int max = item[1];
int sum = item[1];
int down = 1, up = 1;
int tmp;
for( j = 2 ; j <= k ; j++)
{
if( sum < 0 )
{
sum = 0 ;
tmp = j;
}
sum += item[j];
if( sum > max )
{
max = sum;
up = j;
down = tmp;
}
}
cout<<max<<" "<<item[down]<<" "<<item[up]<<endl;
}
else cout<<"0"<<" "<<item[1]<<" "<<item[k]<<endl;
}
return 0;
}

上图中被黑色矩形框选中的表示sum值的走向。
可以看出,该算法并没有计算所有的和,只计算了一行值就找到了最大子段和,效率是很高的。
用下面更明显的例子,可以看出:
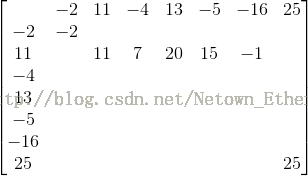
算法之所以能从第一行跳到第二行,从第二行跳到第七行,
直接省略掉其他行及一行剩余的元素,归功于以下代码
if( sum < 0 )
{
sum = 0 ;
tmp = j;
}
首先可以看出,sum的起始点对应的元素一定是正数。
这很显然,因为假如 是负数,
是正数,那么没有理由从
开始的子段和大于从
开始的子段和。
其次,如果 ,那么一定有
, 因为
是正数。
由此可以推知, 对于 , 如果
,
那么一定有
。
所以,从 到
这之间的所有子段和都不必计算了,直接从
从新开始计算即可,算法的效率由此得到极大的提高。

















 3426
3426

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









