







1.背景
测试人员在设计性能测试脚本时,HTTP请求中的参数往往根据个人经验设置,而测试人员水平参差不齐,设计往往具有局限性,不够全面,不能涵盖全线上真实的请求,故得到的性能测试结果不能够真实反映线上真实的情况。
使用线上环境下的HTTP请求检查软件性能的问题,通过Gor记录线上真实的请求,作为性能测试脚本的请求池,用请求池物料进行性能测试,能真实的反映软件系统在线上环境下的性能指标和问题。
2.概念
2-1.架构图
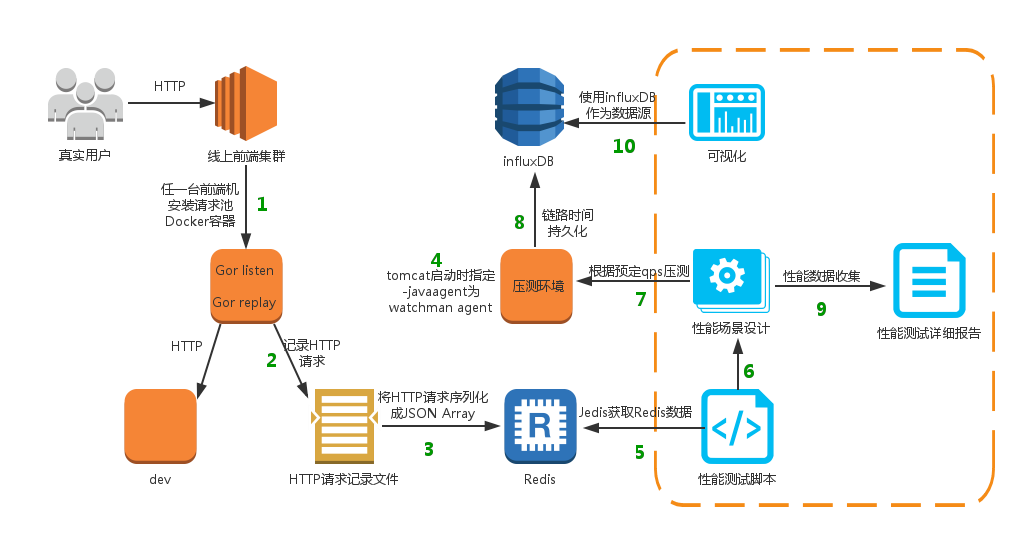
2-2.技术栈
请求池:
Gor:
HTTP 录制工具 https://github.com/buger/gor
Webdis:
A very simple web server providing an HTTP interface to Redis https://github.com/nicolasff/webdis
redis:
持久化缓存
性能测试工具:
nGrinder二次开发:
http://blog.csdn.net/neven7/article/details/50740018
Spring MVC
链路可视化:
watchman(微博APM)
influxDB:
时序化DB https://github.com/influxdata/influxdb
Grafana:
可视化工具 https://github.com/grafana/grafana
3.实现
3-1.请求池
使用Gor录制线上请求,根据线上请求,序列化成Json String, 持久化到redis;性能测试脚本根据key,获取到线上请求数据,进行压测。
为了方便部署请求池,将请求池docker化,使用如下命名,启动docker容器:
docker run -i -t --net=host gor-request-parser /bin/bash
开始录制线上数据:
sh gor_request_parser.sh 8080 60 GET your_api_name NONBASIC ip port
参数介绍:
8080:监听端口
60:监听时间(秒)
GET:HTTP METHOD
your_api_name:过滤其他url,只保留your_api_name请求
NONBASIC:非BASIC认证接口,参数BASIC为BASIC接口
ip port:webdis服务
60s后, 请求数据持久化到redis中
***************************************************
gor http请求 序列化
http请求记录中,60 秒后,终止记录
***************************************************
Version:
***************************************************
记录结束, http请求序列化到请求池
@author hugang
***************************************************
redis的key为$date_$hostname_$url
value为Json Array,形如:

3-2.性能测试脚本
性能测试工具使用nGrinder,进行二次开发,请参考:http://blog.csdn.net/neven7/article/details/50740018;
性能测试脚本使用redis获取线上请求数据,依赖jedis、fastJson,在脚本lib中导入这2个jar包。
范例:
package org.ngrinder;
import static net.grinder.script.Grinder.grinder
import static org.junit.Assert.*
import static org.hamcrest.Matchers.*
import net.grinder.plugin.http.HTTPRequest
import net.grinder.plugin.http.HTTPPluginControl;
import net.grinder.script.GTest
import net.grinder.script.Grinder
import net.grinder.scriptengine.groovy.junit.GrinderRunner
import net.grinder.scriptengine.groovy.junit.annotation.BeforeProcess
import net.grinder.scriptengine.groovy.junit.annotation.BeforeThread
// import static net.grinder.util.GrinderUtils.* // You can use this if you're using nGrinder after 3.2.3
import org.junit.Before
import org.junit.BeforeClass
import org.junit.Test
import org.junit.runner.RunWith
import HTTPClient.HTTPResponse
import HTTPClient.NVPair
import java.util.ArrayList;
import java.util.Collections;
import java.util.List;
import groovy.json.JsonBuilder
import groovy.json.JsonSlurper
import com.alibaba.fastjson.JSONArray;
import redis.clients.jedis.Jedis;
/**
* A simple example using the HTTP plugin that shows the retrieval of a
* single page via HTTP.
*
* This script is automatically generated by ngrinder.
*
* @author hugang
*/
@RunWith(GrinderRunner)
class TestRunner {
public static GTest test
public static HTTPRequest request
public static File file
public static JSONArray jsonArray
@BeforeProcess
public static void beforeProcess() {
HTTPPluginControl.getConnectionDefaults().timeout = 6000
test = new GTest(1, "压测ip")
request = new HTTPRequest()
test.record(request);
// 读取请求池数据
Jedis jedis = new Jedis("redis ip", redis port);
// redis key
String key = "your key";
String jsonStr = jedis.get(key);
jsonArray = JSONArray.parseArray(jsonStr);
// grinder.logger.info(jsonArray.getString(0));
// grinder.logger.info("before process.");
}
@BeforeThread
public void beforeThread() {
grinder.statistics.delayReports=true;
}
@Test
public void test(){
// 随机获取
int index = (int) (Math.random() * jsonArray.size());
String httpInfo = jsonArray.getString(index);
def json = new JsonSlurper().parseText(httpInfo)
String api = json.api
Map param = json.param
def nvs = []
param.each{
key, value -> nvs.add(new NVPair(key, value))
}
// GET请求,wiki http://grinder.sourceforge.net/g3/script-javadoc/net/grinder/plugin/http/HTTPRequest.html
// param1: uri, param2: queryData
// HTTPResponse GET(java.lang.String uri, NVPair[] queryData) Makes an HTTP GET request.
HTTPResponse result = request.GET("http://压测ip" + api, nvs as NVPair[])
if (result.statusCode == 301 || result.statusCode == 302) {
grinder.logger.warn("Warning. The response may not be correct. The response code was {}.", result.statusCode);
} else {
assertThat(result.statusCode, is(200));
// 请求返回的数据
// println(result.text);
// 定义一个事务,接口返回数据校验,是否包含
assertThat(result.text, containsString("\"code\""));
}
}
}
3-3. 链路时间分布可视化
链路时间展示,启动web服务指定-javaagent为watchman agent,使用字节码增强,获取某一段时间内代码链路的分布时间。
请参考:http://blog.csdn.net/neven7/article/details/50980726















 1201
1201

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









