









 本文介绍了sed和awk这两种强大的文本处理工具的基本用法和高级应用技巧。sed是一种流式编辑器,可以用来过滤和修改文本文件。awk则擅长处理结构化的数据,能够方便地解析和操作字段。文中通过具体的例子展示了如何利用这两种工具来实现复杂的文本处理任务。
本文介绍了sed和awk这两种强大的文本处理工具的基本用法和高级应用技巧。sed是一种流式编辑器,可以用来过滤和修改文本文件。awk则擅长处理结构化的数据,能够方便地解析和操作字段。文中通过具体的例子展示了如何利用这两种工具来实现复杂的文本处理任务。
(一)sed
sed是一个精简的、非交互式的流式编辑器,它在命令行中输入编辑命令和指定文件名,然后在屏幕上查看输出。
逐行读取文件内容存储在临时缓冲区中,称为“模式空间”(pattern space),接着用sed命令处理缓冲区的内容,处理完成后,把缓冲区的内容送往屏幕。接着处理下一行,这样不断重复,直到文件末尾。原文件爱你的内容并没有改变。
sed '4,$d' test.in # 删除4~最后一行
sed '3q' test.in # 读到指定行之后退出
sed 's/public/PUBLIC/' test.in # 替换public为PUBLIC
sed -n 's/public/PUBLIC/p' test.in #打印匹配行
-e 连接多个编辑命令
-f 指定sed脚本文件名
-n 阻止输入行自动输出
通常grep也能达到效果,例如统计指定文件中的行数
COUNT=$(cat $FILE | grep -a "关键字" | wc -l)
指定多个命令的三种方法:
1.用分号分隔命令
sed 's/public/PUBLIC/;s/north/NORTH/' test.insed -e 's/public/PUBLIC' -e 's/north/NORTH' test.insed '
> s/public/PUBLIC/
> s/northNORTH' test.in

常见的编辑命令:
p: 打印匹配行
sed -n '3,5p' test,in
=: 显示匹配行的行号
sed -n '/north/=' test.in
d: 删除匹配的行
sed -n '/north/d' test.in
a\: 在指定行之后追加一行或者多行文本,并显示添加的新内容。
sed '/north/a\AAA\
>BBB\
>CCC' test.in
i\: 在指定行之前插入一行或者多行文本,并显示新内容,同上。
c\: 用新文本替换指定的行,使用格式同上
l : 显示指定行中的所有字符,包括控制字符(非打印字符)
sed -n '/north/l' test.in
s:替换命令,使用格式为
[address] s/old/new/[gpw]
address:如果省略,表示编辑所有的行
g: 全局替换
p: 打印被修改后的行
w fname: 将被替换后的内容写到指定的文件中
sed -n 's/north/NORTH/gp' test.in
sed -n 's/north/NORTH/w data' test.in
sed 's/[0-9][0-9]$/&.5/' datafile
&符号用在替换字符串中时,代表被替换的字符串
r: 读文件,将另外一个文件中的内容附加到指定行后
sed '$r data' test.in
w: 写文件,将指定行写入到另外一个文件中
sed -n '/public/w date2' test.in
n: 将指定行的下面一行读入编辑缓冲区
sed -n '/public/{n;s/north/NORTH/p}' test.in
对指定行同时使用多个sed编辑命令时,需用大括号括起来,命令之间用分号;隔开。
q:退出,读取到指定行之后退出sed
sed '3q' test.in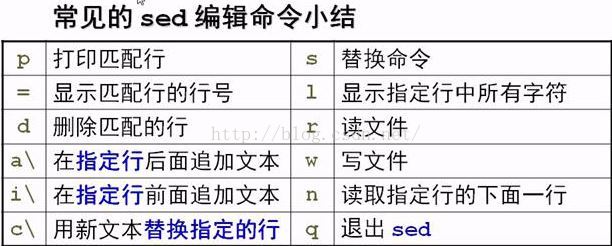
(二)awk
awk可以对列进行处理
简单用法:
awk [options] sed_script files
-F 指定输入记录字段的分隔符,默认环境变量IFS的值
-f 从指定文件读取awk_script
-v 为awk设定变量
awk -F:'{print $1}' /etc/passwd
awk -F:'/root{print $1 "|" $3}' /etc/passwd
awk的执行过程:
1. 如果存在BEGIN,awk首先执行他指定的actions
2. awk从输入中读取一行,称为一条消息记录
3. awk将读入的记录分割成数个字段,并将第一个字段放入变量$1中,第二个放入变量$2中,依次类推;$0表示整条记录;字段分隔符可以通过选项-F指定,否则使用缺省的分隔符。
4. 把当前输入记录依次与每一个awk_cmd中的pattern比较:
如果相匹配,就执行对应的actions
如果不匹配,就跳过对应的actions,直到完成所有的awk_cmd
5. 当一条输入记录记录完毕后,awk读取输入的下一行,重复上面的处理过程,直到所有输入全部处理完毕。
6. awk处理完所有的输入后,若存在END,执行相应的actions
7. 如果输入是文件列表,awk将按顺序处理列表中的每个文件
awk处理的例子:
ifconfig | awk '/inet addr/{ print $2 }'| awk -F:'{ print $2 }'
ifconfig | awk '/inet addr/{ print $2 }'|awk -F: 'BEGIN { print "begin..."}'{ print $2 } END { print "end..." }'
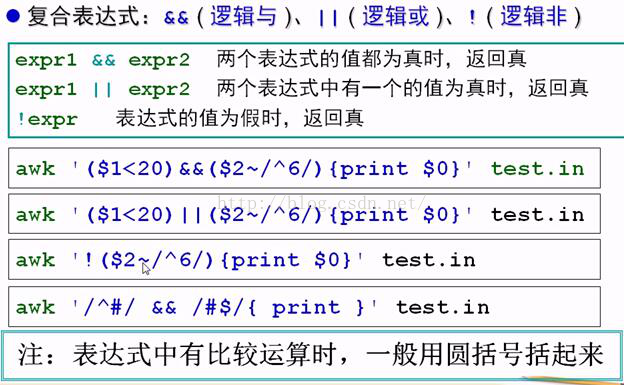
最后,awk不仅是一个命令,它更是一个编程语言
变量:
1. 内部变量 awk '{print NR,$0}' #给文件加上行号
2.自定义变量
函数:
1.内置函数
2.自定义函数
awk '{print sum($1,$2)} function sum(x,y){s=x+y;return s}' grade.txt
数组
awk 'BEGIN {print split("123#456",arr,"#");for(i in arr){print arr[i]}}'
由于这些比较复杂,本文不再展开介绍。
最后附上几个简单的shell脚本,更多的实例在我的Github上。
(1)比较大小
#!/bin/bash
echo "please input the two numbers:"
read a
read b
if (($a==$b));then
echo "a = b"
elif (($a>$b));then
echo "a > b"
else
echo "a < b"
fi
#!/bin/bash
echo "Enter a file name :"
read a
if [ -e /home/tach/$a ];then
echo "the file is exist!"
else
echo "the file is not exist!"
fi
#!/bin/bash
for filename in `ls`
do
a=$(ls -l $filename | awk '{print $5}')
if ((a==0));then
rm $filename
fi
done
(4)查看本机IP地址
#!/bin/bash
ifconfig | grep "inet 地址:" | awk '{print $2}' | sed 's/地址:'//g(5)IP地址合法性判断
#!/bin/bash
CheckIPAddr()
{
#IP地址需由三个.分隔且均是数字
echo $1 | grep "^[0-9]\{1,3\}\.\([0-9]\{1,3\}\.\)\{2\}[0-9]\{1,3\}$" > /dev/null
if [ $? -ne 0 ];then
return 1
fi
ipaddr=$1
a=`echo $ipaddr | awk -F. '{print $1}'`
b=`echo $ipaddr | awk -F. '{print $2}'`
c=`echo $ipaddr | awk -F. '{print $3}'`
d=`echo $ipaddr | awk -F. '{print $4}'`
for num in $a $b $c $d
do
if [ $num -gt 255 -o $num -lt 0 ];then
return 1
fi
done
return 0
}
if [ $# -ne 1 ];then
echo "Usage :$0 ipaddr."
exit
else
CheckIPAddr $1
ans=$?
if [ $ans -eq 0 ];then
echo "legal ip address."
else
echo "unlegal ip address."
fi
fi
(6)其他
#!/bin/bash
#显示当前日期和时间
echo `date +%Y-%m-%d-%H:%M:%S`
#查看哪个IP地址连接的最多
netstat -an | grep ESTABLISHED | awk '{print $5}'|awk -F: '{print $1}' | sort | uniq -c
#awk不排序删除重复行
awk '!x[$0]++' filename
#x只是一个数据参数的名字,是一个map,做指定的逻辑判断,如果逻辑判断成立,则执行指定的命令;不成立,直接跳过这一行
#查看最常使用的10个unix命令
awk '{print $1}' ~/.bash_history | sort | uniq -c | sort -rn | head -n 10
#sort中的-r是降序,_-n是按照数值排序(默认比较字符,10<2)
#逆序查看文件
cat 1.txt | awk '{a[i++]=$0} END {for (j=i-1; j>=0;) print a[j--] }'
#查看第3到6行
awk 'NR >=3 && NR <=6' filename
#crontab文件的一些示例
30 21 * * * /usr/local/etc/rc.d/lighttpd restart #每晚9.30重启apache
45 4 1,10,22 * * /usr/local/etc/rc.d/lighttpd restart #每月的1,10,22日的4:45重启apache
10 1 * * 6,0 /usr/local/etc/rc.d/lighttpd restart #每周六、日的1:10重启apache
0,30 18-23 * * * /usr/local/etc/rc.d/lighttpd restart #表示在每天18.00至23.00之间每隔30分钟重启apache
* 23-7/1 * * * /usr/local/etc/rc.d/lighttpd restart #晚上11点到早上7点之间,每隔一小时重启apache


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









