




 本文深入探讨了Spark SQL Catalyst中的TreeNode库,包括BinaryNode、UnaryNode和Leaf Node三种类型,详细阐述了TreeNode的核心方法transform及其作用。通过具体实例展示了从UnResolved Logical Plan到Analyzed Logical Plan,再到Optimized Plan和executedPlan的转换过程,帮助读者理解Optimizer如何生成优化的执行计划。
本文深入探讨了Spark SQL Catalyst中的TreeNode库,包括BinaryNode、UnaryNode和Leaf Node三种类型,详细阐述了TreeNode的核心方法transform及其作用。通过具体实例展示了从UnResolved Logical Plan到Analyzed Logical Plan,再到Optimized Plan和executedPlan的转换过程,帮助读者理解Optimizer如何生成优化的执行计划。
/** Spark SQL源码分析系列文章*/
前几篇文章介绍了Spark SQL的Catalyst的核心运行流程、SqlParser,和Analyzer,本来打算直接写Optimizer的,但是发现忘记介绍TreeNode这个Catalyst的核心概念,介绍这个可以更好的理解Optimizer是如何对Analyzed Logical Plan进行优化的生成Optimized Logical Plan,本文就将TreeNode基本架构进行解释。
一、TreeNode类型
TreeNode Library是Catalyst的核心类库,语法树的构建都是由一个个TreeNode组成。TreeNode本身是一个BaseType <: TreeNode[BaseType] 的类型,并且实现了Product这个trait,这样可以存放异构的元素了。TreeNode有三种形态: BinaryNode、 UnaryNode、 Leaf Node.
在Catalyst里,这些Node都是继承自Logical Plan,可以说每一个TreeNode节点就是一个Logical Plan(包含Expression)(直接继承自TreeNode)
主要继承关系类图如下:
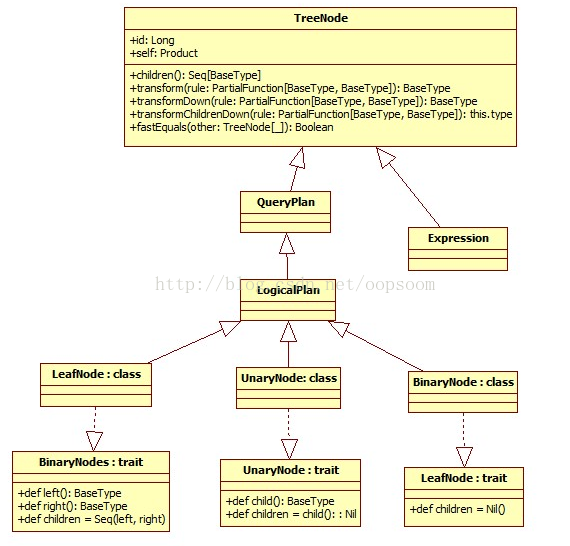
1、BinaryNode
二元节点,即有左右孩子的二叉节点
[[TreeNode]] that has two children, [[left]] and [[right]].
trait BinaryNode[BaseType <: TreeNode[BaseType]] {
def left: BaseType
def right: BaseType
def children = Seq(left, right)
}
abstract class BinaryNode extends LogicalPlan with trees.BinaryNode[LogicalPlan] {
self: Product =>
}下面列出主要继承二元节点的类,可以当查询手册用 :)
这里提示下平常常用的二元节点:Join和Union

2、UnaryNode
一元节点,即只有一个孩子节点
A [[TreeNode]] with a single [[child]].
trait UnaryNode[BaseType <: TreeNode[BaseType]] {
def child: BaseType
def children = child :: Nil
}
abstract class UnaryNode extends LogicalPlan with trees.UnaryNode[LogicalPlan] {
self: Product =>
}常用的二元节点有,Project,Subquery,Filter,Limit ...等
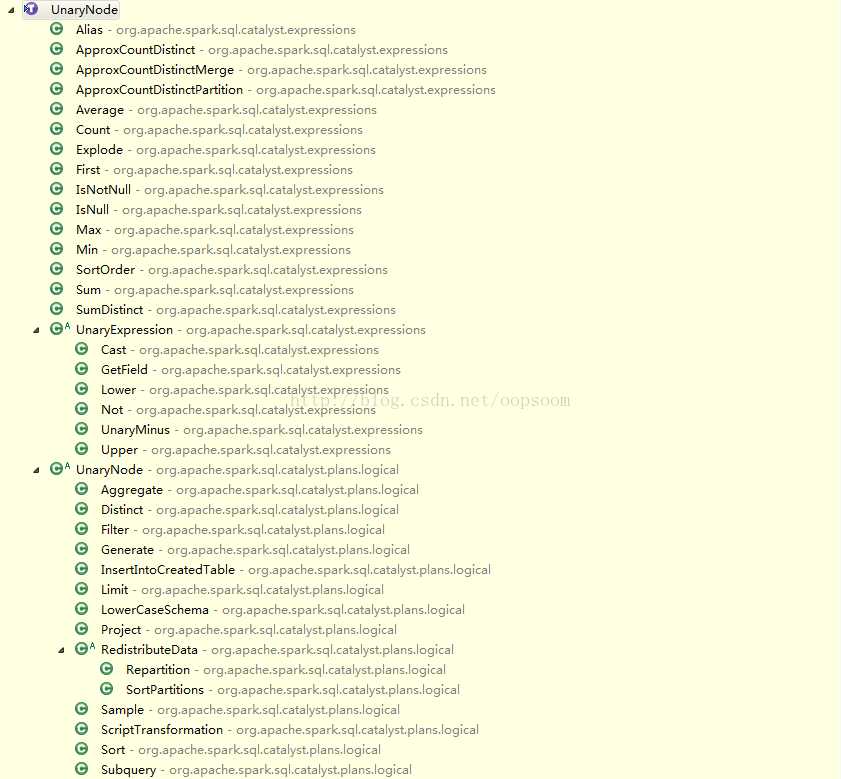
3、Leaf Node
叶子节点,没有孩子节点的节点。
A [[TreeNode]] with no children.
trait LeafNode[BaseType <: TreeNode[BaseType]] {
def children = Nil
}
abstrac 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 3166
3166

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









